9.1. Hot node pools
To view and manage node pools you need to have ROLE_ADMIN role.
For some jobs, a waiting for a node launch can be too long. It is convenient to have some scope of the running nodes in the background that will be always or on schedule be available.
Cloud Pipeline allows controlling the number of persistent compute nodes in the cluster - i.e. a certain number (cluster.min.size) of the nodes of a specified size (cluster.instance.type/cluster.instance.hdd) will be always available in the cluster (even if there is no workload) - see details about System Preferences could be applied for the cluster here.
This is useful to speed up the compute instances creation process (as the nodes are already up and running).
But this mechanism can be expanded and be a bit more flexible by another platform ability - it is the ability to create "hot node pools".
Overview
Admin can create and manage node pools:
- each pool contains one or several identical nodes - admin specifies the node configuration (instance type, disk, Cloud Region, etc.) and a corresponding number of such nodes. This count can be fixed or flexible ("autoscaled")
- each pool has the schedule of these nodes creation/termination. E.g. the majority of the new compute jobs are started during the workday, so no need to keep these persistent instances over the weekends. For the pool, several schedules can be specified
- for each pool can be configured additional filters - to restrict its usage by the specific users/groups or for the specific pipelines/tools etc.
When the pool is created, corresponding nodes are being up (according to pool's schedule(s)) and waiting in background. If the user starts a job in this time and the instance requested for a job matches to the pool's node - such running node from the pool is automatically being assigned to the job.
Note: pools management is available only for admins. Usage of pool nodes is available for any user.
Node pools management
For the node pools management a new tab is implemented in the Cluster State section - HOT NODE POOLS tab:
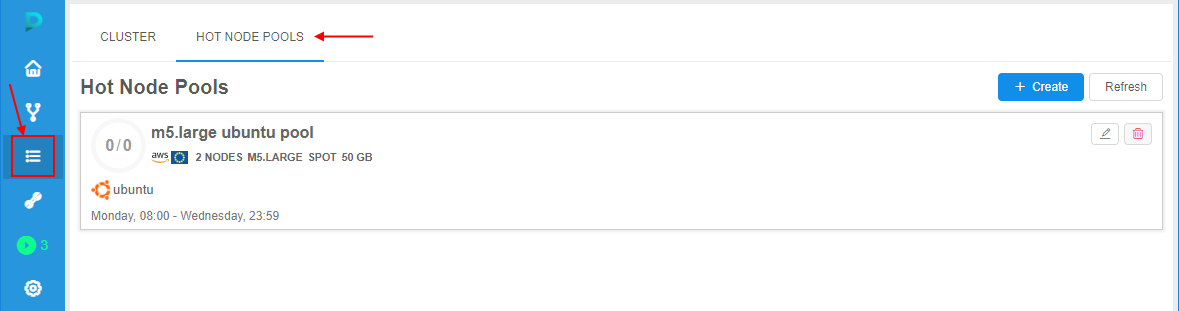
Pool creation
To create a new pool:
- At the HOT NODE POOLS tab, click the "+ Create" button.
- The pop-up appears:
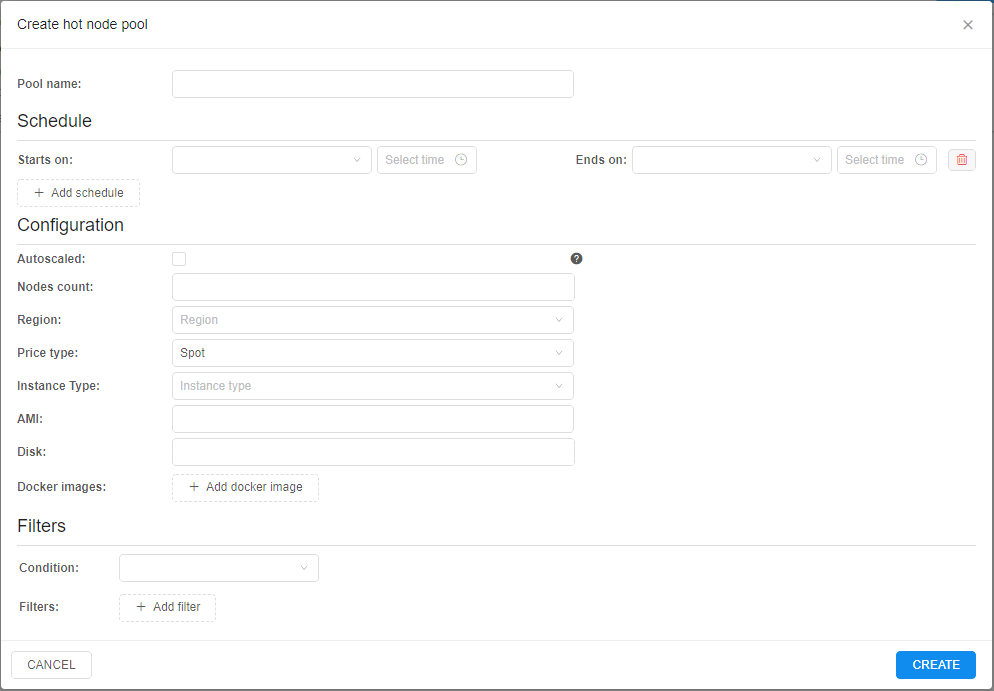
- Specify the pool name
- Specify the pool schedule - weekly time period during which the pool nodes will be up (running and waiting for the jobs):
- specify the day of the week and the time of the day for the beginning of the period, e.g.:
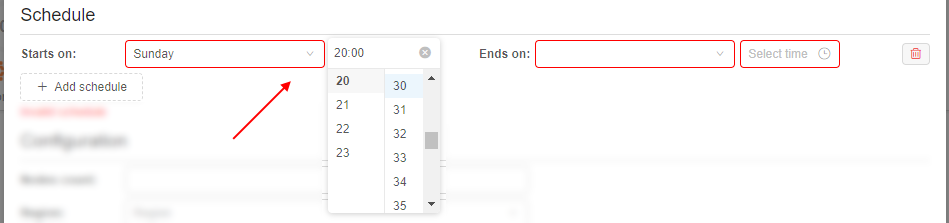
- specify the day of the week and the time of the day for the finish of the period, e.g.:
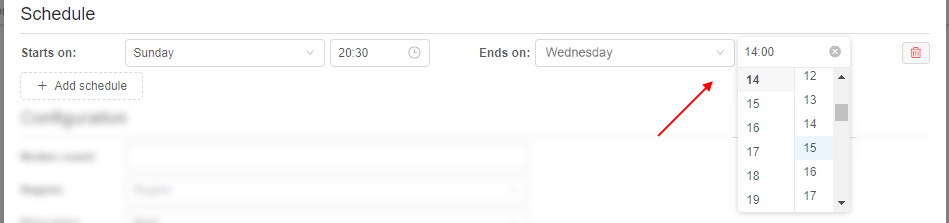
- if you wish, you can add several schedule periods for the pool. For that, click the "+ Add schedule" button and repeats actions described above for a new period:

- remove the unnecessary schedule you can by the corresponding button
 next to the schedule
next to the schedule
Note: the pool shall have at least one schedule
- specify the day of the week and the time of the day for the beginning of the period, e.g.:
- Specify the pool nodes count, e.g.:

It is the number of nodes in the creating pool (nodes count that will be run according to the schedule and wait for jobs).
Also you can set the checkbox Autoscaled - it allows to create instance pools with non-static size. In such case, the node pool size will be automatically adjust according to current cluster workload: increase pool size if most of its instances are assigned to active runs and decrease pool size if most of its instances are idle: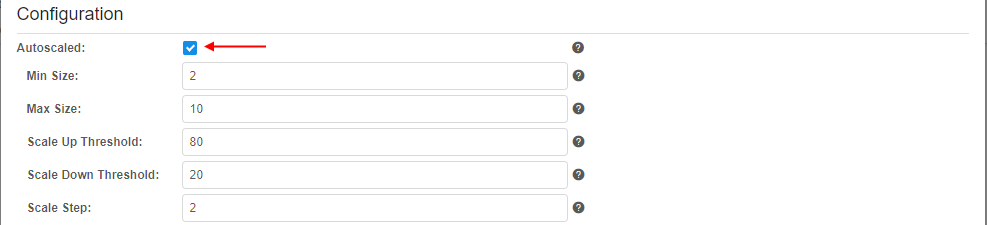
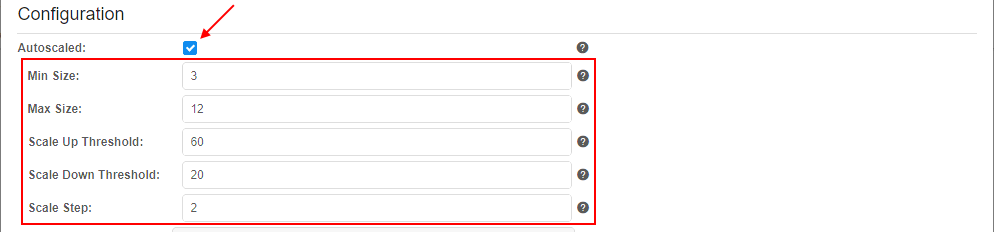
In case of Autoscaled node pool, additional fields appear:- Min Size - pool size cannot be decreased below this value. This count of nodes will be always run in cluster (according to the schedule(s))
- Max Size - pool size cannot be increased above this value
- Scale Up Threshold - sets the threshold in percent. If percent of occupied instances of the pool is higher than this value, pool size shall be increased
- Scale Down Threshold - sets the threshold in percent. If percent of occupied instances of the pool is lower than this value, pool size shall be decreased
- Scale Step - pool size shall be decreased/increased with this step
- Specify the Cloud Provider/Region from where the pool nodes will be run:

- Specify the price type for the pool nodes (Spot by default):

- Specify the instance type that will be used for the pool nodes:
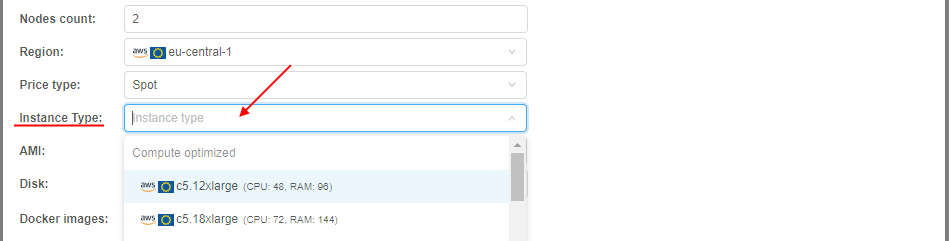
- If you wish, you may specify the AMI that will be used for the pool nodes. It is non-required. Without specifying - the default deployment AMI will be used.
- Specify the disk size (in
Gb) for the pool nodes, e.g.:
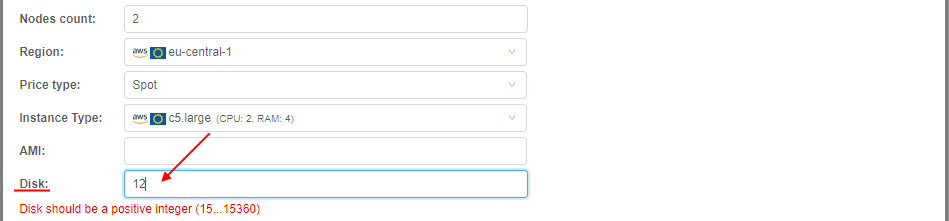
Note: the pool node will be assign to the job only if user request for a job a smaller disk than pool node has. Also note that the real disk size used for a job differs upwards from the user request - both these notes should be considered. E.g. if user requests 30 GB disk, real node disk may be 40 GB. Then if the pool node has disk setting 35 GB - it will not be assigned to the user job (as the real disk size 40 GB is more than the pool node disk size 35 GB). But if the pool node has disk setting 45 GB - it will be assigned normally to the user job. So, the pool disk should be set with a margin - of course, if the admin knows the disk size usually requested by the user.
On the other hand, the pool node disk size can be purposely set as a large volume. In that case, it would be inefficient to use such pool nodes for user "small" requests. For resolve that issue, the certain system preference is implemented -cluster.reassign.disk.delta- this delta sets the max possible difference that could be between the pool node disk size and the real disk size requested by the user for a job. E.g. if the real disk size requested by the user is 100 GB, the pool node has disk setting 500 GB andcluster.reassign.disk.deltais set 300 GB - the pool node will not be assigned to the such user requested job (as the difference is more than delta). But if the real disk size requested by the user is 250 GB - the pool node will be assigned to the such requested job. - Specify Docker image(s) that should be pre-uploaded to the pool nodes:
- click the "+ Add docker image" button:

- select the image in the appeared dropdown list, e.g.:
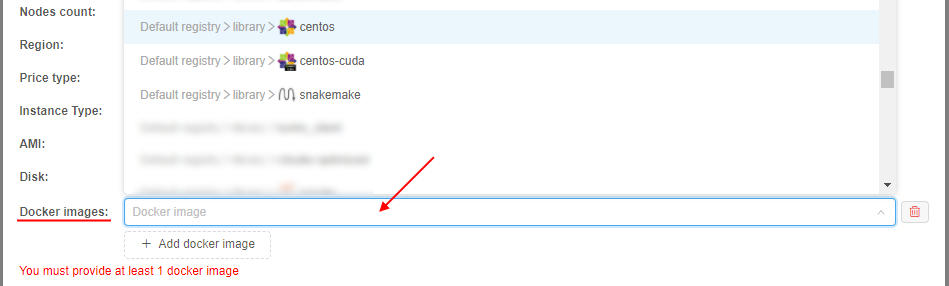
- select the image version in the appeared additional dropdown list:

- you may add several images analogically as described above
Note: at least one Docker image shall be added. Select of these images means that they will be pre-uploaded to the pool nodes. But such nodes also can be assigned to other jobs (with non-selected images) if other pool settings match the user request. In this case necessary requested image will be uploaded during the job initialization (so, it will just take longer).
- click the "+ Add docker image" button:
- If you wish you can set additional filters for the pool usage. They can be customized at the Filters panel:

Condition field allows to set which condition will use for the set filters:
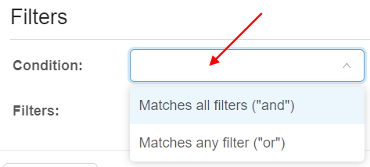
Filters section allows to add any count of additional filters for the created pool.
Click the button to add a filter.
to add a filter.
In the appeared field select a property that will be used for the filtering:
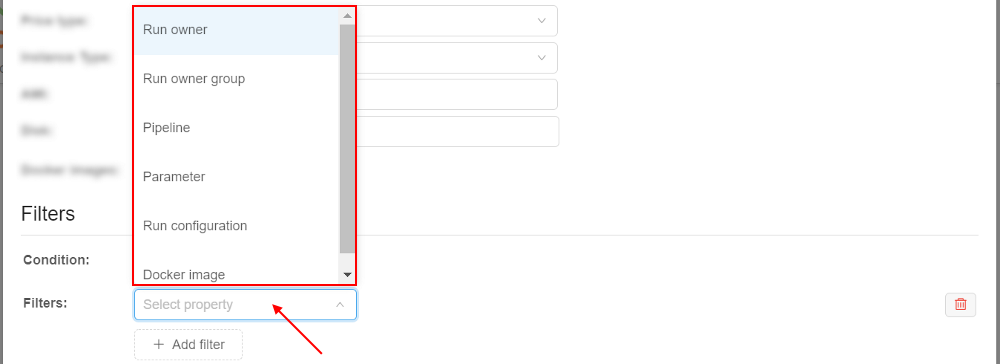
Possible properties:- Run owner - allows to set user restrictions for the current pool usage
- Run owner group - allows to set user group restrictions for the current pool usage
- Pipeline - allows to set pipeline restrictions for the current pool usage
- Parameter - allows to set parameter (and its value) restrictions for the current pool usage
- Run configuration - allows to set detach configuration restrictions for the current pool usage
- Docker image - allows to set docker image restrictions for the current pool usage
Set the desired property in the list, e.g.:

For the selected property set the condition:
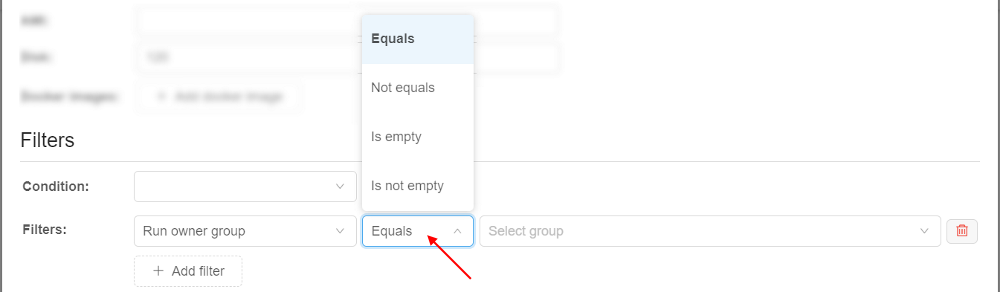
For the selected property specify/select the value, e.g.:
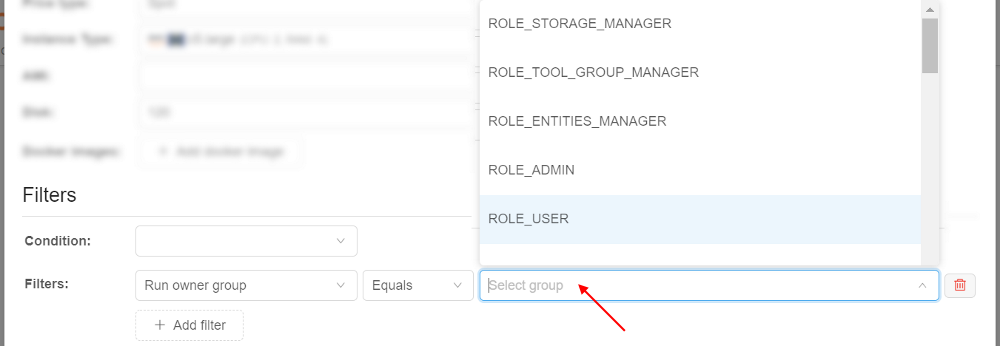
You can select any count of properties in the same way as described above, e.g.:
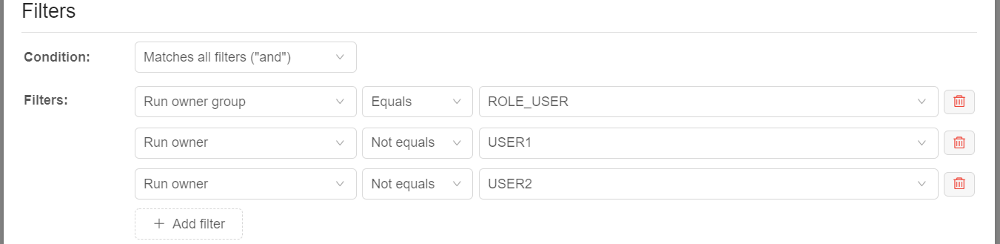
In the example above, nodes from the pool will be assigned to the job only if it will be launched by any user (except USER1 and USER2) with the ROLE_USER role (of course, if other settings match).
To remove the filter use the corresponding button in the filter row
- To confirm the pool creation, click the CREATE button
- Created pool will appear in the list:
View existing pools
At the HOT NODE POOLS tab, you can view all existing node pools, their schedules, settings, states.
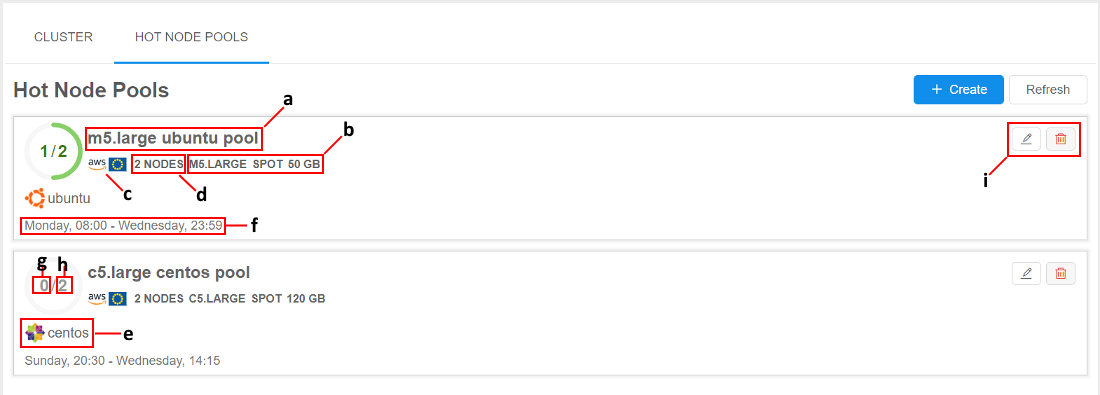
Where:
- a - pool name
- b - pool nodes settings (instance type, price type, disk size)
- c - pool nodes Cloud Provider / Region
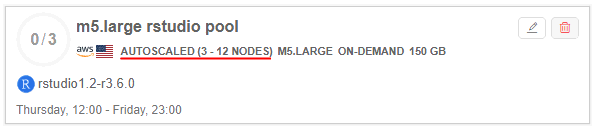
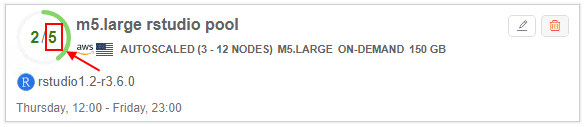
- d - the summary count of nodes in the pool. In case of "autoscaled" pool, this count is displayed as an interval, e.g.:

- e - the list of pre-uploaded docker images on the pool nodes
- f - the list of pool schedules
- g - the count of pool nodes assigned to jobs in the current moment
- h - the summary count of pool nodes running in the current moment (in background or assigned to jobs)
- i - controls to edit/remove the pool
To view the pool state, click it in the list, e.g.:
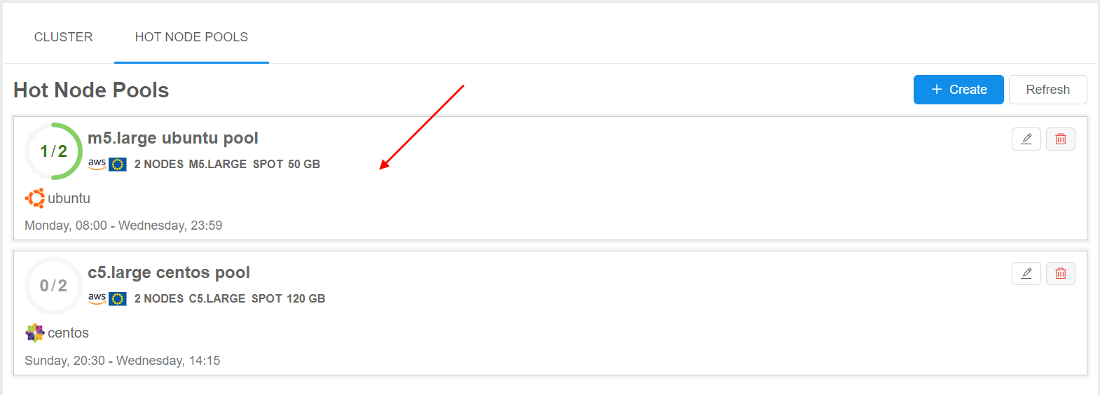
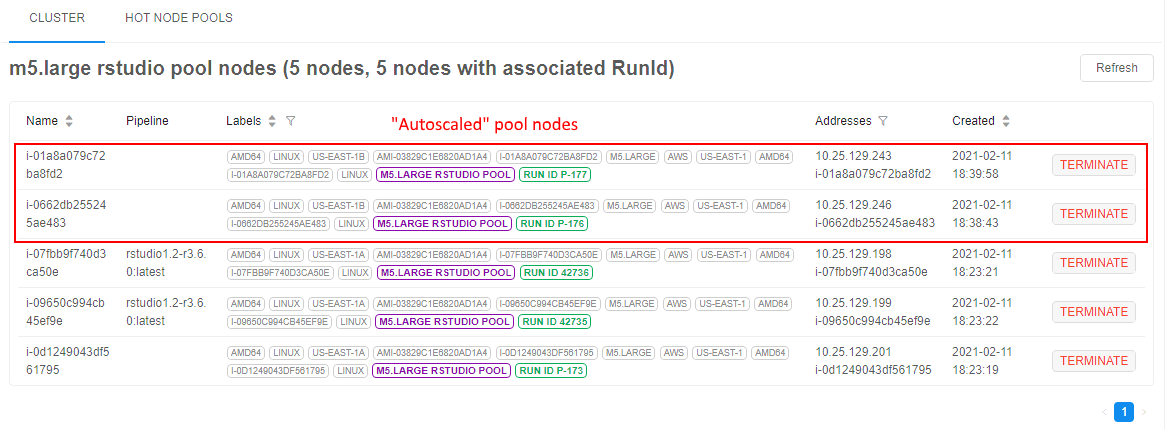
The pool nodes list will appear:
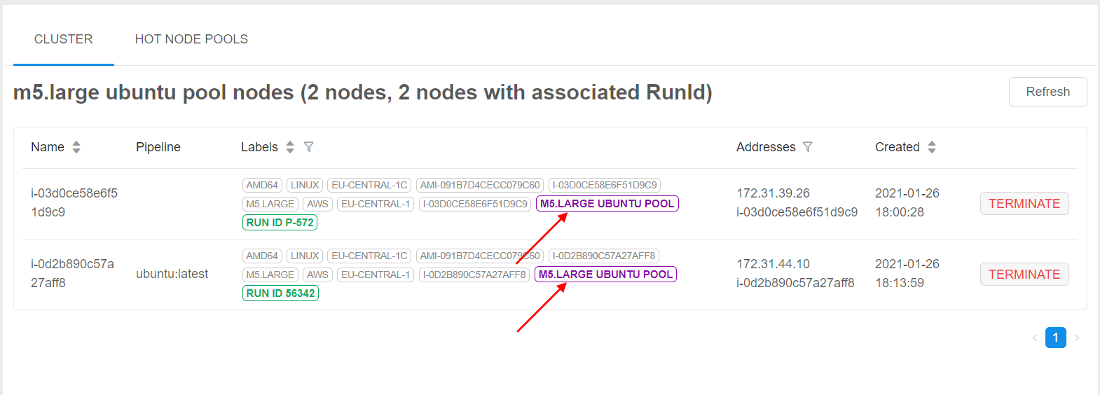
Nodes from the pool are marked by violet labels with the pool name.
Pool nodes that are running in background but not assigned to jobs yet have Run ID with format P-<number>.
Edit existing pool
To edit the existing pool, click the corresponding button on its tile:

The edit pop-up will be open:
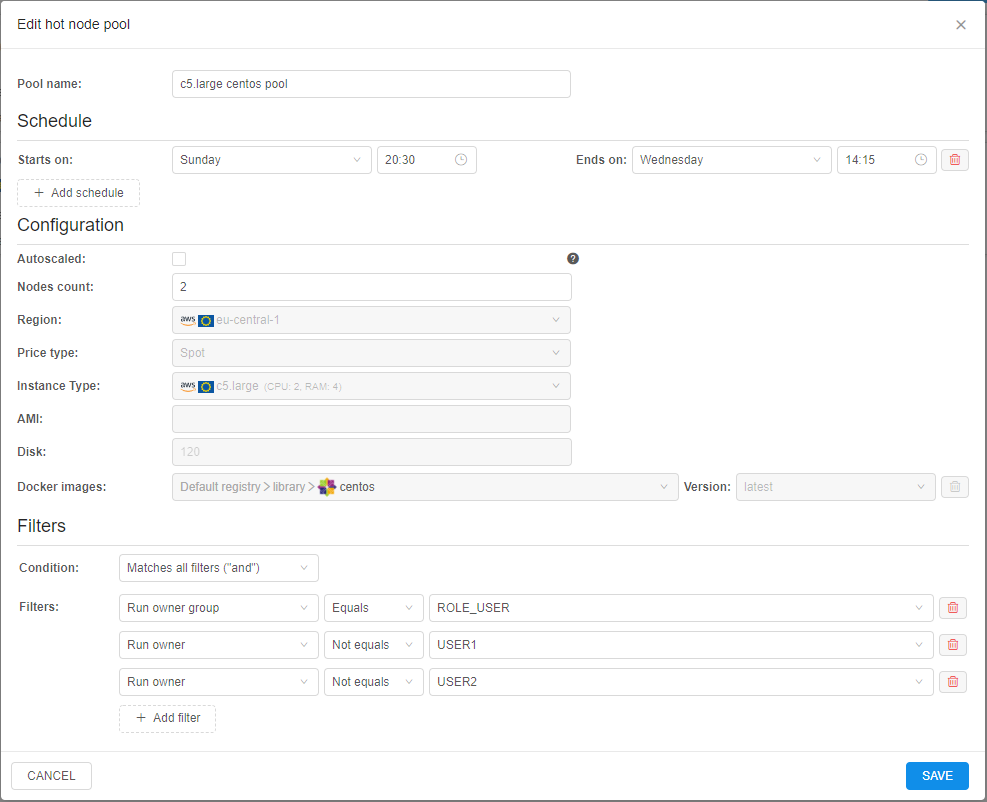
You can edit only pool name, pool schedules, pool nodes count (and "autoscaled" property/settings) and filters.
Make changes and click the SAVE button to confirm.
Example of using
- For example, there is the nodes pool that was created as described above:

- User launches the tool (in any time moment according to the schedule) with settings corresponding to pool nodes settings (same region, instance type, price type, smaller real disk size and in accordance with all configured filters), e.g.:
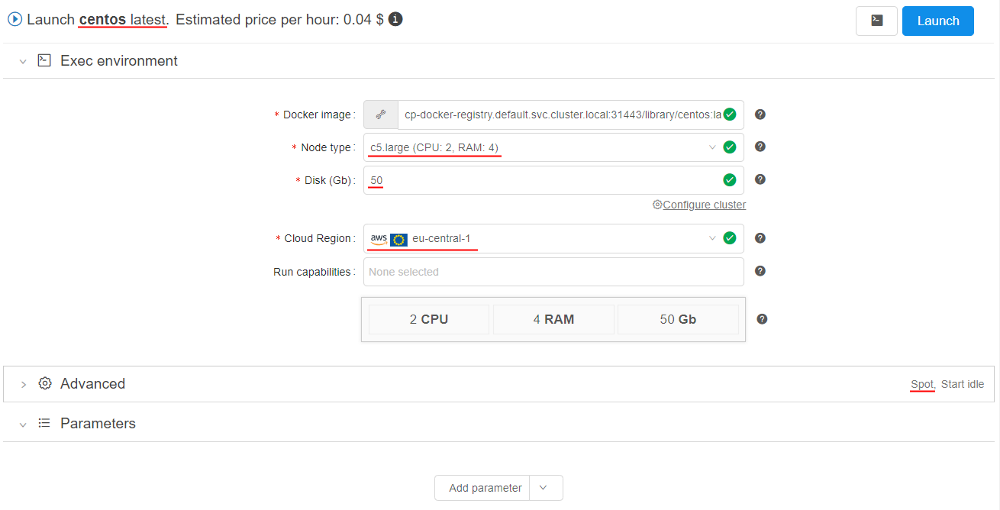
- After the launch, the system checks if there are any empty nodes in the cluster. If not, then system checks are there any empty nodes in the "hot node pools" match the requested job - and uses such hot node pool if it matches:
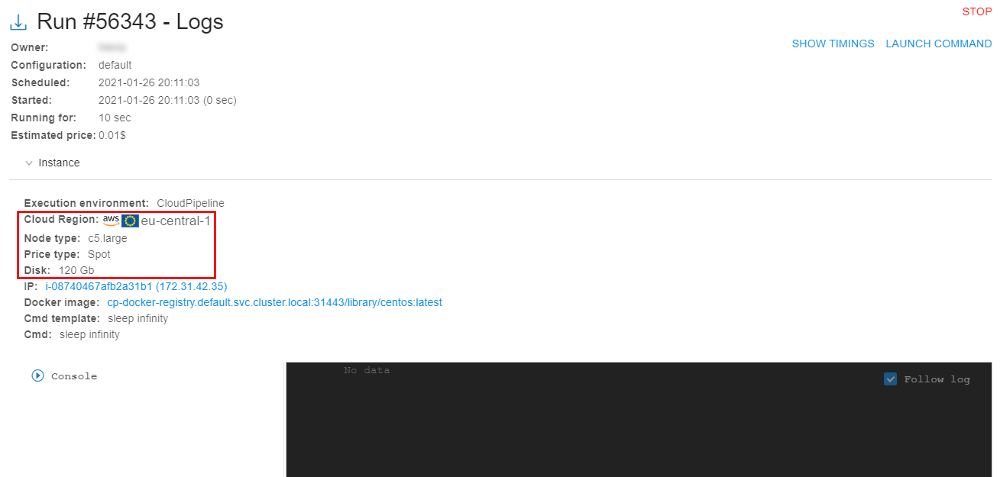
So, the running node from the "hot node pool" is assigned to the job after just several seconds.
Please note, that the disk was changed according to the configured one for the pool node. - Click the IP hyperlink to open node info:
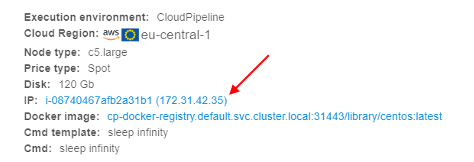
- At the node monitor page, you can see that it is the node from the pool:
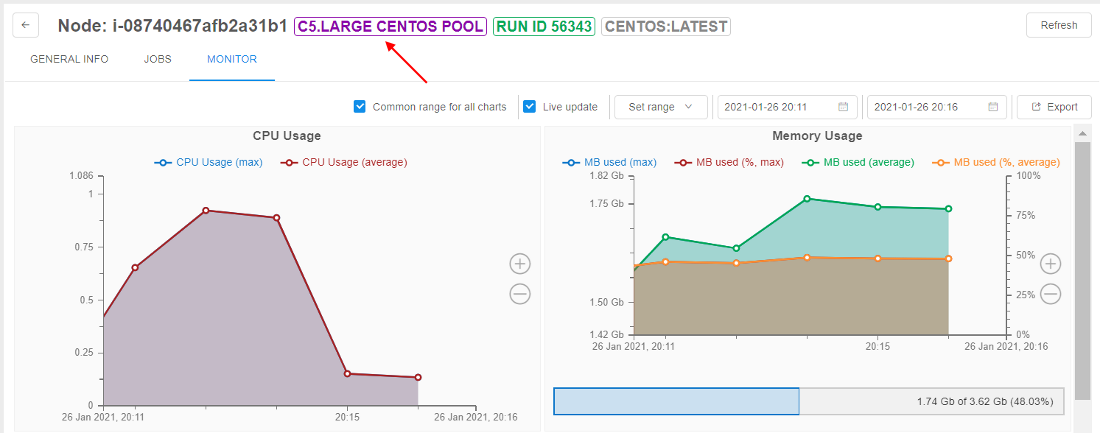
- Open the HOT NODE POOLS tab of the Cluster state section:
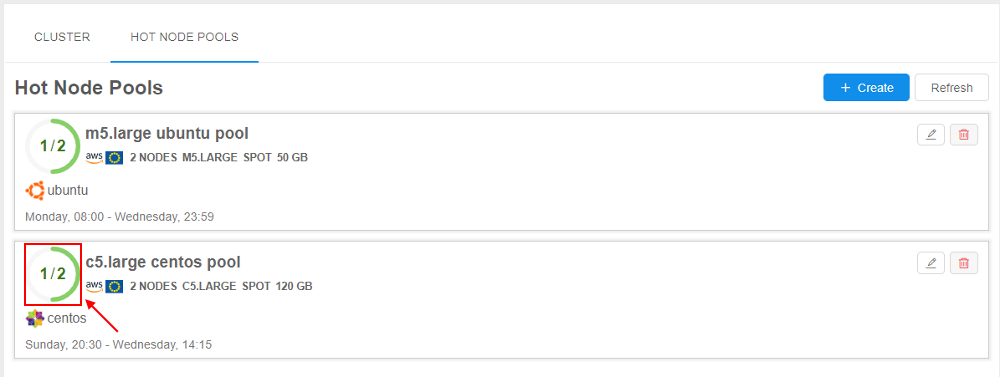
See that the pool state is changed (one node from two is occupied).
Example of using of the "autoscaled" node pool
- Open the static-size node pool, e.g.:
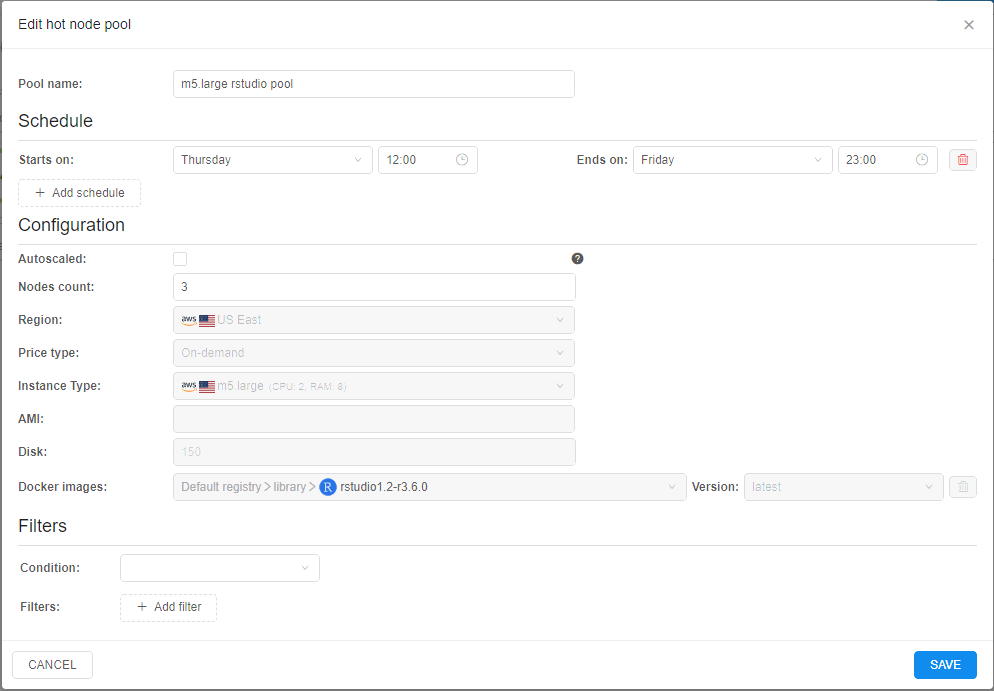
- Set the Autoscaled checkbox
- Specify the following autoscaled settings:
- Save changes:
- Launch at least 2 runs with settings corresponding to pool nodes settings - to occupy 2 of 3 nodes:
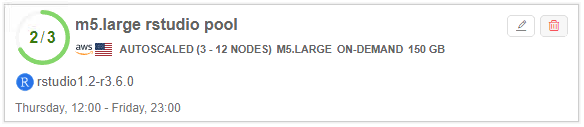
- As the occupied instances percent of the pool is higher than specified Scale Up Threshold (60%) - pool size will be automatically increased by the Scale Step size (2) in some time:
Pool utilization
Additionally, admins have the following abilities:
- view charts with hot node pools utilization per day/month
- enable a new type of the email notification - about the event when all pool node instances are used
For the viewing of the hot node pool utilization, there is a separate tab Pools usage in the Cluster state section:
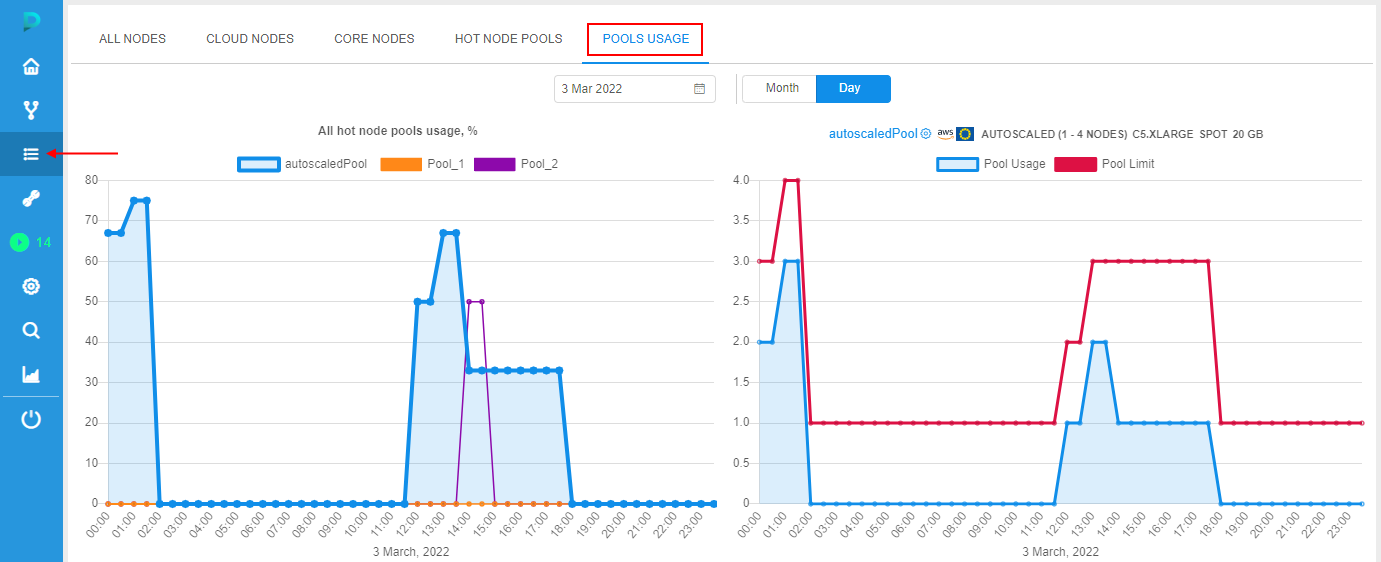
At this tab, there are:
- panel with a chart showing the utilization of all existing hot node pools (left chart):
- info is being displayed as line chart for each hot node pool - with time on X-axis and pools utilization (in percent) on Y-axis
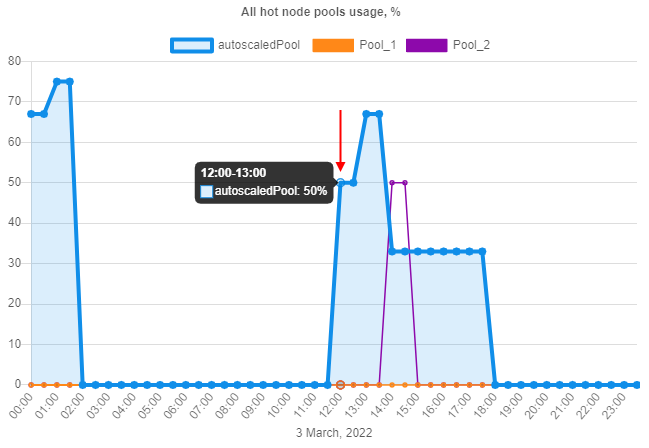
- user can hover any point of the desired hot node pool - the following info will appear:
- time range of the point
- hot node pool name
- maximum utilization (in percent) of that pool on that time range - i.e. the ratio of the maximum number of busy nodes to the total possible number of nodes on that time range
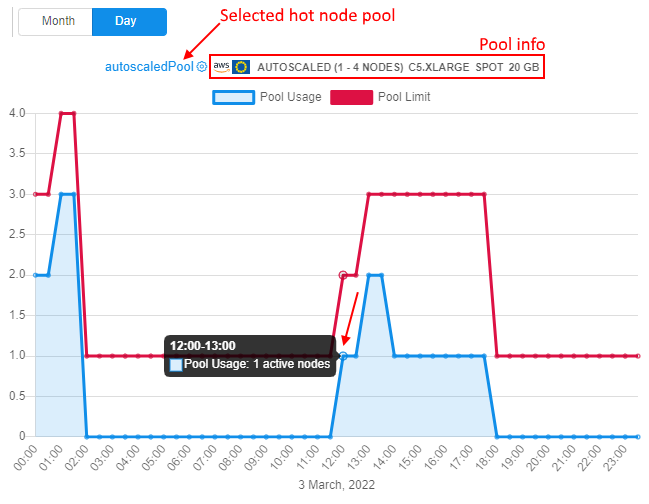
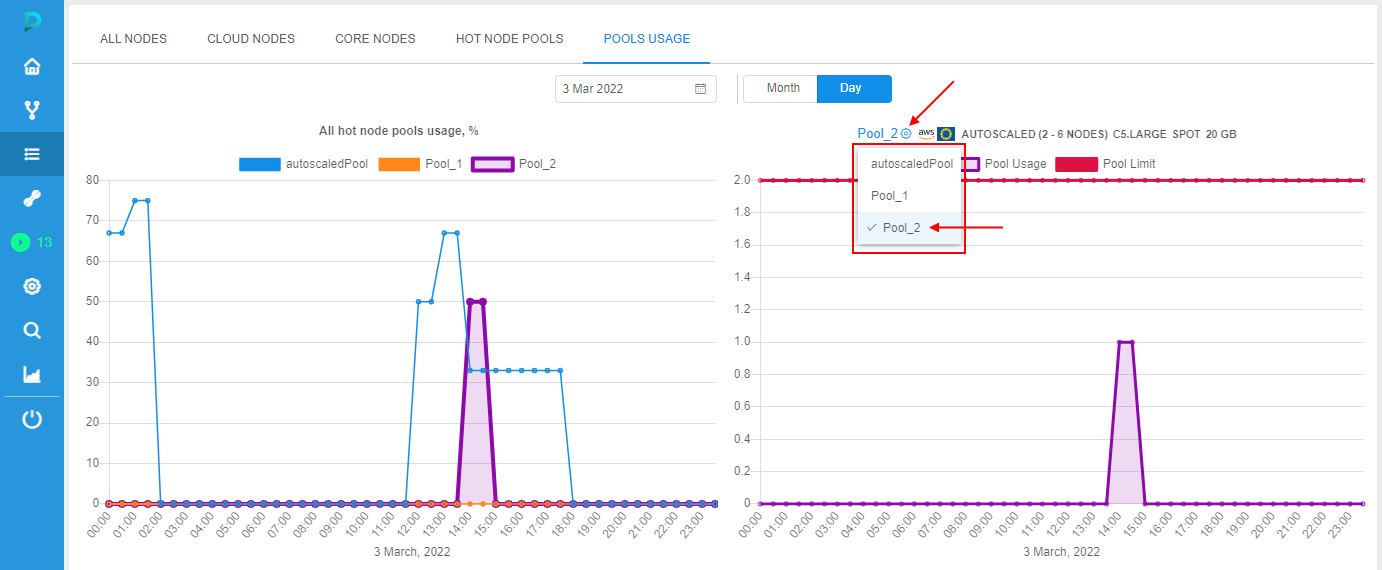
- panel with a chart showing the utilization of a certain selected hot node pool (right chart):
- info is being displayed as 2 line charts - with time on X-axis and a certain pool utilization (nodes under load count) on Y-axis:
- first line chart (with underlying) - the chart of the selected hot node pool utilization. Hot node pool can be selected by the dropdown list above the diagram. By default, the first hot node pool (by alphabetical ascending sorting) is auto selected. Highlighting of the currently selected pool chart for both diagrams (left and right) is the same
- second line chart (always red) - the chart of the selected hot node pool limit, i.e. it is the line that shows what was the maximum possible size of the pool at that time range
- user can hover any point of the selected hot node pool - the following info will appear:
- time range of the point
- hot node pool name
- maximum utilization (nodes under load count) of that pool on that time range
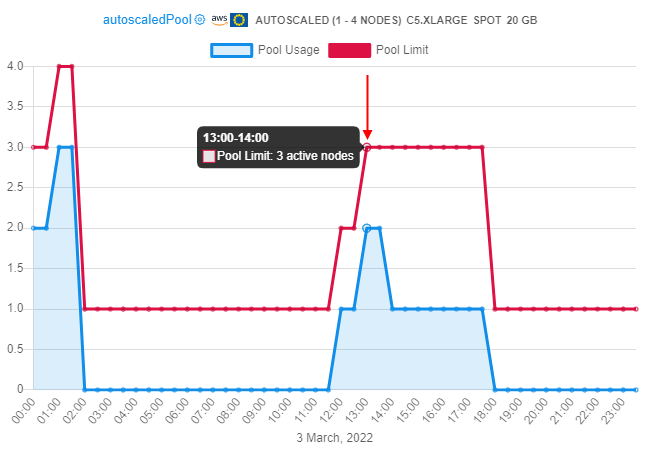
- user can hover any point of the hot node pool "limit" line - the following info will appear:
- time range of the point
- maximum possible size of that pool on that time range (nodes count)
- info is being displayed as 2 line charts - with time on X-axis and a certain pool utilization (nodes under load count) on Y-axis:
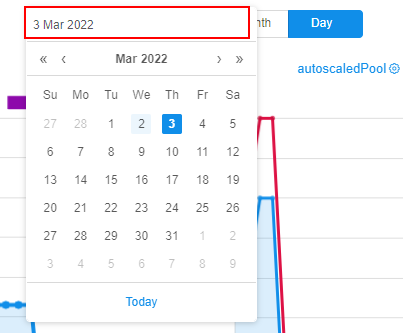
By default, charts are shown for the today. Via the Calendar control above the charts, there is the ability to select another day. Charts will be redrawn:
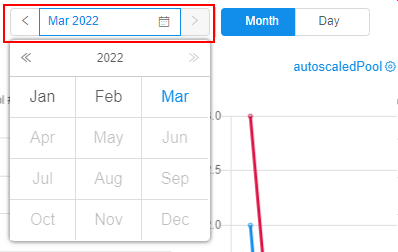
Also, period of the report can be change from the "Day" to "Month" - by the corresponding control above the charts. In this case, charts will be redrawn for the current month, e.g.:
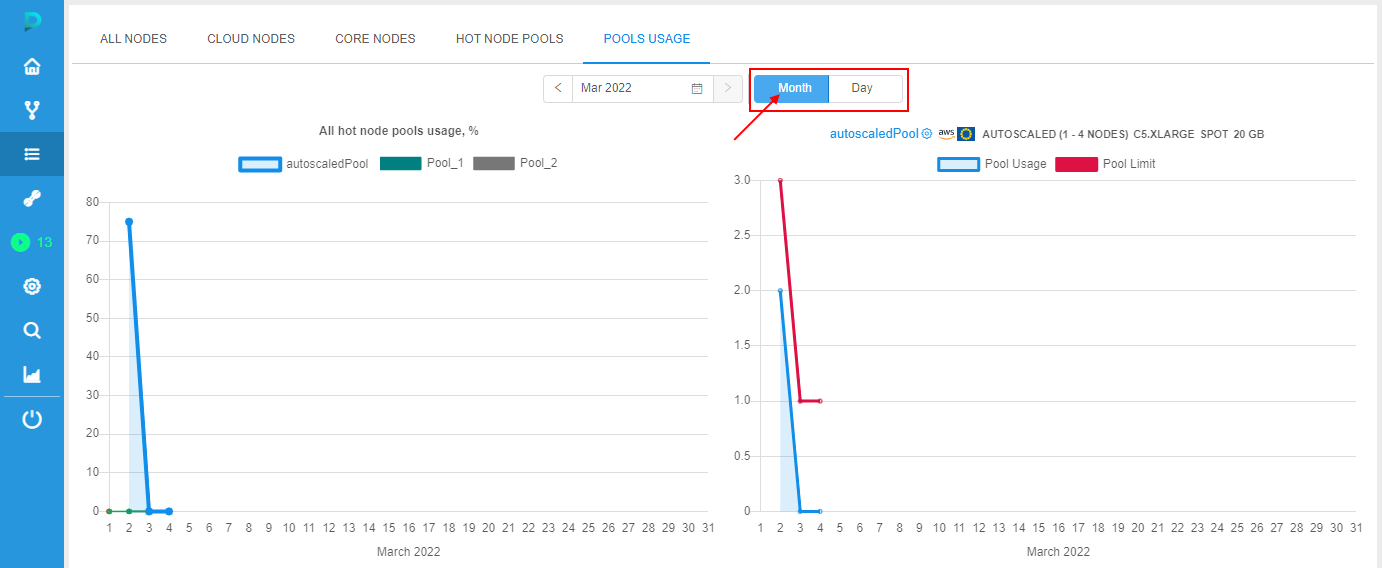
Via the Calendar control above the charts, there is the ability to select another month:
To view details of the another hot node pool utilization - select it in the dropdown above the right chart, e.g.:
Navigation from the Hot node pool tab
There is the ability to open the utilization for the certain hot node pool from the Hot node pools tab at the Cluster state section.
For that, click the "chart" button at the pool's tile:
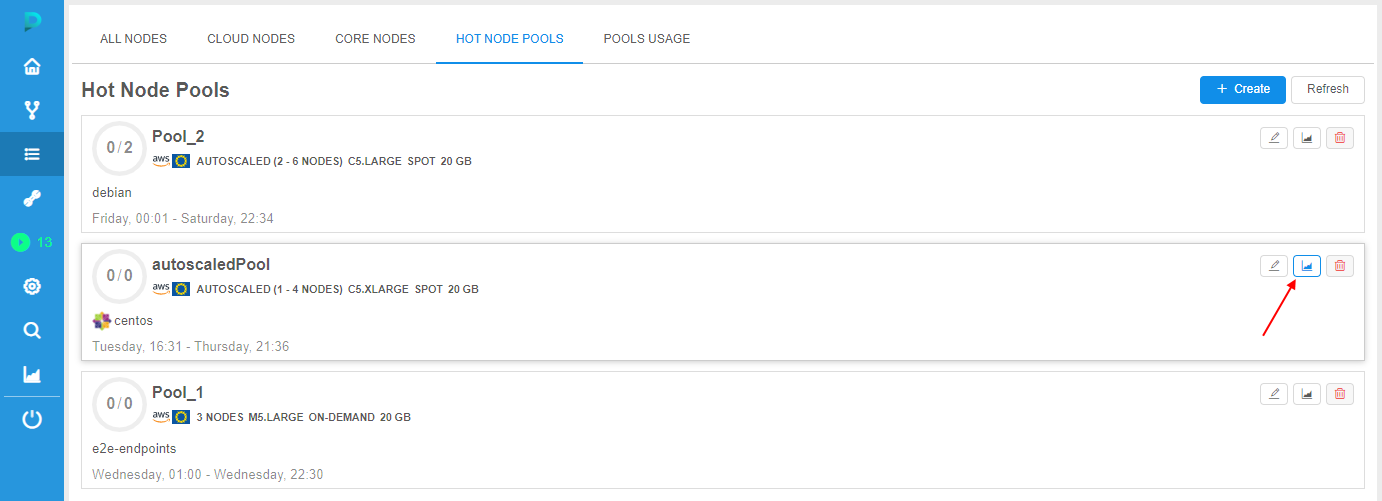
By click this button:
- the Pools usage tab will be opened
- at the left panel, the chart showing the utilization of all existing hot node pools will appear
- at the right panel, the chart showing utilization details of the selected hot node pool (that pool at which tile the button was clicked) will appear
Managing preferences
There are the following system preferences to manage monitoring of the hot node pool usage:
| Preference | Description |
|---|---|
monitoring.node.pool.usage.enable |
Allows to enable monitoring of the hot node pools usage |
monitoring.node.pool.usage.delay |
Determines the frequency of pools load measurements (in milliseconds). Default - 5 minutes |
monitoring.node.pool.usage.store.days |
Determines the storing period for the monitoring data (in days) - all data older that period will be cleaned if monitoring.node.pool.usage.clean.enable set to true.Default value - 365 days |
monitoring.node.pool.usage.clean.enable |
Allows to enable cleaning of the hot node pools usage monitoring data |
monitoring.node.pool.usage.clean.delay |
Determines the frequency of cleaning of pools usage monitoring data (in milliseconds). Data will be cleaned every monitoring.node.pool.usage.clean.delay period, if monitoring.node.pool.usage.clean.enable is set to true.Default value - 24 hours |