Cloud Pipeline v.0.16 - Release notes
- Google Cloud Platform Support
- System logs
- Displaying Cloud Provider's icon
- Configurable timeout of GE Autoscale waiting
- Storage mounts data transfer restrictor
- Extended recursive symlinks handling
- Displaying of the latest commit date/time
- Renaming of the GitLab repository in case of Pipeline renaming
- Pushing pipeline changes to the GitLab on behalf of the user
- Allowing to expose compute node FS to upload and download files
- Resource usage form improvement
- View the historical resources utilization
- Ability to schedule automatic pause/restart of the running jobs
- Update pipe CLI version
- Blocking/unblocking users and groups
- Displaying additional node metrics
- Export user list
- Displaying SSH link for the active runs in the Dashboard view
- Enable Slurm for the Cloud Pipeline's clusters
- The ability to generate the
pipe runcommand from the GUI pipeCLI: view tools definitions- List the users/groups/objects permissions globally via
pipeCLI - Storage usage statistics retrieval via
pipe - GE Autoscaler respects CPU requirements of the job in the queue
- Restrictions of "other" users permissions for the mounted storage
- Search the tool by its version/package name
- The ability to restrict which run statuses trigger the email notification
- The ability to force the specific Cloud Provider for an image
- Restrict mounting of data storages for a given Cloud Provider
- Ability to "symlink" the tools between the tools groups
- Notable Bug fixes
- Parameter values changes cannot be saved for a tool
- Packages are duplicated in the tool's version details
- Autoscaling cluster can be autopaused
pipe: not-handled error while trying to execute commands with invalid config- Setting of the tool icon size
NPEwhile building cloud-specific environment variables for run- Worker nodes fail due to mismatch of the regions with the parent run
- Worker nodes shall not be restarted automatically
- Uploaded storage file content is downloaded back to client
- GUI improperly works with detached configurations in a non-default region
- Detached configuration doesn't respect region setting
- Incorrect behavior of the "Transfer to the cloud" form in case when a subfolder has own metadata
- Incorrect displaying of the "Start idle" checkbox
- Limit check of the maximum cluster size is incorrect
- Fixed cluster with SGE and DIND capabilities fails to start
- Azure: Server shall check Azure Blob existence when a new storage is created
- Azure:
pipeCLI cannot transfer empty files between storages - Azure: runs with enabled GE autoscaling doesn't stop
- Incorrect behavior while download files from external resources into several folders
- Detach configuration doesn't setup SGE for a single master run
- Broken layouts
Google Cloud Platform Support
One of the major v0.16 features is a support for the Google Cloud Platform.
All the features, that were previously used for AWS and Azure, are now available in all the same manner, from all the same GUI/CLI, for GCP.
This provides an even greater level of a flexibility to launch different jobs in the locations, closer to the data, with cheaper prices or better compute hardware in depend on a specific task.
System logs
In the current version, the "Security Logging" was implemented.
Now, the system records audit trail events:
- users' authentication attempts
- users' profiles modifications
- platform objects' permissions management
- access to interactive applications from pipeline runs
- other platform functionality features
Logs are collected/managed at the Elasticsearch node and backed up to the object storage (that could be configured during the platform deployment).
The administrator can view/filter these logs via the GUI - in the System-level settings, e.g.:
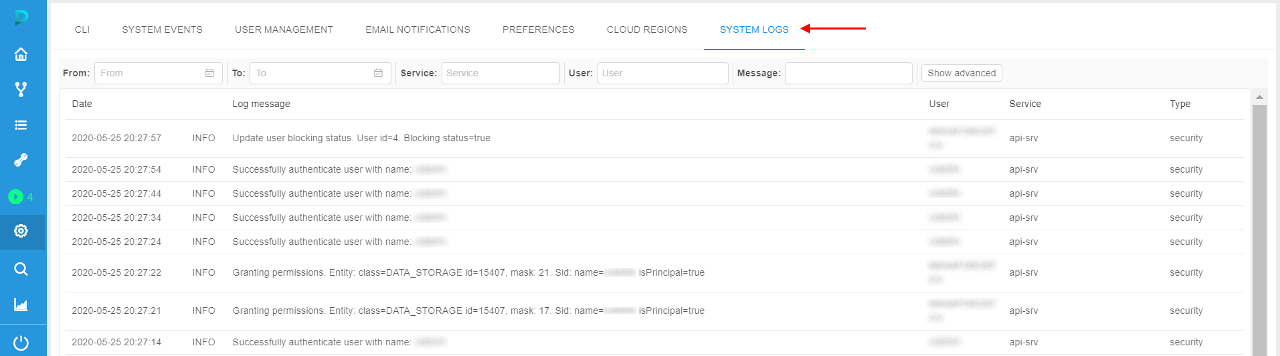
Each record in the logs list contains:
| Field | Description |
|---|---|
| Date | The date and time of the log event |
| Log status | The status of the log message (INFO, ERROR, etc.) |
| Log message | Description of the log event |
| User | User name who performed the event |
| Service | Service name that registered the event (api-srv, edge) |
| Type | Log message type (currently, only security type is available) |
For more details see here.
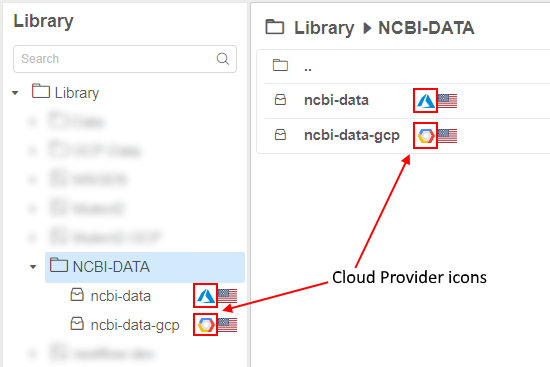
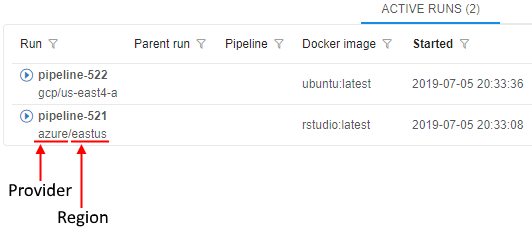
Displaying Cloud Provider's icon for the storage/compute resources
As presented in v0.15, Cloud Pipeline can manage multi Cloud Providers in a single installation.
In the current version, useful icon-hints with the information about using Cloud Provider are introduced.
If a specific platform deployment has a number of Cloud Providers registered (e.g. AWS+Azure, GCP+Azure) - corresponding icons/text information are displaying next to the cloud resource.
Such cloud resources are:
Object/File Storages(icons in the Library, at the "DATA" panel of the Dashboard etc.)

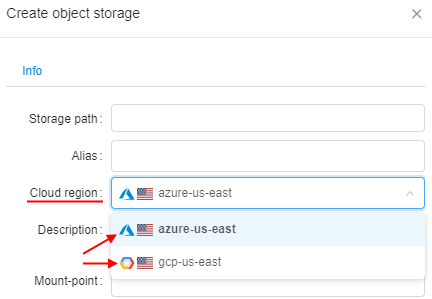
Regions(icons in the Cloud Regions configuration, at the Launch form etc.)
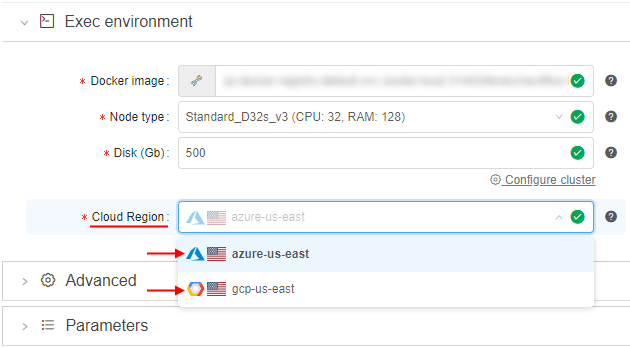
Running jobs:- text hints (at the RUNS page)
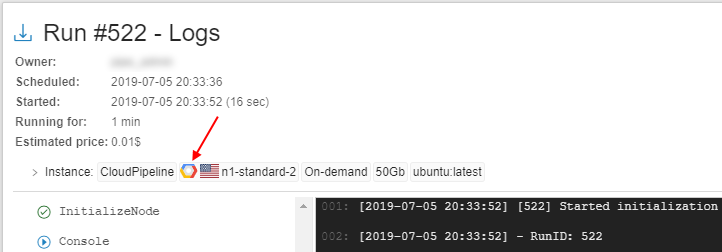
- icons (at the Run logs page, at the "RUNS" panels of the Dashboard)
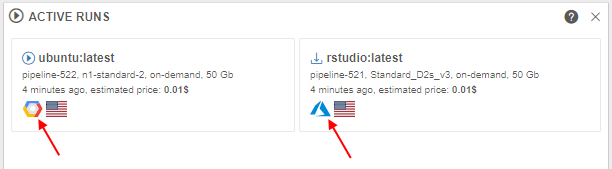
- text hints (at the RUNS page)
Note: this feature is not available for deployments with a single Cloud Provider.
Examples of displaying Cloud Region icons/info see in sections 6. Manage Pipeline, 7. Manage Detached configuration, 8. Manage Data Storage and 18. Home page.
Configurable timeout of GE Autoscale waiting for a worker node up
Previously, GE Autoscaler waited for a worker node up for a fixed timeout. This could lead to incorrect behavior for specific CLoud Providers, because the timeout can be very different.
Current version extracts GE Autoscaler polling timeout to a new system preference ge.autoscaling.scale.up.polling.timeout.
That preference defines how many seconds GE Autoscaler should wait for pod initialization and run initialization.
Default value is 600 seconds (10 minutes).
Storage mounts data transfer restrictor
Users may perform cp or mv operations of the large files (50+ Gb) to and from the fuse-mounted storages.
It is uncovered that such operations are not handled properly within the fuse implementations. Commands may hang for a long timeout or produce zero-sized result.
The suggested more graceful approach for the copying of the large files is to use pipe cp/pipe mv commands, which are behaving correctly for the huge volumes.
To avoid users of performing usual cp or mv commands for operations with the large files - now, Cloud Pipeline warns them about possible errors and suggest to use corresponding pipe commands.
Specified approach is implemented in the following manner:
- if a
cp/mvcommand is called with the source/dest pointing to the storage (e.g./cloud-data/<storage_path>/...) - the overall size of the data being transferred is checked - if that size is greater than allowed, a warning message will be shown, e.g.:
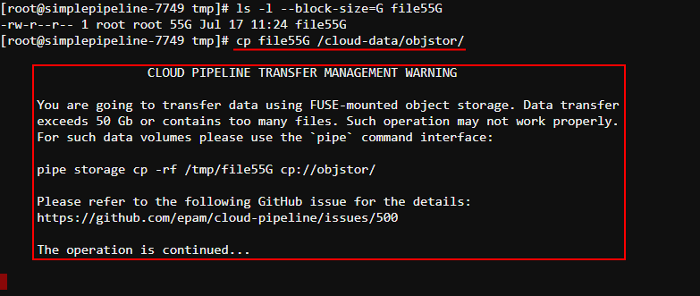
- this warning doesn't abort the user's command execution, it is continued
- appearance of this warning is configured by the following launch environment variables (values of these variables could be set only by admins via system-level settings):
CP_ALLOWED_MOUNT_TRANSFER_SIZE- sets number of gigabytes that is allowed to be transferred without warning. By default 50 Gb.CP_ALLOWED_MOUNT_TRANSFER_SIZE_TIMEOUT- sets number of seconds that the transfer size retrieving operation can take. By default 5 seconds.CP_ALLOWED_MOUNT_TRANSFER_FILES- sets number of files that is allowed to be transferred without warning. Supported only forAzureCloud Provider. By default 100 files.
Note: this feature is not available for
NFS/SMBmounts, only for object storages.
Extended recursive symlinks handling
There could be specific cases when some services execute tasks using the on-prem storages, where "recursive" symlinks are presented. This causes the Cloud Pipeline Data transfer service to follow symlinks infinitely.
In v0.16, a new feature is introduced for Data transfer service to detect such issues and skip the upload for files/folders, that cause infinite loop over symlinks.
A new option -sl (--symlinks) was added to the pipe storage cp / mv operations to handle symlinks (for local source) with the following possible values:
follow- follow symlinks (default)skip- do not follow symlinksfilter- follow symlinks but check for cyclic links and skip them
Example for the folder with recursive and non-recursive symbolic links:

Also options were added to the Data transfer service to set symlink policy for transfer operations.
For more details about pipe storage cp / mv operations see here.
Displaying of the latest commit date/time
Users can modify existing tools and then commit them to save performed changes.
It can be done by COMMIT button on the run's details page:

Previously, if user committed some tool, only commit status was shown on the run's details page.
In the current version, displaying of the date/time for the tool latest commit is added:
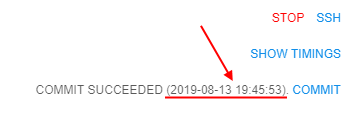
For more details about tool commit see here.
Renaming of the GitLab repository in case of Pipeline renaming
Pipeline in the Cloud Pipeline environment is a workflow script with versioned source code, documentation, and configuration. Under the hood, it is a git repository.
Previously, if the Pipeline object was renamed - the underlying GitLab repository was keeping the previous name.
In the current version, if user renames a Pipeline the corresponding GitLab repository will be also automatically renamed:



Need to consider in such case that the clone/pull/push URL changes too. Make sure to change the remote address, if you use the Pipeline somewhere else.
For more details see here.
Pushing pipeline changes to the GitLab on behalf of the user
If the user saves the changed Pipeline object - it actually means that a new commit is created and pushed to the corresponding GitLab repo.
Previously, all the commits pushed to the GitLab via the Cloud Pipeline GUI were made on behalf of the service account. This could break traceability of the changes.
In current version, the author of the commit is displayed in the Web GUI (for all Pipeline versions - the draft and released), the commits are performed on behalf of the real user:

Allowing to expose compute node FS to upload and download files
For the interactive runs users are processing data in ad-hoc manner, which requires upload data from the local storage to the cloud and download results from the cloud to the local storage.
Cloud Pipeline supports a number of options for the user to perform that data transfers for the interactive runs:
- via the Object Storage (using Web GUI or CLI)
- via the File Storage (using Web GUI, CLI, WebDav-mounted-drive)
Previously, view, download, upload and delete operations required an intermediate location (bucket or fs) to be used. It might confuse user when a small dataset shall be loaded to the specific location within a run's filesystem.
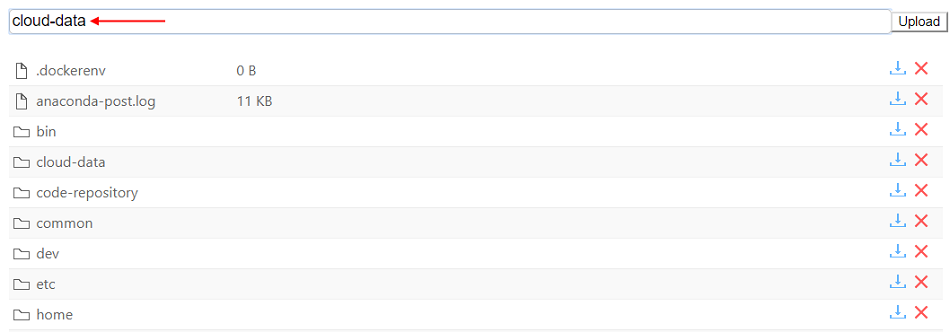
In the current version, direct exposure of the run's filesystem is supported. The BROWSE hyperlink is displayed on the Run logs page after a job had been initialized:
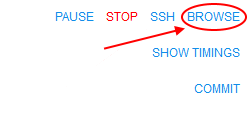
User can click the link and a Storage browser Web GUI will be loaded:
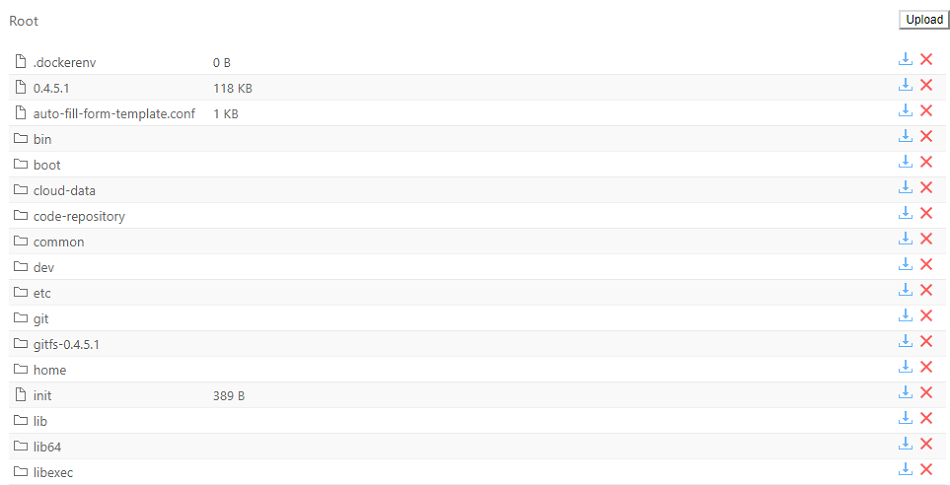
User is able to:
- view files and directories
- download and delete files and directories

- upload files and directories
- search files and directories
For more details see here.
Resource usage form improvement
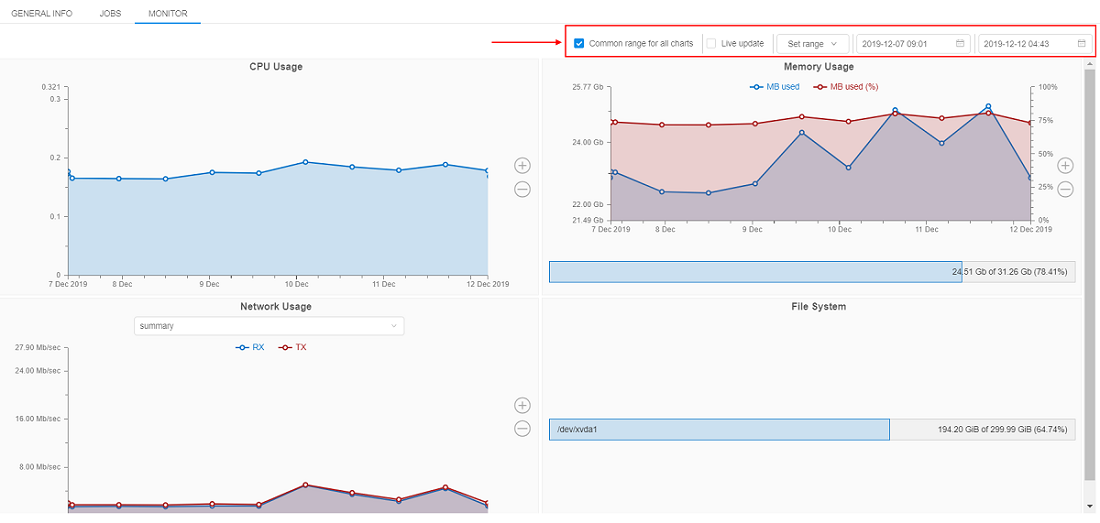
In v0.16, the number of filters were added to the Monitor cluster nodes feature:
- Common range for all charts
User can synchronize the time period for all plots. To do so user should mark the "Common range for all charts" filter.
If this filter is unmarked, user can zoom any plot without any change for others. - Live update
The plots data will be updated every 5 seconds in a real-time manner. The fields with dates will be updated as well. - Set range
User can select the predefined time range for all plots from the list:- Whole range
- Last week
- Last day
- Last hour
- Date filter
User can specify the Start and the End dates for plots. The system will substitute the node creating date as the Start date and current date for the End date, if user doesn't select anything.
All filters are working for all plots simultaneously: data for all plots will be dynamically updated as soon as the user changes filter value.
For more details see here.
Allow to view the historical resources utilization
Another convenient feature that was implemented in v0.16 linked to the Cluster nodes monitor is viewing of the detailed history of the resource utilization for any jobs.
Previously, it was available only for active jobs. Now, users can view the utilization data even for completed (succeed/stopped/failed) jobs for debugging/optimization purposes.
The utilization data for all runs is stored for a preconfigured period of time that is set by the system preference system.resource.monitoring.stats.retention.period (defaults to 5 days).
I.e. if the job has been stopped and the specified time period isn't over - the user can access to the resources utilization data of that job:
- Open the Run logs page for the completed job:
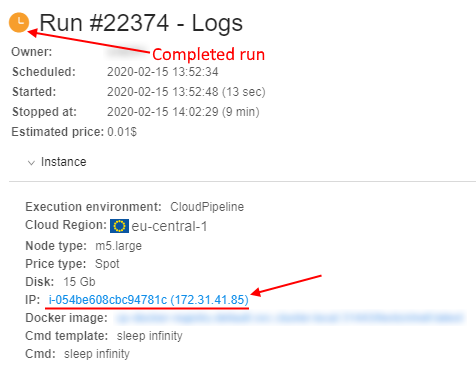
Click the node name hyperlink - The Monitor page of the node resources utilization will be opened:
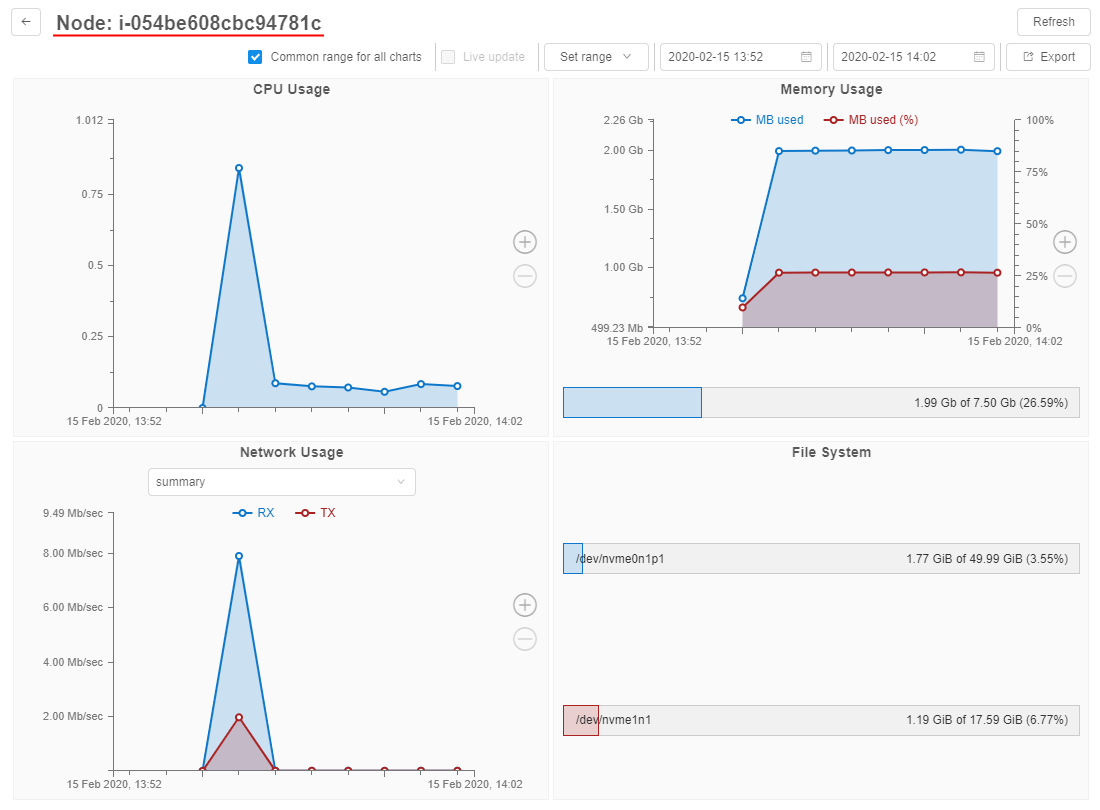
Also now, users have the ability to export the utilization information into a .csv file.
This is required, if the user wants to keep locally the information for a longer period of time than defined by system.resource.monitoring.stats.retention.period:
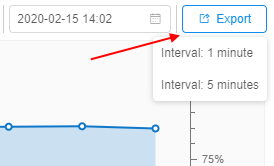
The user can select the interval for the utilization statistics output and export the corresponding file.
For more details see here.
Ability to schedule automatic pause/restart of the running jobs
For certain use cases (e.g. when Cloud Pipeline is used as a development/research environment) users can launch jobs and keep them running all the time, including weekends and holidays.
To reduce costs, in the current version, the ability to set a Run schedule was implemented. This feature allows to automatically pause/resume runs, based on the configuration specified. This feature is applied only to the "Pausable" runs (i.e. "On-demand" and non-cluster):
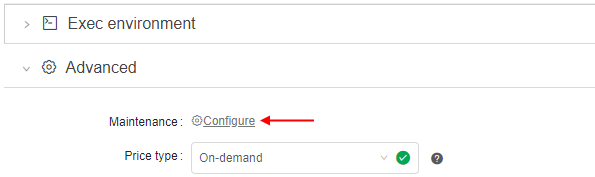
- The user (who has permissions to pause/resume a run) is able to set a schedule for a run being launched:
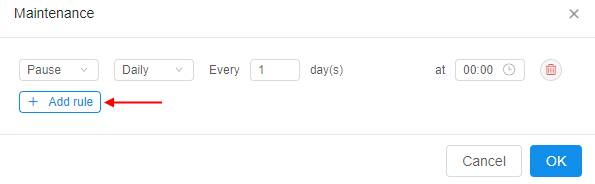
- Schedule is defined as a list of rules - user is able to specify any number of them:

- For each rule in the list user is able to set the action (
PAUSE/RESUME) and the recurrence:
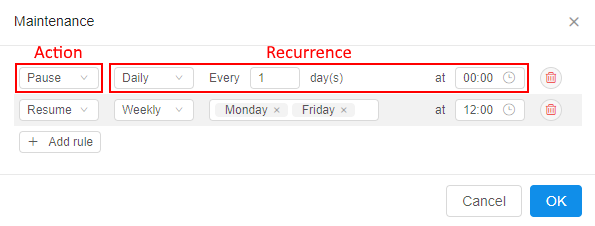
If any schedule rule is configured for the launched active run - that run will be paused/restarted accordingly in the scheduled day and time.
Also, users (who have permissions to pause/resume a run) can create/view/modify/delete schedule rules anytime run is active via the Run logs page:

See more details here (item 5).
Update pipe CLI version
Previously, if the user installed pipe CLI to his local workstation, used it some time - and the Cloud Pipeline API version could be updated during this period - so the user had to manually perform complete re-installing of pipe CLI every time to have an actual version.
Currently, the pipe update command to update the Cloud Pipeline CLI version was implemented.
This command compare the CLI and API versions. If the CLI version is less than the API one, it will update the CLI - the latest Cloud Pipeline CLI version will be installed. Otherwise no actions will be performed:
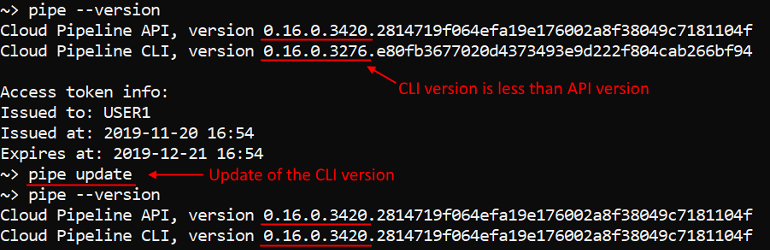
For more details see here.
Blocking/unblocking users and groups
In current version, the ability for administrators to set the "blocked" flag for the specific user or a whole group is implemented.
This flag prevents user(s) to access Cloud Pipeline platform by the GUI.
Administrators can block or unblock users/groups via the User management tab of the System Settings dashboard.
For example, for a user:
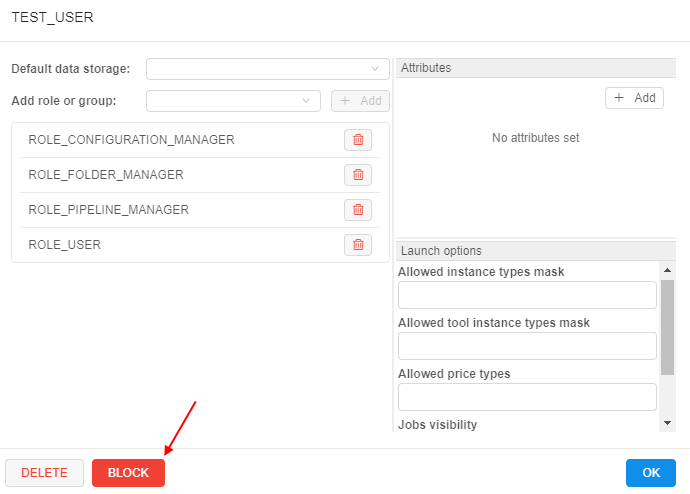
For the blocked user the special label will be displayed aside to the user's name:

The blocked user won't be able to access Cloud Pipeline via the GUI. The error message will be displayed when trying to login:
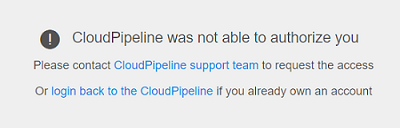
Note: any content generated by the blocked users is kept in the Cloud Pipeline, all the log trails on the users activities are kept as well. Only access to the platform is being restricted.
To unblock click the UNBLOCK button that appeared instead of the BLOCK button:
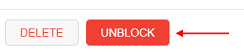
All these actions could be performed also to a group. Users from a blocked group will not have access to the platform.
For more details about users blocking/unblocking see here.
For more details about groups blocking/unblocking see here.
Displaying additional node metrics at the Runs page
In v0.16, the displaying of high-level metrics information for the Active Runs is implemented:
 - "Idle" - this auxiliary label is shown when node's CPU consumption is lower than a certain level, defined by the admin. This label should attract the users attention cause such run may produce extra costs.
- "Idle" - this auxiliary label is shown when node's CPU consumption is lower than a certain level, defined by the admin. This label should attract the users attention cause such run may produce extra costs. - "Pressure" - this auxiliary label is shown when node's Memory/Disk consumption is higher than a certain level, defined by the admin. This label should attract the users attention cause such run may accidentally fail.
- "Pressure" - this auxiliary label is shown when node's Memory/Disk consumption is higher than a certain level, defined by the admin. This label should attract the users attention cause such run may accidentally fail.
These labels are displayed:
- at the Runs page
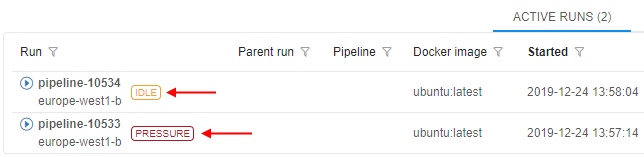
- at the Run logs page
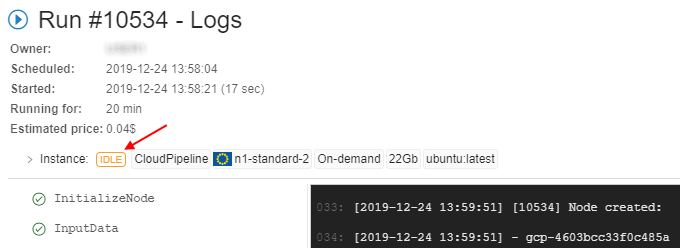
- at the main dashboard (the ACTIVE RUNS panel)
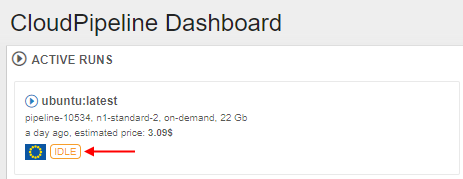
Note: if a user clicks this label from the Runs or the Run logs page the Cluster node Monitor will be opened to view the current node consumption.
Admins can configure the emergence of these labels by the set of previous implemented system-level parameters.
For the IDLE label:
system.max.idle.timeout.minutes- specifies the duration in minutes how often the system should check node's activitysystem.idle.cpu.threshold- specifies the percentage of the CPU utilization, below which label will be displayed
For the PRESSURE label:
system.disk.consume.threshold- specifies the percentage of the node disk threshold above which the label will be displayedsystem.memory.consume.threshold- specifies the percentage of the node memory threshold above which the label will be displayed
For more details see here.
Export user list
In the current version, the ability to export list of the platform users is implemented. This feature is available only for admins via User management tab of the system-level settings:

Admin can download list with all users and their properties (user name, email, roles, attributes, state, etc.) by default or custom configure which properties should be exported:
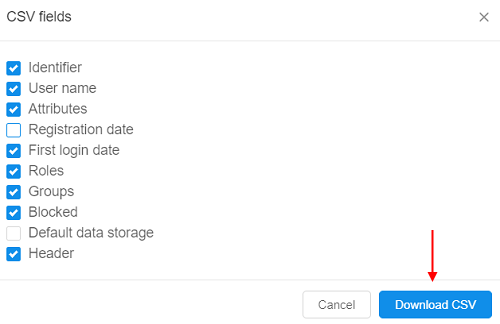
The downloaded file will have the .csv format.
For more details see here.
Displaying SSH link for the active runs in the Dashboard view
Users can run SSH session over launched container. Previously, SSH link is only available from the Run logs page.
In v0.16, a new helpful capability was implemented that allows to open the SSH connection right from the Active Runs panel of the main Dashboard:
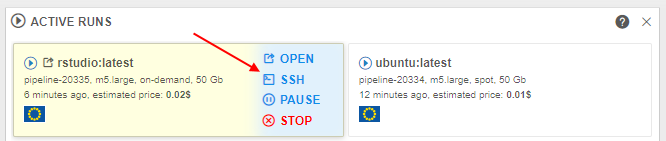
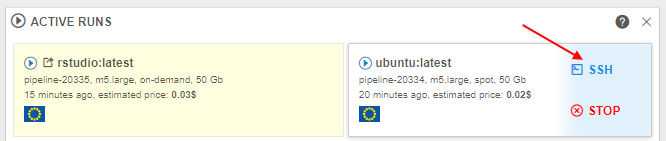
That SSH link is available for all the non-paused active jobs (interactive and non-interactive) after all run's checks and initializations have passed (same as at the Run logs page).
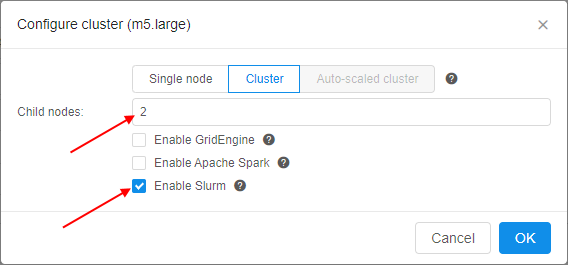
Enable Slurm workload manager for the Cloud Pipeline's clusters
A new feature for the Cloud Pipeline's clusters was implemented in v0.16.
Now, Slurm can be configured within the Cluster tab. It is available only for the fixed size clusters.
To enable this feature - tick the Enable Slurm checkbox and set the child nodes count at cluster settings. By default, this checkbox is unticked. Also users can manually enable Slurm functionality by the CP_CAP_SLURM system parameter:
This feature allows you to use the full stack of Slurm cluster's commands to allocate the workload over the cluster, for example:
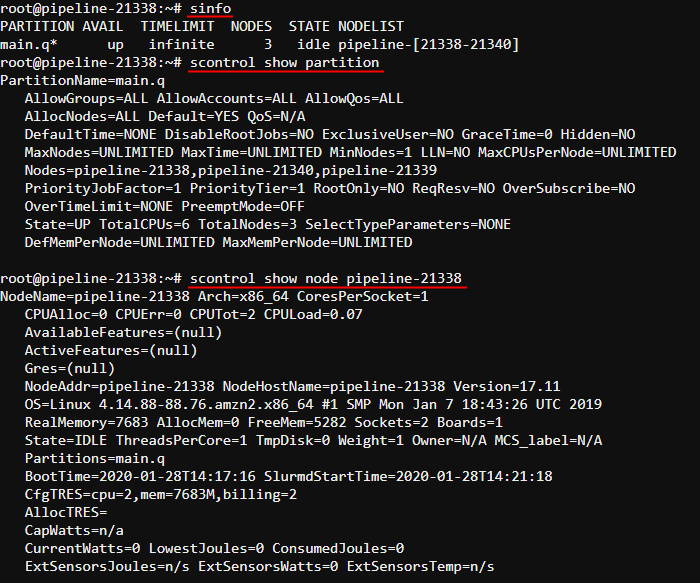
For more information about using Slurm via the Cloud Pipeline see
here.
The ability to generate the pipe run command from the GUI
A user has a couple of options to launch a new job in the Cloud Pipeline:
APICLIGUI
The easiest way to perform it is the GUI. But for automation purposes - the CLI is much more handy. Previously, users had to construct the commands manually, which made it hard to use.
Now, the ability to automatically generate the CLI commands for job runs appeared in the GUI.
Now, users can get a generated CLI command (that assembled all the run information):
- at the Launch form:
- at the Run logs form:

Note: this button is available for completed runs too
Once click these buttons - the popup with the corresponding pipe run command will appear:
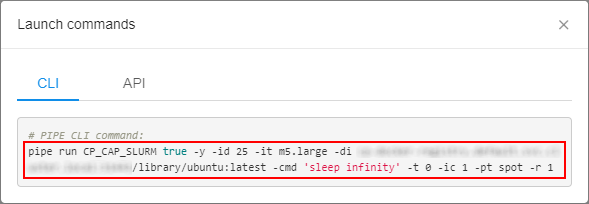
User can copy such command and paste it to the CLI for further launch.
Also user can select the API tab in that popup and get the POST request for a job launch:
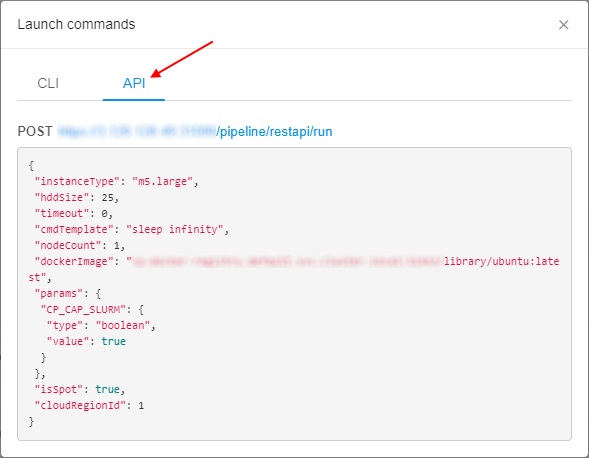
See an example here.
pipe CLI: view tools definitions
In v0.16 the ability to view details of a tool/tool version or tools group via the CLI was implemented.
The general command to perform these operations:
pipe view-tools [OPTIONS]
Via the options users can specify a Docker registry (-r option), a tools group (-g option), a tool (-t option), a tool version (-v option) and view the corresponding information.
For example, to show a full tools list of a group:
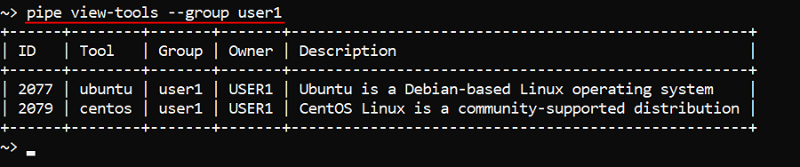
To show a tool definition with versions list:
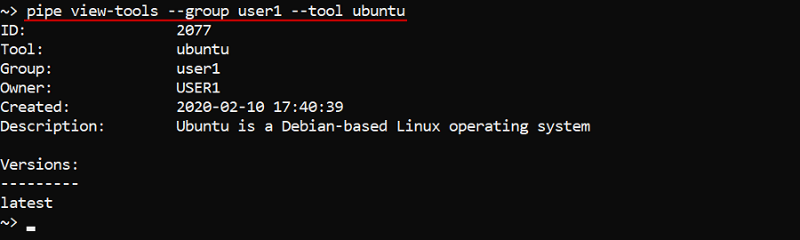
Also the specifying of "path" to the object (registry/group/tool) is supported. The "full path" format is: <registry_name>:<port>/<group_name>/<tool_name>:<verion_name>:
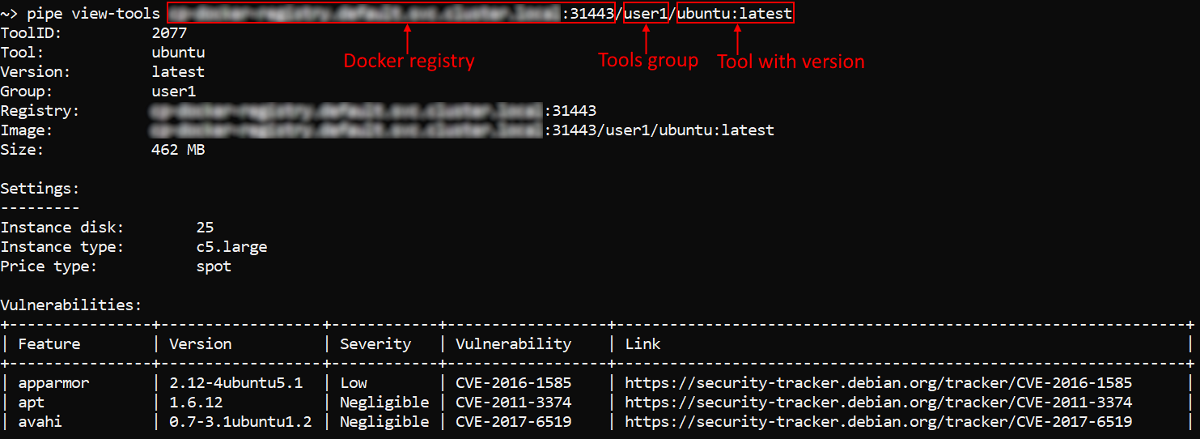
For more details and usage examples see here.
List the users/groups/objects permissions globally via pipe CLI
Administrators may need to receive the following information - in a quick and convenient way:
- Which objects are accessible by a user?
- Which objects are accessible by a user group?
- Which user(s)/group(s) have access to the object?
The lattest case was implemented early - see the command pipe view-acl.
For other cases, new commands were implemented: pipe view-user-objects <Username> [OPTIONS] and pipe view-group-objects <Groupname> [OPTIONS] - to get a list of objects accessible by a user and by a user group/role respectively:
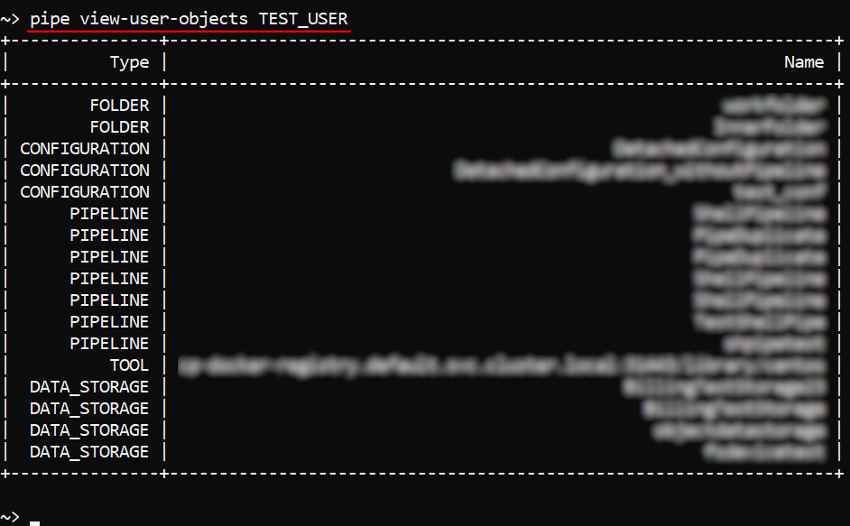
Each of these commands has the non-required option -t (--object-type) <OBJECT_TYPE> - to restrict the output list of accessible objects only for the specific type (e.g., "pipeline" or "tool", etc.):
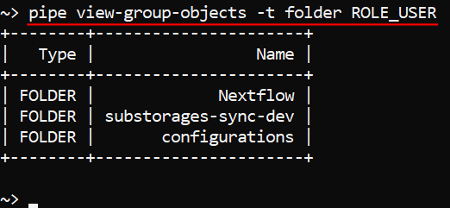
For more details see: pipe view-user-objects and pipe view-group-objects.
Storage usage statistics retrieval via pipe
In some cases, it may be necessary to obtain an information about storage usage or some inner folder(s).
In the current version, the command pipe storage du is implemented that provides "disk usage" information on the supported data storages/path:
- number of files in the storage/path
- summary size of the files in the storage/path
In general, the command has the following format:
pipe storage du [OPTIONS] [STORAGE]
Without specifying any options and storage this command prints the full list of the available storages (both types - object and FS) with the "usage" information for each of them.
With specifying the storage name this command prints the "usage" information only by that storage, e.g.:

With -p (--relative-path) option the command prints the "usage" information for the specified path in the required storage, e.g.:

With -d (--depth) option the command prints the "usage" information in the required storage (and path) for the specified folders nesting depth, e.g.:

For more details about that command and full list of its options see here.
GE Autoscaler respects CPU requirements of the job in the queue
At the moment, GE Autoscaler treats each job in the queue as a single-core job.
Previously, autoscale workers could have only fixed instance type (the same as the master) - that could lead to unschedulable jobs in the queue - for examle, if one of the jobs requested 4 slots in the local parallel environment within a 2-cored machine. Described job waited in a queue forever (as autoscaler could setup only new 2-cored nodes).
In the current version the hybrid behavior for the GE Autoscaler was implemented, that allows processing the data even if the initial node type is not enough. That behavior allows to scale-up the cluster (attach a worker node) with the instance type distinct of the master - worker is being picked up based on the amount of unsatisfied CPU requirements of all pending jobs (according to required slots and parallel environment types).
To enable hybrid mode for auto-scaled cluster set the corresponding checkbox in the cluster settings before the run:
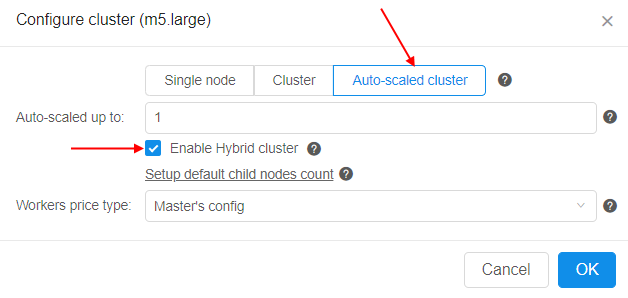
On the other hand, there are several System parameters to configure hybrid behavior in details:
CP_CAP_AUTOSCALE_HYBRID(boolean) - enables thehybridmode (the same as the "Enable Hybrid cluster" checkbox setting). In that mode the additional worker type can vary within either master instance type family (orCP_CAP_AUTOSCALE_HYBRID_FAMILYif specified). Ifdisabledor not specified - the GE Autoscaler will work in a general regimen (when scaled-up workers have the same instance type as the master node)CP_CAP_AUTOSCALE_HYBRID_FAMILY(string) - defines the instance "family", from which the GE Autoscaler should pick up the worker node in case ofhybridbehavior. If not specified (by default) - the GE Autoscaler will pick up worker instance from the same "family" as the master nodeCP_CAP_AUTOSCALE_HYBRID_MAX_CORE_PER_NODE(string) - determines the maximum number of instance cores for the node to be scaled up by the GE Autoscaler in case ofhybridbehavior
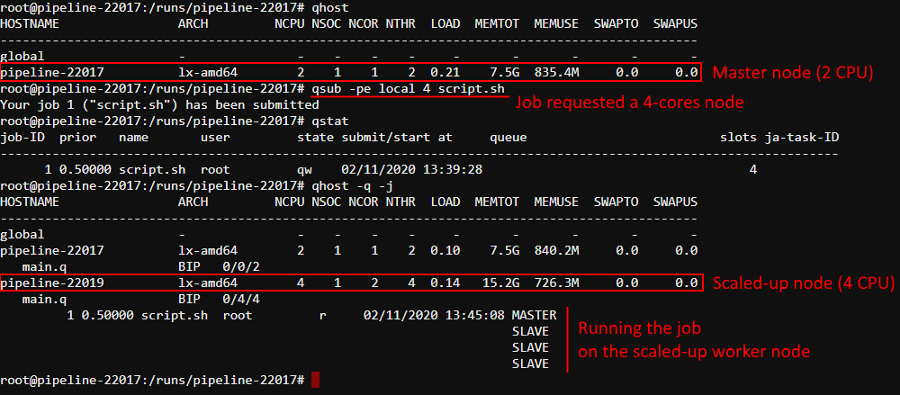
Also now, if no matching instance is present for the job (no matter - in hybrid or general regimen), GE Autoscaler logs error message and rejects such job:
for example, when try to request 32 slots for the autoscaled cluster launched in hybrid mode with the parameter CP_CAP_AUTOSCALE_HYBRID_MAX_CORE_PER_NODE set to 20:

and in the logs console at the same time:

For more details about GE Autoscaler see here.
Restrictions of "other" users permissions for the storages mounted via the pipe storage mount command
As was introduced in Release Notes v.0.15, the ability to mount Cloud data storages (both - File Storages and Object Storages) to Linux and Mac workstations (requires FUSE installed) was added.
For that, the pipe storage mount command was implemented.
Previously, Cloud Pipeline allowed read access to the mounted cloud storages for the other users, by default. This might introduce a security issue when dealing with the sensitive data.
In the current version, for the pipe storage mount command the new option is added: -m (--mode), that allows to set the permissions on the mountpoint at a mount time.
Permissions are being configured by the numerical mask - similarly to chmod Linux command.
E.g. to mount the storage with RW access to the OWNER, R access to the GROUP and no access to the OTHERS:

If the option -m isn't specified - the default permission mask will be set - 700 (full access to the OWNER (RWX), no access to the GROUP and OTHERS).
For more details about mounting data storages via the pipe see here.
The ability to find the tool by its version/package name
Cloud Pipeline allows searching for the tools in the registry by its name or description. But in some cases, it is more convenient and useful to find which tool contains a specific software package and then use it.
In the current version, this ability - to find a tool by its content - is implemented based on the global search capabilities.
Now, via the Global Search, you may find a tool by its version name, e.g.:
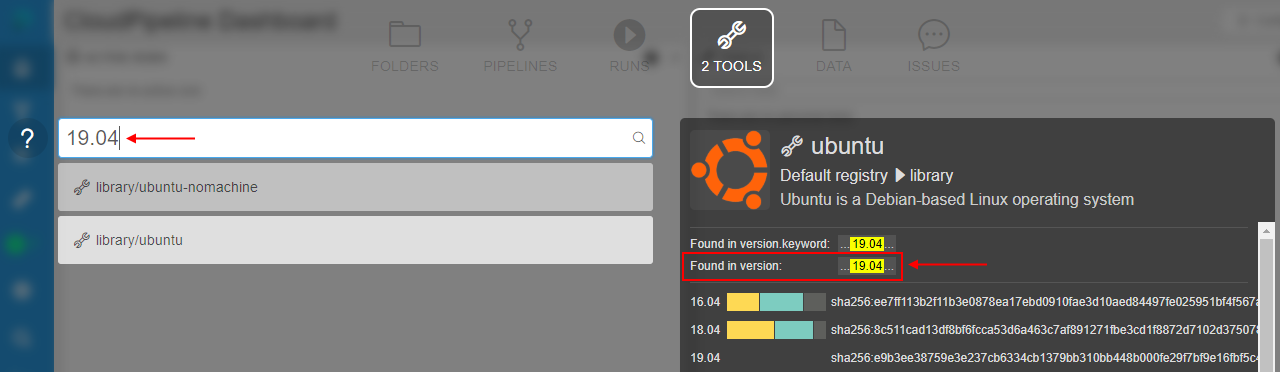
And by the package name (from any available ecosystem), e.g.:
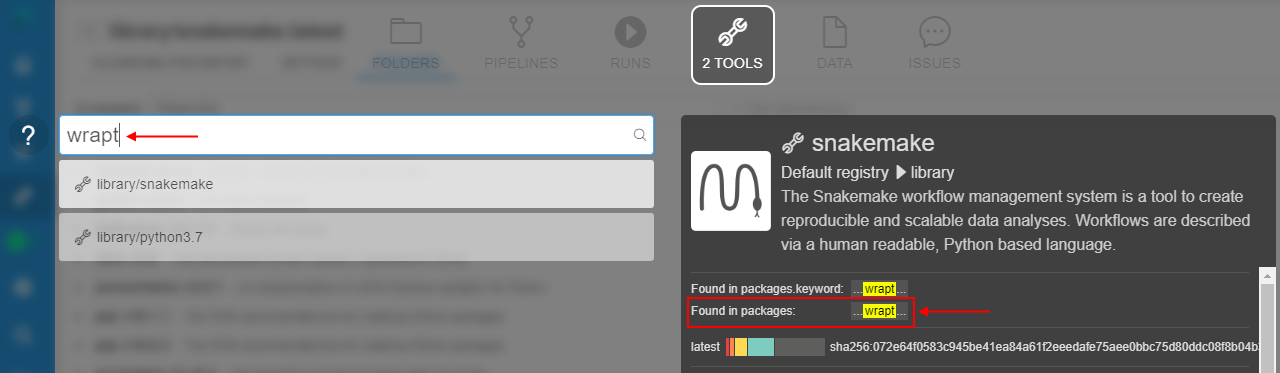
The ability to restrict which run statuses trigger the email notification
Cloud Pipeline can be configured to send the email to the owner of the job (or specific users) if its status is changed.
But in certain cases - it is not desired to get a notification about all changes of the run state.
To reduce a number of the emails in these cases, the ability to configure, which statuses are triggering the notifications, is implemented in v0.16.
Now, when the administrator configures the emails sending linked to the run status changes - he can select specific run states that will trigger the notifications.
It is done through the PIPELINE_RUN_STATUS section at the Email notifications tab of the System Settings (the "Statuses to inform" field):
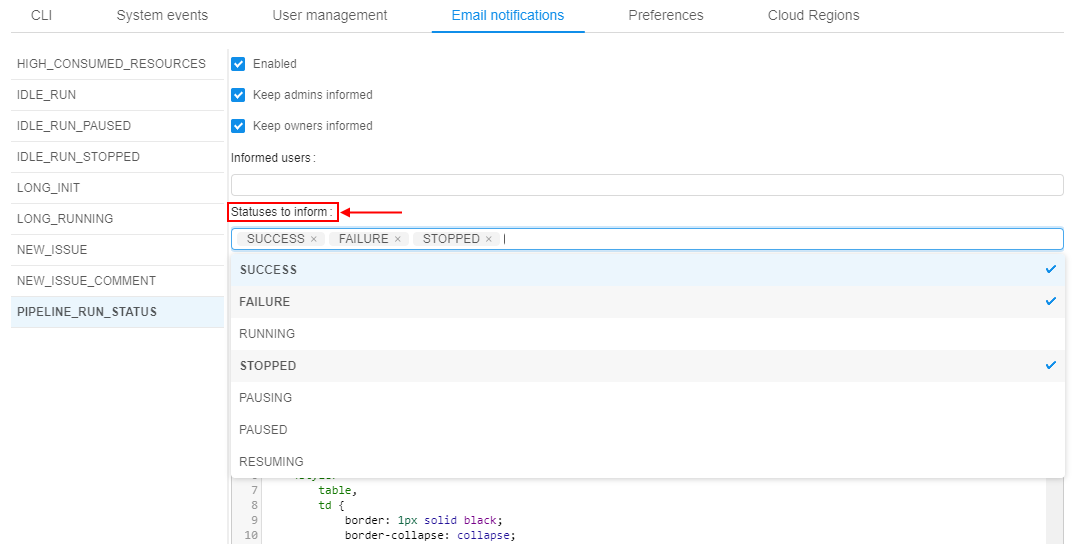
The email notifications will be sent only if the run enters one of the selected states.
Note: if no statuses are selected in the "Statuses to inform" field - email notifications will be sent as previously - for all status changes.
For more information how to configure the email notifications see here.
The ability to force the usage of the specific Cloud Provider/Region for a given image
Previously, the platform allowed to select a Cloud Provider (and Cloud Region) for a particular job execution via the Launch Form, but a tool/version itself didn't not have any link with a region.
In certain cases, it's necessary to enforce users to run some tools in a specific Cloud Provider/Region.
In the current version, such ability was implemented. The Tool/Version Settings forms contain the field for specifying a Cloud Region, e.g.:
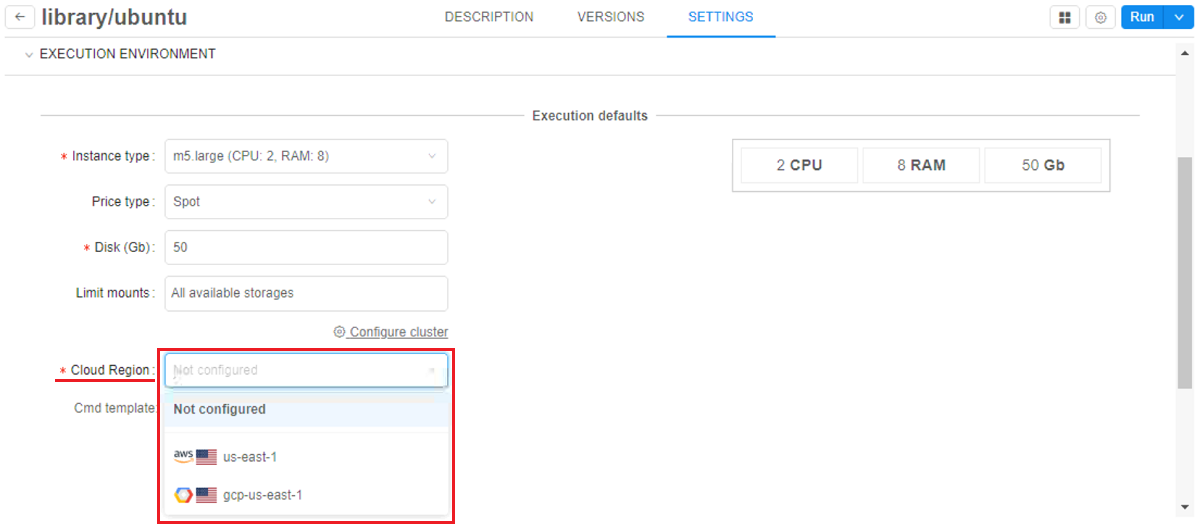
By default, this parameter has Not configured value. This means, that a tool will be launched in a Default region (configured by the Administrator in the global settings). Or a user can set any allowed Cloud Region/Provider manually. This behavior will be the same as previously.
- Admin or a tool owner can forcibly set a specific Cloud Region/Provider where the run shall be launched, e.g.:
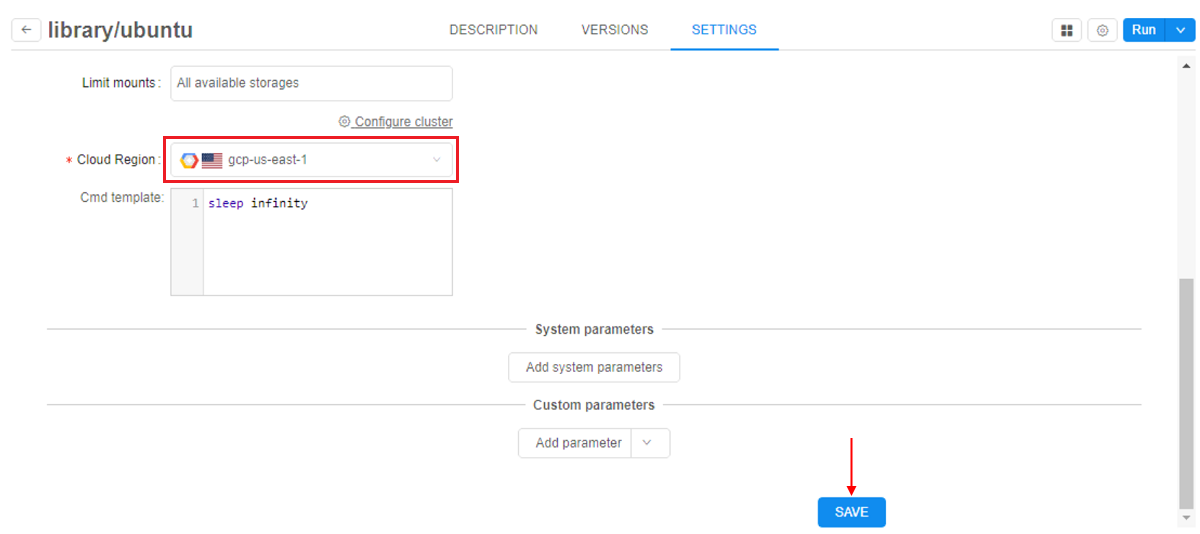
- Then, if a specific Cloud Region/Provider is configured - users will have to use it, when launching a tool (regardless of how the launch was started - with default or custom settings):
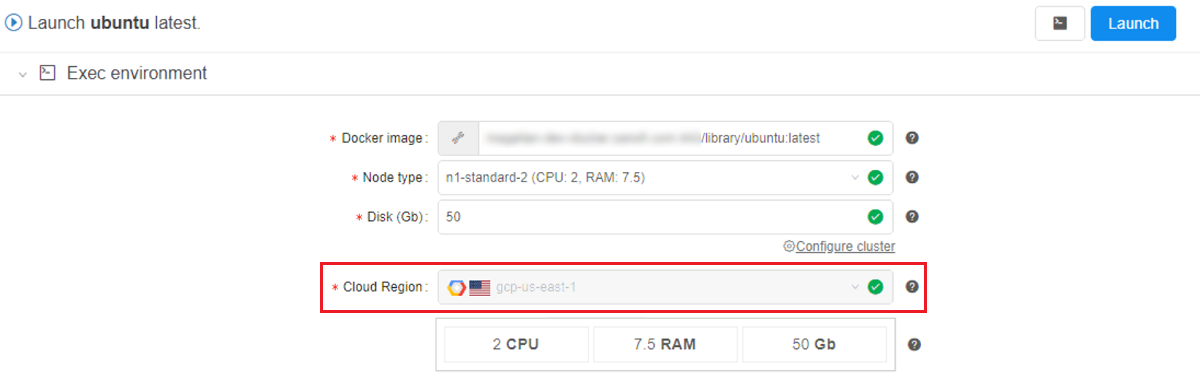
- And if a user does not have access to that Cloud Region/Provider - tool won't launch:

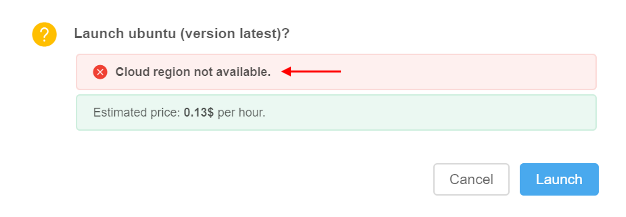
Note: if a specific Cloud Region/Provider is being specified for the Tool, in general - this action enforce the Region/Provider only for the latest version of that tool. For other versions the settings will remain previous.
See for more details about tool execution settings here. See for more details about tool version execution settings here.
Restrict mounting of data storages for a given Cloud Provider
Previously, Cloud Pipeline attempted to mount all data storages available for the user despite the Cloud Providers/Regions of these storages. E.g. if a job was launched in the GCP, but the user has access to AWS S3 buckets - they were also mounted to the GCP instance.
In the current version, the ability to restrict storage mount availability for a run, based on its Cloud Provider/Region, was implemented.
Cloud Regions system configuration now has a separate parameter "Mount storages across other regions":
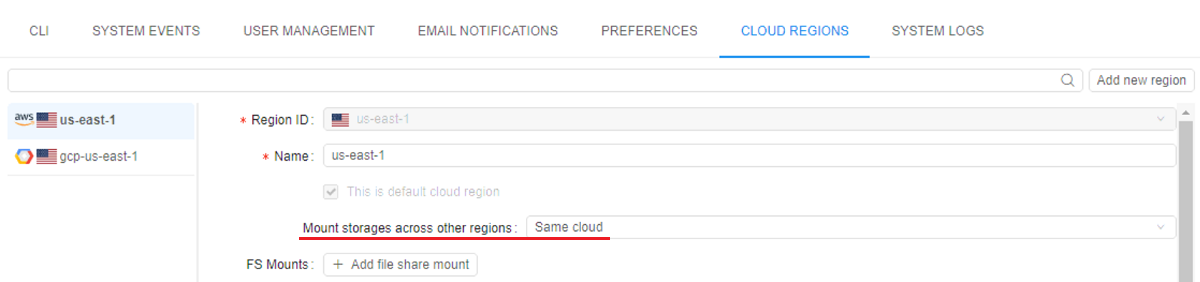
This parameter has 3 possible values:
None- if set, storages from this region will be unavailable for a mount to any jobs. Such storages will not be available even to the same regions (e.g. storage fromAWS us-east-1will be unavailable for a mount to instances launched inAWS eu-central-1or anyGCPregion and even inAWS us-east-1)Same Cloud- if set, storages from this region will be available only to different Cloud Regions of the same Cloud Provider (e.g. storage fromAWS us-east-1will be available to instances launched inAWS eu-central-1too, but not in anyGCPregion)All- if set, storages from this region will be available to all other Cloud Regions/Providers
Ability to "symlink" the tools between the tools groups
The majority of the tools are managed by the administrators and are available via the library tool group.
But for some of the users it would be convenient to have separate tool groups, which are going to contain a mix of the custom tools (managed by the users themselves) and the library tools (managed by the admins).
For the latter ones the ability to create "symlinks" into the other tool groups was implemented.
"Symlinked" tools are displayed in that users' tool groups as the original tools but can't be edited/updated. When a run is started with "symlinked" tool as docker image it is being replaced with original image for Kubernetes pod spec.
Example of the "symlinked" ubuntu tool:
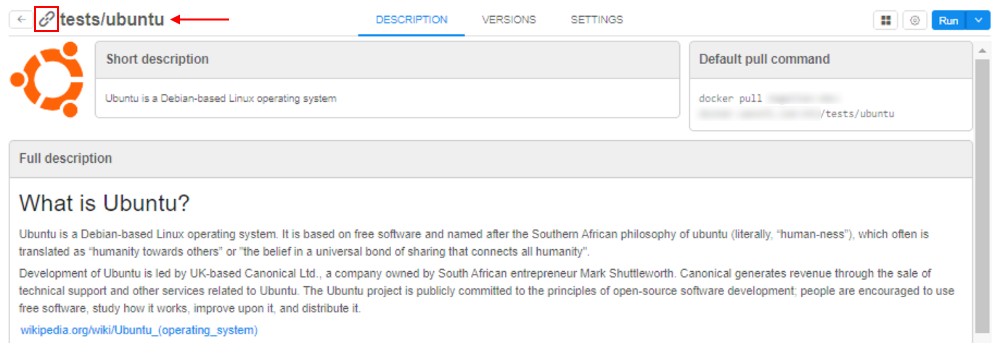
The following behavior is implemented:
- to create a "symlink" to the tool, the user shall have READ access to the source tool and WRITE access to the destination tool group
- for the "symlinked" tool all the same description, icon, settings as in the source image are displayed. It isn't possible to make any changes to the "symlink" data (description, icon, settings. attributes, issues, etc.), even for the admins
- admins and image OWNERs are able to manage the permissions for the "symlinks". Permissions on the "symlinked" tools are configured separately from the original tool
- two levels of "symlinks" is not possible ("symlink" to the "symlinked" tool can't be created)
- it isn't possible to "push" into the "symlinked" tool
For more details see here.
Notable Bug fixes
Parameter values changes cannot be saved for a tool
Previously, if a user changed only the parameter value within a tool's settings form - the SAVE button stayed still unavailable. One had to modify some other option (e.g. disk size) to save the overall changes.
Packages are duplicated in the tool's version details
Previously, certain tools packages were duplicated in the PACKAGES details page of the tools version.
Autoscaling cluster can be autopaused
Previously, when users launched auto-scaled clusters without default child-nodes and the PAUSE action was specified as action for the "idle" run (via system-levels settings), such cluster runs could be paused. Any cluster runs shall not have the ability to be paused, only stopped.
pipe: not-handled error while trying to execute commands with invalid config
Previously, if pipe config contained some invalid data (e.g. outdated or invalid access token), then trying to execute any pipe command had been causing an not-handled error.
Setting of the tool icon size
Previously, setting of any value for the maximum tool's icon size via the sytem-level preference misc.max.tool.icon.size.kb didn't lead to anything - restriction for the size while trying to change an icon was remaining the same - 50 Kb.
NPE while building cloud-specific environment variables for run
For each run a set of cloud-specific environment variables (including account names, credentials, etc.) is build. This functionality resulted to fails with NPE when some of these variables are null.
Now, such null variables are filtered out with warn logs.
Worker nodes fail due to mismatch of the regions with the parent run
In certain cases, when a new child run was launching in cluster, cloud region was not specified directly and it might be created in a region differing from the parent run, that could lead to fails.
Now, worker runs inherit parent's run cloud region.
Worker nodes shall not be restarted automatically
Cloud Pipeline has a functionality to restart so called batch job runs automatically when run is terminated due to some technical issues, e.g. spot instance termination. Previously, runs that were created as child nodes for some parent run were also restarted.
Now, automatically child reruns for the described cases with the batch job runs are rejected.
Uploaded storage file content is downloaded back to client
Cloud Pipeline clients use specific POST API method to upload local files to the cloud storages. Previously, this method not only uploaded files to the cloud storage but also mistakenly returned uploaded file content back to the client. It led to a significant upload time increase.
GUI improperly works with detached configurations in a non-default region
Saved instance type of a non-default region in a detached configuration wasn't displayed in case when such configuration was reopened (instance type field was displayed as empty in that cases).
Detached configuration doesn't respect region setting
Region setting was not applied when pipeline is launched using detached configuration.
Now, cloud region ID is merged into the detached configuration settings.
Incorrect behavior of the "Transfer to the cloud" form in case when a subfolder has own metadata
Previously, when you tried to download files from external resources using metadata (see here) and in that metadata's folder there was any subfolder with its own metadata - on the "Transfer to the Cloud" form attributes (columns) of both metadata files were mistakenly displaying.
Incorrect displaying of the "Start idle" checkbox
If for the configuration form with several tabs user was setting the Start idle checkbox on any tab and then switched between sub-configurations tabs - the "checked" state of the Start idle checkbox didn't change, even if Cmd template field was appearing with its value (these events are mutually exclusive).
Limit check of the maximum cluster size is incorrect
Maximum allowed number of runs (size of the cluster) created at once is limited by system preference launch.max.scheduled.number. This check used strictly "less" check rather then "less or equal" to allow or deny cluster launch.
Now, the "less or equal" check is used.
Fixed cluster with SGE and DIND capabilities fails to start
Previously, fixed cluster with both CP_CAP_SGE and CP_CAP_DIND_CONTAINER options enabled with more than one worker failed to start. Some of the workers failed on either SGEWorkerSetup or SetupDind task with different errors. Scripts were executed in the same one shared analysis directory. So, some workers could delete files downloaded by other workers.
Azure: Server shall check Azure Blob existence when a new storage is created
During the creation of AZ Storage, the validation whether Azure Blob exists or not didn't perform. In that case, if Azure Blob had already existed, the user was getting failed request with Azure exception.
Azure: pipe CLI cannot transfer empty files between storages
Previously, empty files couldn't be transferred within a single Azure storage or between two Azure storages using pipe CLI, it throwed an error. So for example, a folder that contained empty files couldn't be copied correctly.
Azure: runs with enabled GE autoscaling doesn't stop
All Azure runs with enabled GE autoscaling were stuck after the launch.sh script has finished its execution. Daemon GE autoscaler process kept container alive. It was caused by the run process stdout and stderr aren't handled the same way for different Cloud Provider. So background processes launched from launch.sh directly could prevent Azure run finalization.
Incorrect behavior while download files from external resources into several folders
If user was tried to download files from external resources and at the Transfer settings form was set Create folders for each path field checkbox without setting any name field, all files downloaded into one folder without creating folders for each path field (column).
Detach configuration doesn't setup SGE for a single master run
Grid Engine installation was mistakenly being skipped, if pipeline was launched with enabled system parameter CP_CAP_SGE via a detach configuration.
Broken layouts
Previously, pipeline versions page had broken layout if there "Attributes" and "Issues" panels were simultaneously opened.
If there were a lot of node labels at the Cluster nodes page, some of them were "broken" and spaced to different lines.
Some of the other page layouts also were broken.