12.10. Manage system-level settings
User shall have ROLE_ADMIN to read and update system-level settings.
- Read system-level settings
- Make system-level settings visible to all users
- Update system-level settings
Read system-level settings
- Hover to the Settings tab.
- Select the Preferences section.
- All system-level parameters are categorized into the several groups.
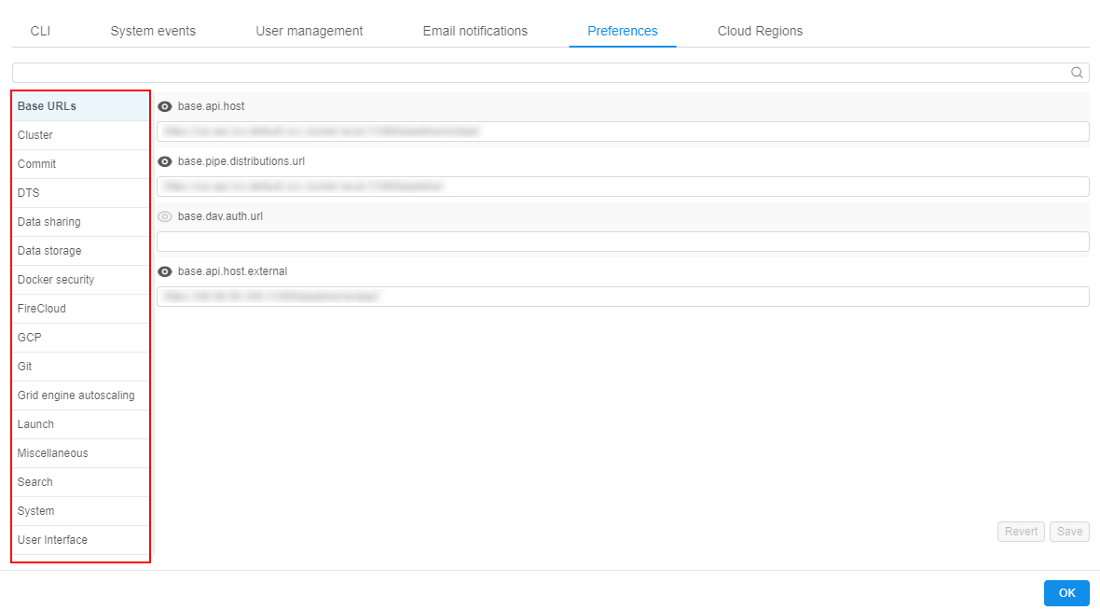
Base URLs
These settings define pipeline URLs:
| Setting name | Description |
|---|---|
base.invalidate.edge.auth.path |
|
base.api.host |
REST API endpoint |
base.pipe.distributions.url |
URL that is used to download pipeline scripts |
base.cloud.data.distribution.url |
URLs that are used to download Cloud Data app distribution |
base.dav.auth.url |
|
base.api.host.external |
REST API external endpoint |
Billing Reports
These settings define parameters of Billing reports pages displaying:
| Setting name | Description |
|---|---|
billing.reports.enabled |
Defines whether "general" users can access personal billing information - runs/storages where the user is an owner |
billing.reports.enabled.admins |
Defines whether admins and users with the ROLE_BILLING_MANAGER role can have full access to the Billing reports |
billing.reports.user.name.attribute |
Defines which user's attribute is used to display the users in the Billing reports (charts, tables, export reports) |
Cluster
Settings in this tab define different cluster options:
| Setting name | Description |
|---|---|
instance.compute.family.names |
|
instance.dns.hosted.zone.base |
|
instance.dns.hosted.zone.id |
|
instance.limit.state.reasons |
|
instance.offer.update.rate |
How often instance cost is calculated (in milliseconds) |
instance.restart.state.reasons |
Instance status codes, upon receipt of which an instance tries automatically to restart |
cluster.instance.device.prefix |
|
cluster.instance.device.suffixes |
|
cluster.instance.type |
Default instance type |
cluster.instance.hdd |
Default hard drive size for instance (in gigabytes) |
cluster.instance.hdd_extra_multi |
Disk extra multiplier. Allows to add extra space, during a launch, to the disk size selected through the GUI. The size of that extra space is calculated as (Unarchived docker image size) * (Disk extra multiplier) |
cluster.instance.hdd.scale.enabled |
|
cluster.instance.hdd.scale.delta.ratio |
|
cluster.instance.hdd.scale.monitoring.delay |
|
cluster.instance.hdd.scale.max.devices |
|
cluster.instance.hdd.scale.max.size |
|
cluster.instance.hdd.scale.disk.max.size |
|
cluster.instance.hdd.scale.disk.min.size |
|
cluster.instance.hdd.scale.threshold.ratio |
|
cluster.keep.alive.minutes |
If node doesn't have a running pipeline on it for that amount of minutes, it will be shut down |
cluster.keep.alive.policy |
|
cluster.random.scheduling |
If this property is true, pipeline scheduler will rely on Kubernetes order of pods, otherwise pipelines will be ordered according to their parent (batch) ID |
cluster.reassign.disk.delta |
This delta sets the max possible difference that could be between the disk size of the node from the hot pool and the real disk size requested by the user for a job |
cluster.max.size |
Maximal number of nodes to be launched simultaneously |
cluster.min.size |
Minimal number of nodes to be launched at a time |
cluster.allowed.instance.types |
Allowed instance types. Can restrict available instance types for launching tools, pipelines, configurations |
cluster.allowed.instance.types.docker |
Allowed instance types for docker images (tools). Can restrict available instance types for launching tools. Has a higher priority for a tool than cluster.allowed.instance.types |
cluster.allowed.price.types |
Allowed price types. Can restrict available price types for launching tools, pipelines, configurations |
cluster.allowed.price.types.master |
Allowed price types for the cluster master node. Can restrict available price types for the master node of the cluster while launching tools, pipelines, detach configurations |
cluster.enable.autoscaling |
Enables/disables Kubernetes autoscaler service |
cluster.networks.config |
Config that contains information to start new nodes in Cloud Provider |
cluster.batch.retry.count |
Count of automatically retries to relaunch a job, if one of the instance status codes from instance.restart.state.reasons returns, when a batch job fails |
cluster.autoscale.rate |
How often autoscaler checks what tasks are executed on each node (in milliseconds) |
cluster.monitoring.elastic.minimal.interval |
|
cluster.monitoring.elastic.intervals.number |
|
cloud.provider.default |
Sets a default CLoud Provider |
cluster.docker.extra_multi |
Docker image extra multiplier. Allows to get an approximate size of the unarchived docker image. That size is calculated as (Archived docker image size) * (Docker image extra multiplier) |
cluster.kill.not.matching.nodes |
If this property is true, any free node that doesn't match configuration of a pending pod will be scaled down immediately, otherwise it will be left until it will be reused or expired. If most of the time we use nodes with the same configuration set this to true |
cluster.spot |
If this is true, spot instances will be launched by default |
cluster.spot.alloc.strategy |
Parameter that sets the strategy of calculating the price limit for instance:
|
cluster.spot.bid.price |
The maximum price per hour that you are willing to pay for a Spot Instance. The default is the On-Demand price |
cluster.spot.max.attempts |
|
cluster.nodeup.max.threads |
Maximal number of nodes that can be started simultaneously |
cluster.nodeup.retry.count |
Maximal number of tries to start the node |
cluster.high.non.batch.priority |
If this property is true, pipelines without parent (batch ID) will have the highest priority, otherwise - the lowest |
Commit
This tab contains various commit settings:
| Setting name | Description |
|---|---|
commit.pre.command.path |
Specifies a path to a script within a docker image, that will be executed in a currently running container, before docker commit occurs |
commit.username |
Git username |
commit.deploy.key |
Used to SSH for COMMIT. Key is stored in a DB |
commit.timeout |
Commit will fail if exceeded (in seconds) |
commit.post.command.path |
Specifies a path to a script within a docker image, that will be executed in a committed image, after docker commit occurs |
commit.container.size.limits |
Defines "soft" and "hard" limits for a container size in bytes. If during the commit operation container size exceeds "soft" limit, user will get warning notification. If container size exceeds "hard" limit, commit operation for such tool will be unavailable |
pause.timeout |
DTS
These settings define DTS parameters:
| Setting name | Description |
|---|---|
dts.launch.cmd |
|
dts.launch.script.url |
|
dts.dist.url |
Data Sharing
These settings define data sharing parameters:
| Setting name | Description |
|---|---|
data.sharing.base.api |
Specifies a format of the generating URL to the data storage with enabled sharing |
data.sharing.disclaimer |
Allows to set a warning text for the "Share storage link" pop-up |
Data Storage
These settings define storage parameters:
| Setting name | Description |
|---|---|
storage.mounts.per.gb.ratio |
This preference allows to specify the "safe" number of storages per Gb of RAM. When launching a job - the user's available object storages count is being calculated and checked that it does not exceed selected instance type RAM value multiplied by this preference value. If it's exceeded - the user is being warned |
storage.mounts.nfs.sensitive.policy |
|
storage.fsbrowser.enabled |
Allows to enable FSBrowser |
storage.fsbrowser.black.list |
List of directories/files which shall not be visible via FSBrowser |
storage.fsbrowser.wd |
Allows to set a work directory for FSBrowser (this directory will be opened by default and set as root) |
storage.fsbrowser.transfer |
Allows to specify intermediate object storage for data transfer operations in FSBrowser (this is actual for "heavy" transfer operations to not reduce performance) |
storage.fsbrowser.port |
Allows to set a port for FSBrowser |
storage.fsbrowser.tmp |
A path to the directory where the temporary archive shall be created (when the folder is downloading). Archive is being removed when download is finished |
storage.incomplete.upload.clean.days |
|
storage.user.home.auto |
Controls whether the home storages will be created automatically for new users |
storage.webdav.access.duration.seconds |
Period duration for which user can request the file system access to the storage |
storage.user.home.template |
Describes a template that shall be used for the automatic home storage creation for new users |
storage.temp.credentials.duration |
Temporary credentials lifetime for Cloud Provider's operations with data storages (in seconds) |
storage.transfer.pipeline.id |
Pipeline ID that is used to automated data transfers from the external sites |
storage.system.run.shared.storage.name |
|
storage.system.run.shared.folder.pattern |
|
storage.system.storage.name |
Configures a system data storage for storing attachments from e.g. issues |
storage.mount.black.list |
List of directories where Data Storages couldn't be mounted |
storage.transfer.pipeline.version |
Pipeline version that is used to automated data transfers from the external sites |
storage.max.download.size |
Chunk size to download (bytes) |
storage.object.prefix |
A mandatory prefix for the new creating data storages |
storage.operations.bulk.size |
|
storage.listing.time.limit |
Sets the timeout (in milliseconds) for the processing of the size getting for all input/common files before the pipeline launch. Default: 3000 milliseconds (3 sec). If computation of the files size doesn't end in this timeout, accumulated size will return as is |
profile.temp.credentials.duration |
|
storage.quotas.actions.grace.period |
Allows to specify grace periods for both states: MOUNT DISABLED and READ ONLY FS quota-related processes. If that preference is specified - corresponding actions for FS quotas will be delayed. Values are specified in minutes. |
storage.quotas.skipped.paths |
Allows to specify which storages/paths shall be excluded from the FS quota-related processing. |
Docker security
This tab contains settings related to Docker security checks:
| Setting name | Description |
|---|---|
security.tools.scan.all.registries |
If this is true, all registries will be scanned for Tools vulnerability |
security.tools.scan.clair.root.url |
Clair root URL |
security.tools.docker.comp.scan.root.url |
|
security.tools.jwt.token.expiration |
|
security.tools.scan.clair.connect.timeout |
Sets timeout for connection with Clair (in seconds) |
security.tools.os |
|
security.tools.policy.max.high.vulnerabilities |
Denies running a Tool if the number of high vulnerabilities exceeds the threshold. To disable the policy, set to -1 |
security.tools.grace.hours |
Allows users to run a new docker image (if it is not scanned yet) or an image with a lot of vulnerabilities during a specified period. During this period user will be able to run a tool, but an appropriate message will be displayed. Period lasts from date/time since the docker version became vulnerable or since the docker image's push time (if this version was not scanned yet) |
security.tools.scan.clair.read.timeout |
Sets timeout for Clair response (in seconds) |
security.tools.policy.deny.not.scanned |
Allow/deny execution of unscanned Tools |
security.tools.scan.enabled |
Enables/disables security scan |
security.tools.policy.max.medium.vulnerabilities |
Denies running a Tool if the number of medium vulnerabilities exceeds the threshold. To disable the policy, set to -1 |
security.tools.policy.max.critical.vulnerabilities |
Denies running a Tool if the number of critical vulnerabilities exceeds the threshold. To disable the policy, set to -1 |
security.tools.scan.schedule.cron |
Security scan schedule |
Faceted Filter
These settings define parameters of the faceted filters at the "Advanced search" form:
| Setting name | Description |
|---|---|
faceted.filter.dictionaries |
Allows to specify system dictionaries that should be used as faceted filters. Additionally can be specified: filter (dictionary) order in the "Faceted filters" panel, default count of filters entries to display |
FireCloud
These settings define FireCloud parameters:
| Setting name | Description |
|---|---|
google.client.settings |
|
firecloud.base.url |
|
firecloud.billing.project |
|
google.client.id |
|
firecloud.launcher.cmd |
|
firecloud.instance.disk |
|
firecloud.launcher.tool |
|
google.redirect.url |
|
firecloud.api.scopes |
|
firecloud.instance.type |
|
firecloud.enable.user.auth |
GCP
These settings define specific Google Cloud Platform parameters:
| Setting name | Description |
|---|---|
gcp.sku.mapping |
|
gcp.regions.list |
Git
These settings define Git parameters:
| Setting name | Description |
|---|---|
ui.git.cli.configure.template |
Template for the message of the Git config that would be displayed for user in the "Git CLI" section of the System Settings |
git.user.name |
User name to access Git with pipelines |
git.external.url |
|
git.fork.retry.count |
|
git.fork.wait.timeout |
|
git.repository.hook.url |
|
git.token |
Token to access Git with pipelines |
git.repository.indexing.enabled |
Allows to enable the indexing of Git repository with pipelines |
git.reader.service.host |
|
git.user.id |
User id to access Git with pipelines |
git.host |
IP address where Git service is deployed |
Grid engine autoscaling
See Appendix C. Working with autoscaled cluster runs for details.
These settings define auto-scaled cluster parameters:
| Setting name | Description |
|---|---|
ge.autoscaling.scale.down.timeout |
If jobs queue is empty or all jobs are running and there are some idle nodes longer than that timeout in seconds - auto-scaled cluster will start to drop idle auto-scaled nodes ("scale-down") |
ge.autoscaling.scale.up.to.max |
|
ge.autoscaling.scale.up.timeout |
If some jobs are in waiting state longer than that timeout in seconds - auto-scaled cluster will start to attach new computation nodes to the cluster ("scale-up") |
ge.autoscaling.scale.up.polling.timeout |
Defines how many seconds GE autoscaler should wait for pod initialization and run initialization |
Launch
Settings in this tab contains default Launch parameters:
| Setting name | Description |
|---|---|
launch.kube.pod.search.path |
|
launch.kube.pod.domains.enabled |
|
launch.kube.pod.service |
|
launch.kube.pod.subdomain |
|
launch.kube.service.suffix |
|
launch.jwt.token.expiration |
Lifetime of a pipeline token (in seconds) |
launch.max.scheduled.number |
Controls maximum number of scheduled at once runs summary by all platform users |
launch.max.runs.user.global |
Controls maximum number of scheduled at once runs for a single user. I.e. if it set to 5, each Platform user can launch 5 jobs at a maximum |
launch.env.properties |
Sets of environment variables that will be passed to each running Tool |
launch.docker.image |
Default Docker image |
launch.cmd.template |
Default cmd template |
launch.container.cpu.resource |
|
launch.container.memory.resource.policy |
|
launch.container.memory.resource.request |
|
launch.insufficient.capacity.message |
Defines the text displayed in the run logs in case when an instance requested by the user is missing due to InsufficientInstanceCapacity error(means insufficient capacity in the selected Cloud Region) |
launch.run.visibility |
Allow to view foreign runs based on pipeline permissions (value INHERIT) or restrict visibility of all non-owner runs (value OWNER) |
launch.dind.enable |
Enables Docker in Docker functionality |
launch.dind.container.vars |
Allows to specify the variables, which will be passed to the DIND container (if they are set for the host environment) |
launch.dind.mounts |
List of mounts that shall be added to k8s pod for Docker in Docker |
launch.task.status.update.rate |
Sets task status update rate, on which application will query kubernetes cluster for running task status, ms. Pod Monitor |
launch.pods.release.rate |
|
launch.serverless.endpoint.wait.count |
|
launch.serverless.endpoint.wait.time |
|
launch.serverless.stop.timeout |
|
launch.serverless.wait.count |
|
launch.system.parameters |
System parameters, that are used when launching pipelines |
launch.tool.size.limits |
Defines "soft" and "hard" limits for a container size in bytes. If tool container size exceeds "soft" limit, user will get warning notification when trying to launch such a tool. If container size exceeds "hard" limit, launch of such a tool will be prohibited |
Lustre FS
These settings define Lustre FS parameters:
| Setting name | Description |
|---|---|
lustre.fs.default.throughput |
|
lustre.fs.mount.options |
|
lustre.fs.deployment.type |
|
lustre.fs.default.size.gb |
|
lustre.fs.backup.retention.days |
Miscellaneous
| Setting name | Description |
|---|---|
misc.metadata.sensitive.keys |
Allows to specify the list of the metadata that will not be exported during the users export operation |
misc.max.tool.icon.size.kb |
Sets maximum size (in Kb) of the uploaded icon for the tool |
system.events.confirmation.metadata.key |
Sets the KEY for the user's attribute displaying information about "blocking" notifications confirmation |
Monitoring
| Setting name | Description |
|---|---|
monitoring.archive.runs.enable |
Enables archiving mechanism for completed runs |
monitoring.archive.runs.delay |
Manipulates the frequency of archiving operations (in milliseconds). Operations of runs archiving are asynchronous and performed after each period of time specified via this preference |
Search
Settings in this tab contains Elasticsearch parameters:
| Setting name | Description |
|---|---|
search.aggs.max.count |
|
search.elastic.scheme |
|
search.elastic.allowed.users.field |
|
search.elastic.allowed.groups.field |
|
search.elastic.denied.users.field |
|
search.elastic.denied.groups.field |
|
search.elastic.type.field |
|
search.elastic.host |
|
search.elastic.index.type.prefix |
|
search.elastic.port |
|
search.elastic.search.fields |
|
search.elastic.index.common.prefix |
|
search.elastic.index.metadata.fields |
Allows to specify attributes keys which values will be shown in corresponding additional columns in table view of the search results of the "Advanced search" |
System
The settings in this tab contain parameters and actions that are performed depending on the system monitoring metrics:
| Setting name | Description |
|---|---|
system.archive.run.metadata.key |
Defines the name of the metadata key that shall be specified for users/groups which runs shall be archived |
system.archive.run.owners.chunk.size |
Defines the chunk size by which the data of completed runs to archive shall be divided. Data is divided by users count (runs owners count) |
system.archive.run.runs.chunk.size |
Defines the chunk size by which the data of completed runs to archive shall be divided. Data is divided by master runs count |
system.ssh.default.root.user.enabled |
Enables launch of the SSH terminal from the run under root-user access |
system.max.idle.timeout.minutes |
Specifies a duration in minutes. If CPU utilization is below system.idle.cpu.threshold for this duration - notification will be sent to the user and the corresponding run will be marked by the "IDLE" label |
system.idle.action.timeout.minutes |
Specifies a duration in minutes. If CPU utilization is below system.idle.cpu.threshold for this duration - an action, specified in system.idle.action will be performed |
system.resource.monitoring.period |
Specifies period (in seconds) between the users' instances scanning to collect the monitoring metrics |
system.monitoring.time.range |
Specifies time delay (in sec) after which the notification "HIGH_CONSUMED_RESOURCES" would be sent again, if the problem is still in place |
system.disk.consume.threshold |
Specifies disk threshold (in %) above which the notification "HIGH_CONSUMED_RESOURCES" would be sent and the corresponding run will be marked by the "PRESSURE" label |
system.idle.cpu.threshold |
Specifies percentage of the CPU utilization, below which action shall be taken |
system.resource.monitoring.stats.retention.period |
Specifies the time period (in days) during which resources utilization data is stored |
system.memory.consume.threshold |
Specifies memory threshold (in %) above which the notification "HIGH_CONSUMED_RESOURCES" would be sent and the corresponding run will be marked by the "PRESSURE" label |
system.idle.action |
Sets which action to perform on the instance, that showed low CPU utilization (that is below system.idle.cpu.threshold):
|
system.long.paused.action |
Sets which action to perform on the instance, that is in the "paused" state for a long time:
|
system.notifications.exclude.instance.types |
Defines a list of node types. If a job runs on any node from that list - IDLE_RUN, LONG_PAUSED, LONG_RUNNING email notifications will not be submitted for that job |
system.external.services.endpoints |
|
system.log.line.limit |
|
system.access.code.monitor.enable |
[Refers to pipe CLI code authorization]Enables monitoring that automatically removes old authorization codes. |
system.access.code.monitor.delay |
[Refers to pipe CLI code authorization]Delay for monitoring that automatically removes old authorization codes. |
system.access.allowed.code.challenge.methods |
[Refers to pipe CLI code authorization]Sets authorization code challenge method. |
system.access.code.length |
[Refers to pipe CLI code authorization]Sets authorization code length. |
system.access.code.ttl.minutes |
[Refers to pipe CLI code authorization]Sets the period during which the authorization code is valid. |
System Jobs
Here settings for System jobs can be found:
| Setting name | Description |
|---|---|
system.jobs.pipeline.id |
The ID of the prepared system pipeline that contains system jobs scripts |
system.jobs.scripts.location |
The path to the system scripts directory inside the pipeline code. Default value is src/system-jobs |
system.jobs.output.pipeline.task |
The name of the task at the Run logs page of the system pipeline that is launched for the system job. Task contains system job output results. Default value is SystemJob |
User Interface
Here different user interface settings can be found:
| Setting name | Description |
|---|---|
ui.pipeline.deployment.name |
UI deployment name |
ui.launch.command.template |
|
ui.hidden.objects |
|
ui.library.drag |
|
ui.pipe.cli.install.template |
CLI install templates for different operating systems |
ui.pipe.file.browser.app |
|
ui.pipe.drive.mapping |
|
ui.project.indicator |
These attributes define a Project folder |
ui.pipe.cli.configure.template |
CLI configure templates for different operating systems |
ui.support.template |
Markdown-formatted text that will be displayed in tooltip of the "support" info in the main menu. If nothing is specified (empty), support icon in the main menu will not be displayed |
ui.controls.settings |
JSON file that contains control settings |
Make system-level settings visible to all users
- Hover to the Settings tab.
- Select the Preferences section.
- Choose one of the tabs with system level settings (e.g. Grid engine autoscaling).
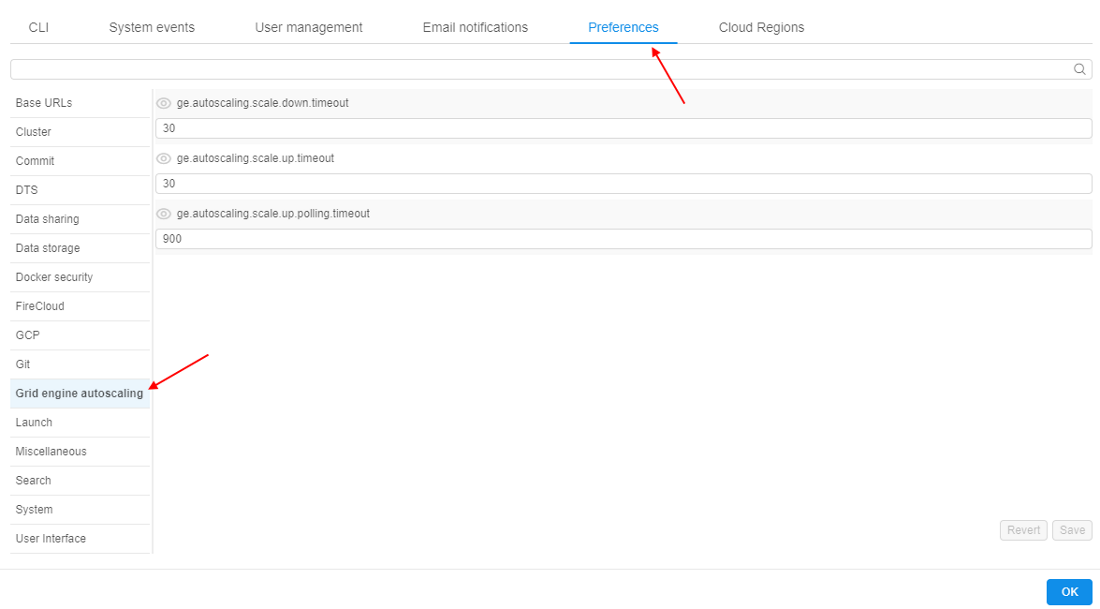
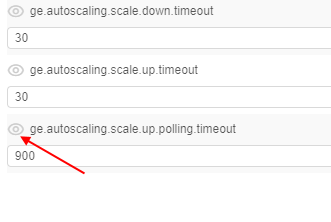
- Press the "Eye" button near any setting. Now it will be visible to all users by using the API.
Note: press "Eye" button again to hide it from all users.
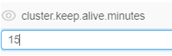
Update system-level settings
- Choose any system-level setting and change its value (e.g. change
cluster.keep.alive.minutes valuefrom 10 to 15).
- Press the Save button.
Note: before saving you can press the Revert button to return setting's value to the previous state.