6. Manage Pipeline
Pipelines represent a sequence of tasks that are executed along with each other in order to process some data. They help to automate complex tasks that consist of many sub-tasks.
This chapter describes Pipeline space GUI and the main working scenarios.
Pipeline object GUI
As far as the pipeline is one of CP objects which stored in "Library" space, the Pipeline workspace is separated into two panes:
- "Hierarchy" view pane
- "Details" view pane.
Note: also you can view general information and some details about the specific pipeline via CLI. See 14.4 View pipeline definitions via CLI.
"Details" view pane
The "Details" view pane displays content of a selected object. In case of a pipeline, you will see:
- a list of pipeline versions with a description of last update and date of the last update;
- specific space's controls.

"Details" controls
| Control | Description |
|---|---|
| Displays icon | This icon includes:
|
| "Gear" icon | This control (2) allows to rename, change the description, delete and edit repository settings i.e. Repository address and Token |
| Git repository | "Git repository" control (3) shows a git repository address where pipeline versions are stored, which could be copied and pasted into a browser address field: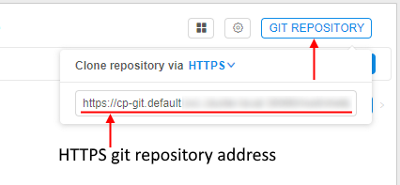 If for your purposes ssh protocol is required, you may click the HTTPS/SSH selector and choose the SSH item: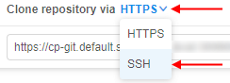 In that case, you will get a reformatted SSH address: 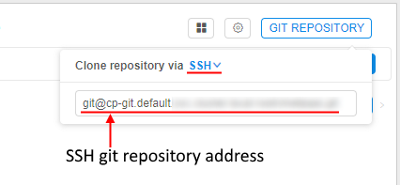 Also a user can work directly with git from the console on the running node. For more information, how to configure Git client to work with the Cloud Pipeline, see here. To clone a pipeline a user shall have READ permissions, to push WRITE permission are also needed. For more info see 13. Permissions. |
| Release | "Release" control (4) is used to tag a particular pipeline version with a name. A draft pipeline version has the control only. Note: you can edit the last pipeline version only. |
| Run | Each pipeline version item of the selected pipeline's list has a "Run" control (5) to launch a pipeline version. |
Pipeline versions GUI
Pipeline version interface displays full information about a pipeline version: supporting documentation, code files, and configurations, history of version runnings, etc.
Pipeline controls
The following buttons are available to manage this space.
| Control | Description |
|---|---|
| Run | This button launch a pipeline version. When a user clicks the button, the "Launch a pipeline" page opens. |
| "Gear" icon | This control allows to rename, change the description, delete and edit repository settings i.e. Repository address and Token. |
| Git repository | Shows a git repository address where pipeline versions are stored, which could be copied and pasted in a browser line. Also a user can work directly with git from the console on the running node. For more information, how to configure Git client to work with the Cloud Pipeline, see here. To clone a pipeline a user shall have READ permissions, to push WRITE permission is also needed. For more info see 13. Permissions. |
Pipeline launching page
"Launch a pipeline" page shows parameters of a default configuration the pipeline version. This page has the same view as a "Configuration" tab of a pipeline version. Here you can select any other configuration from the list and/or change parameters for this specific run (changes in configuration will be applied only to this specific run).
Pipeline version tabs
Pipeline version space dramatically differs from the Pipeline space. You can open it: just click on it.
The whole information is organized into the following tabs in "Details" view pane.
DOCUMENTS
The "Documents" tab contains documentation associated with the pipeline, e.g. README, pipeline description, etc. See an example here.
Note: README.md file is created automatically and contains default text which could be easily edited by a user.
Documents tab controls
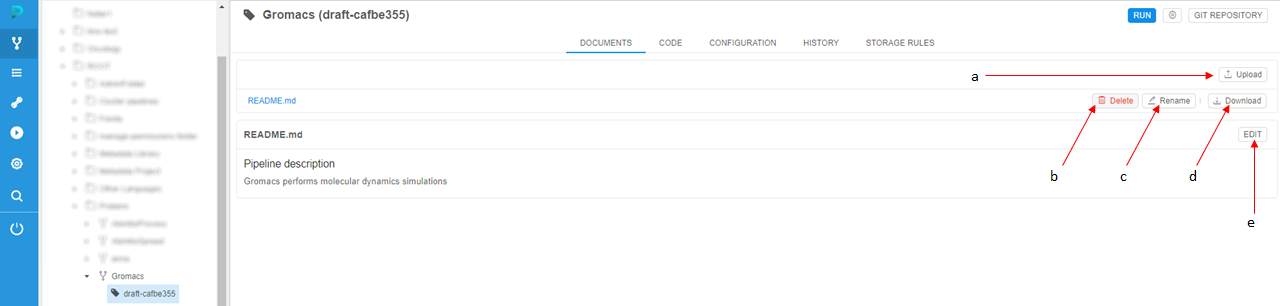
The following buttons are available to manage this section:
| Control | Description |
|---|---|
| Upload (a) | This control (a) allows to upload documentation files. |
| Delete (b) | "Delete" control (b) helps to delete a file. |
| Rename (c) | To rename a file a user shall use a "Rename" control (c). |
| Download (d) | This control (d) allows downloading pipeline documentation file to your local machine. |
| Edit (e) | "Edit" control (e) helps a user to edit any text files (e.g. README) here in a text editor using a markdown language. |
CODE
This section contains a list of scripts to run a pipeline. Here you can create new files, folders and upload files here. Each script file could be edited (see details here).
Note: .json configuration file can also be edited in the Configuration tab via GUI.
Code tab controls
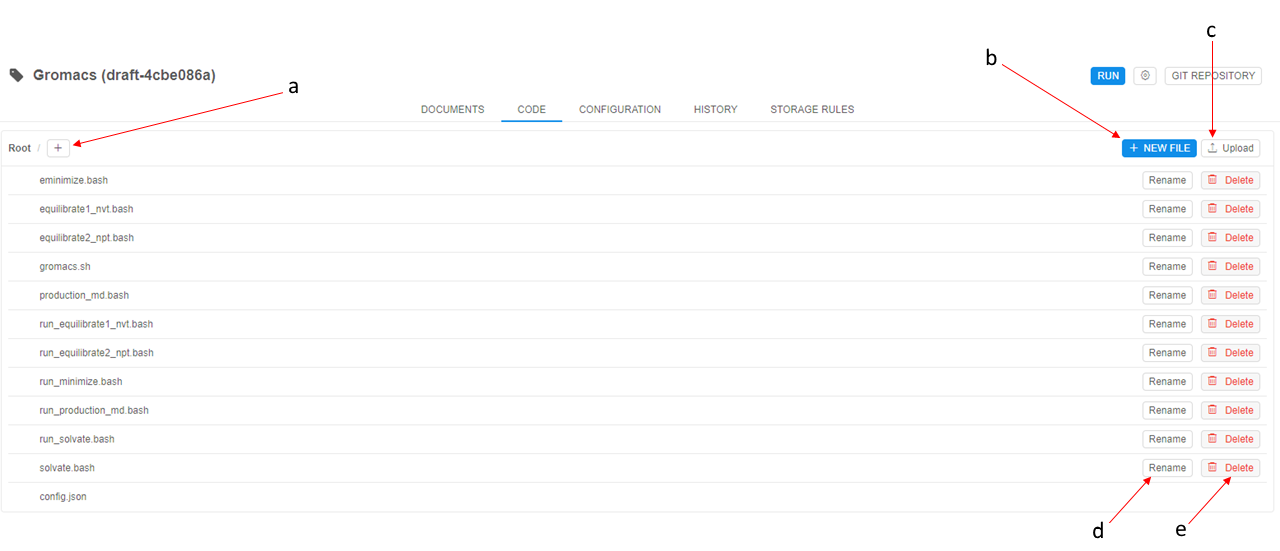
The following controls are available:
| Control | Description |
|---|---|
| Plus button (a) | This control is to create a new folder in a pipeline version. The folder's name shall be specified. |
| + New file (b) | To create a new file in the current folder. |
| Upload (c) | To upload files from your local file system to a pipeline version. |
| Rename (d) | Each file or folder has a "Rename" control which allows renaming a file/folder. |
| Delete (e) | Each file or folder has a "Delete" control which deletes a file/folder. |
The list of system files
All newly created pipelines have at least 2 starting files no matter what pipeline template you've chosen.
Only newly created DEFAULT pipeline has 1 starting file (config.json).
main_file
This file contains a pipeline scenario. By default, it is named after a pipeline, but this may be changed in the configuration file.
Note: the main_file is usually an entry point to start pipeline execution.
To create your own scenario the default template of the main file shall be edited (see details here).
Example: below is the piece of the main_file of the Gromacs pipeline:

config.json
This file contains pipeline execution parameters and settings.
Note: it is advised that pipeline execution settings are modified via CONFIGURATION tab (e.g. if you want to change default settings for pipeline execution) or via Launch pipeline page (e.g. if you want to change pipeline settings for a current run). Manual config.json editing should be used only for advanced users (primarily developers) since json format is not validated in this case.
Note: all attributes from config.json are available as environment variables for pipeline execution.
The config.json file for every pipeline template have the following settings:
| Setting | Description |
|---|---|
| main_file | A name of the main file for that pipeline. |
| instance_size | Instance type in terms of the specific Cloud Provider that specifies an amount of RAM in Gb, CPU and GPU cores number (e.g. m4.xlarge for AWS EC2 instance). |
| instance_disk | An instance's disk size in Gb. |
| docker_image | A name of the Docker image that will be used in the current pipeline. |
| cmd_template | Command line template that will be executed at the running instance in the pipeline. cmd_template can use environment variables: - to address the main_file parameter value, use the following construction - [main_file] - to address all other parameters, usual Linux environment variables style shall be used (e.g. $docker_image) |
| parameters | Pipeline execution parameters (e.g. path to the data storage with input data). A parameter has a name and set of attributes. There are possible keys for each parameter: - "type" - key specifies a type for current parameter, - "value" - key specifies default value for parameter, - "required" - key specifies whether this parameter must be set ("required": true) or might not ("required": false) - "no_override" - key specifies whether the parameter default value be immutable in the detached configuration that uses this pipeline: - if a parameter has a default value and "no_override" is true - that parameter field will be read-only- if a parameter has a default value and "no_override" is false or not set - that parameter field will be writable- if a parameter has no default value - "no_override" option is ignored and that parameter field will be writable |
Example: config.json file of the Gromacs pipeline:
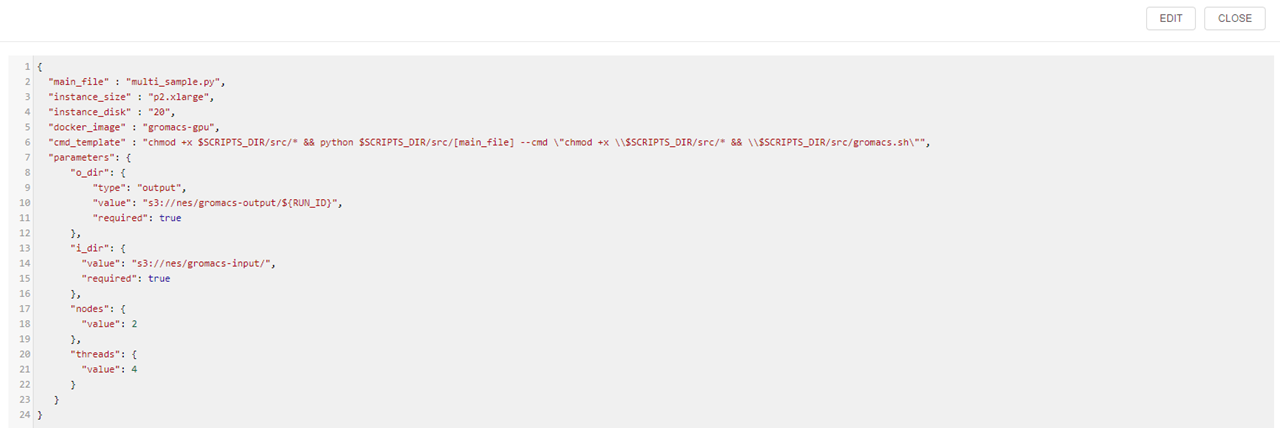
Note: In addition to main_file and config.json you can add any number of files to the CODE section and combine it in one whole scenario.
CONFIGURATION
This section represents pipeline execution parameters which are set in config.json file. The parameters can be changed here and config.json file will be changed respectively. See how to edit configuration here.
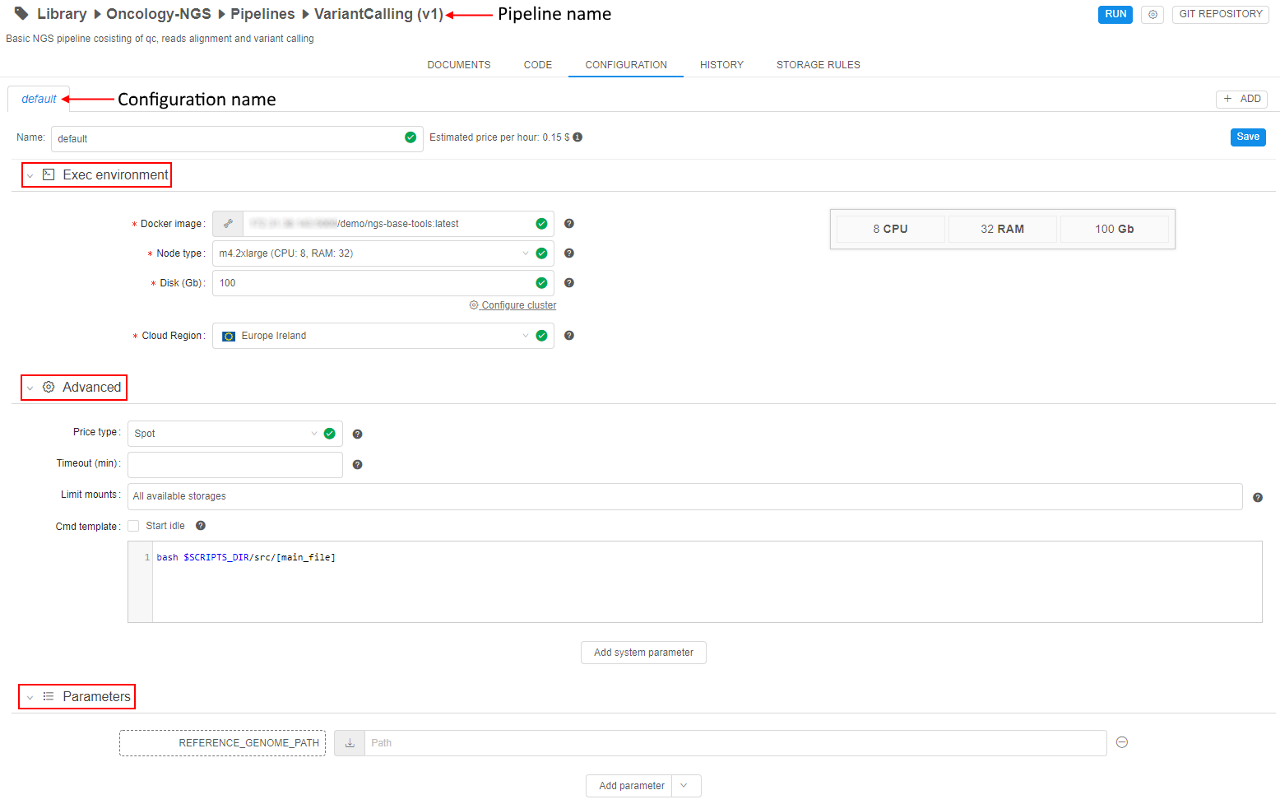
A configuration specifies:
| Section | Control | Description |
|---|---|---|
| Name | Pipeline and its configuration names. | |
| Estimated price per hour | Control shows machine hours prices. If you navigate mouse to "info" icon, you'll see the maximum, minimum and average price for a particular pipeline version run as well as the price per hour. | |
| Exec environment | This section lists execution environment parameters. | |
| Docker image | A name of a Docker image to use for a pipeline execution (e.g. "library/gromacs-gpu"). | |
| Node type | An instance type in terms of the specific Cloud Provider: CPU, RAM, GPU (e.g. 2 CPU cores, 8 Gb RAM, 0 GPU cores). | |
| Disk | Size of a disk in gigabytes, that will be attached to the instance in Gb. | |
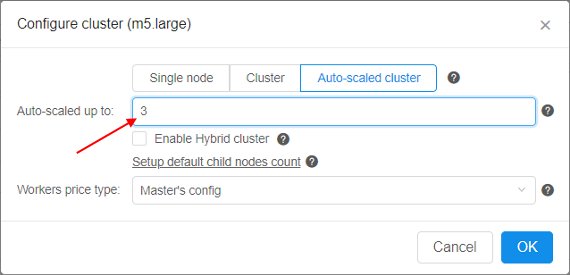
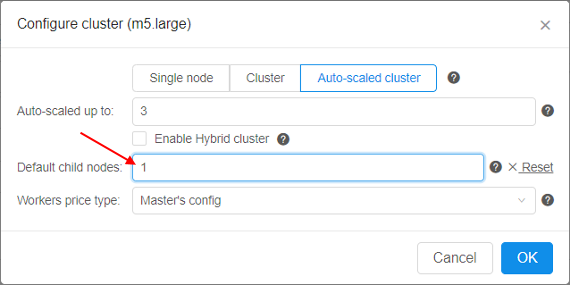
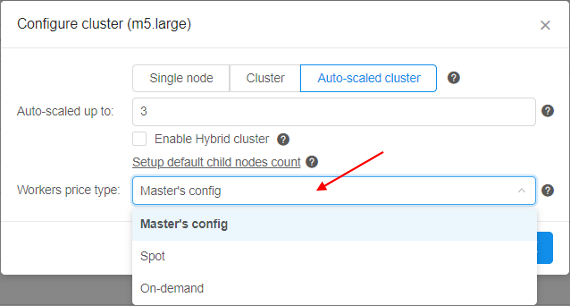
| Configure cluster button | On-click, pop-up window will be shown: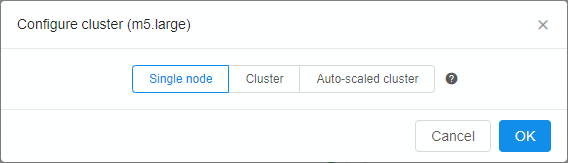 Here you can configure cluster or auto-scaled cluster. Cluster is a collection of instances which are connected so that they can be used together on a task. In both cases, a number of additional worker nodes with some main node as cluster head are launching (total number of pipelines = "number of working nodes" + 1). See v.0.14 - 7.2. Launch Detached Configuration for details. In case of using cluster, an exact count of worker nodes is directly defined by the user before launching the task and could not changing during the run. In case of using auto-scaled cluster, a max count of worker nodes is defined by the user before launching the task but really used count of worker nodes can change during the run depending on the jobs queue load. See Appendix C. Working with autoscaled cluster runs for details. For configure cluster:
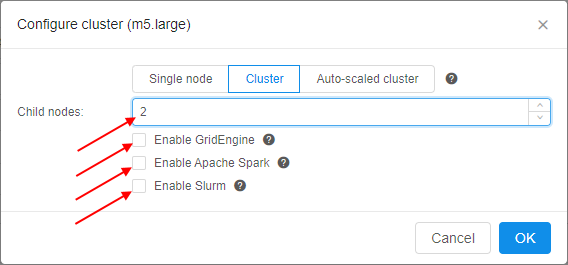 When user selects Cluster option, information on total cluster resources is shown. Resources are calculated as (CPU/RAM/GPU)*(NUMBER_OF_WORKERS+1): For configure auto-scaled cluster:
When user selects Auto-scaled cluster, information on total cluster resources is shown as interval - from the "min" configuration to "max" configuration:Note: if you don't want to use any cluster - click Single node button and then click OK button. |
|
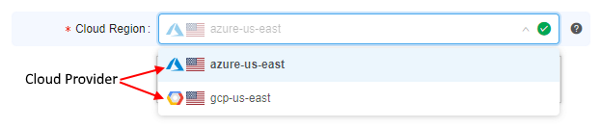
| Cloud Region | A specific region for a compute node placement. Please note, if a non-default region is selected - certain CP features may be unavailable:
Note: if a specific platform deployment has a number of Cloud Providers registered (e.g. |
|
| Run capabilities | Allows to launch a pipeline with a pre-configured additional software package(s), e.g. Docker-In-Docker, Singularity and others. For details see here.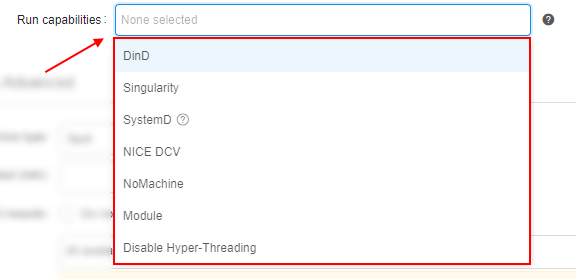 |
|
| Advanced | ||
| Price type | Choose Spot or On-demand type of instance. You can look information about price types hovering "Info" icon and based on it make your choice. | |
| Timeout (min) | After this time pipeline will shut down (optional). Before the shut down, all the contents of the $ANALYSIS_DIR directory will be copied to output storages. |
|
| Limit mounts | Allow to specify storages that should be mounted. For details see here. | |
| Cmd template | A shell command that will be executed to start a pipeline. | |
| "Start idle" | The flag sets cmd_template to sleep infinity. For more information about starting a job in this mode refer to 15. Interactive services. |
|
| Parameters | This section lists pipeline specific parameters that can be used during a pipeline run. Pipeline parameters can be assigned the following types:
|
|
| Add parameter | This control helps to add an additional parameter to a configuration. |



Configuration tab controls
| Control | Description |
|---|---|
| Add | To create a customized configuration for the pipeline, click the + ADD button in the upper-right corner of the screen. For more details see here. |
| Save | This button saves changes in a configuration. |
HISTORY
This section contains information about all the current pipeline version's runs. Runs info is organized into a table with the following columns:
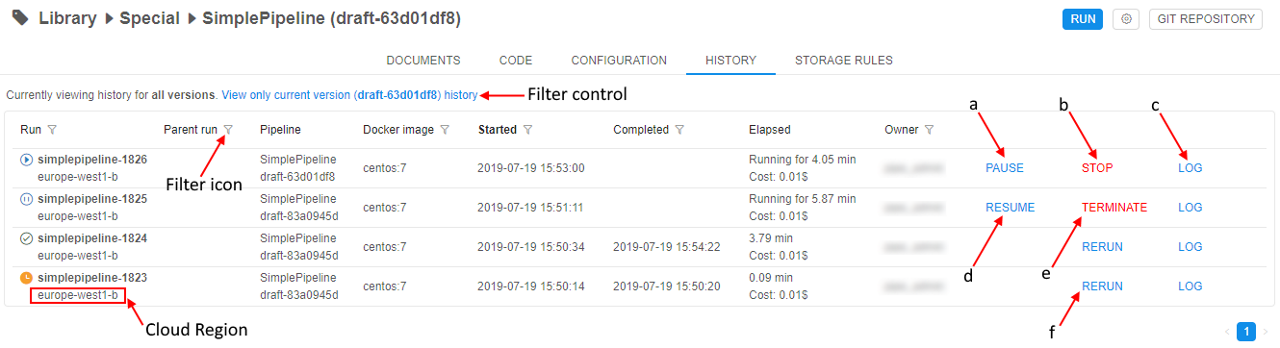
- Run - each record of that column contains two rows: in upper - run name that consists of pipeline name and run id, in bottom - Cloud Region.
Note: if a specific platform deployment has a number of Cloud Providers registered (e.g.
AWS+Azure,GCP+Azure) - corresponding text information also has a Provider name, e.g.:

- Parent-run - id of the run that executed current run (this field is non-empty only for runs that are executed by other runs).
- Pipeline - each record of that column contains two rows: in upper - pipeline name, in bottom - pipeline version.
- Docker image - base docker image name.
- Started - time pipeline started running.
- Completed - time pipeline finished execution.
- Elapsed - each record of that column contains two rows: in upper - pipeline running time, in bottom - run's estimated price, which is calculated based on the run duration, region and instance type.
- Owner - user who launched run.
You can filter runs by clicking the filter icon. By using the filter control you can choose whether display runs for current pipeline version or display runs for all pipeline versions.
History tab controls
| Control | Description |
|---|---|
| PAUSE (a) | To pause running pipeline press this control. This control is available only for on-demand instances. |
| STOP (b) | To stop running pipeline press this control. |
| LOG (c) | "Log" control opens detailed information about the run. You'll be redirected to "Runs" space (see 11. Manage Runs). |
| RESUME (d) | To resume pausing pipeline press this control. This control is available only for on-demand instances. |
| TERMINATE (e) | To terminate node without waiting of the pipeline resuming. This control is available only for on-demand instances, which were paused. |
| RERUN (f) | This control reruns completed pipeline's runs. |
Pipeline run's states
Icons at the left represent the current state of the pipeline runs:
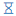 - Queued state ("sandglass" icon) - a run is waiting in the queue for the available compute node.
- Queued state ("sandglass" icon) - a run is waiting in the queue for the available compute node. - Initializing state ("rotating" icon) - a run is being initialized.
- Initializing state ("rotating" icon) - a run is being initialized. - Pulling state ("download" icon) - now pipeline Docker image is downloaded to the node.
- Pulling state ("download" icon) - now pipeline Docker image is downloaded to the node. - Running state ("play" icon) - a pipeline is running. The node is appearing and pipeline input data is being downloaded to the node before the "InitializeEnvironment" service task appears.
- Running state ("play" icon) - a pipeline is running. The node is appearing and pipeline input data is being downloaded to the node before the "InitializeEnvironment" service task appears. - Paused state ("pause" icon) - a run is paused. At this moment compute node is already stopped but keeps it's state. Such run may be resumed.
- Paused state ("pause" icon) - a run is paused. At this moment compute node is already stopped but keeps it's state. Such run may be resumed. - Success state ("OK" icon) - successful pipeline execution.
- Success state ("OK" icon) - successful pipeline execution. - Failed state ("caution" icon) - unsuccessful pipeline execution.
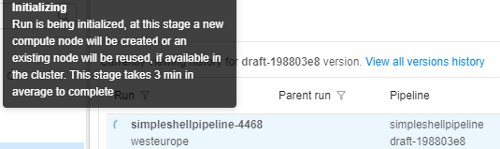
- Failed state ("caution" icon) - unsuccessful pipeline execution. - Stopped state ("clock" icon) - a pipeline manually stopped.
- Stopped state ("clock" icon) - a pipeline manually stopped.
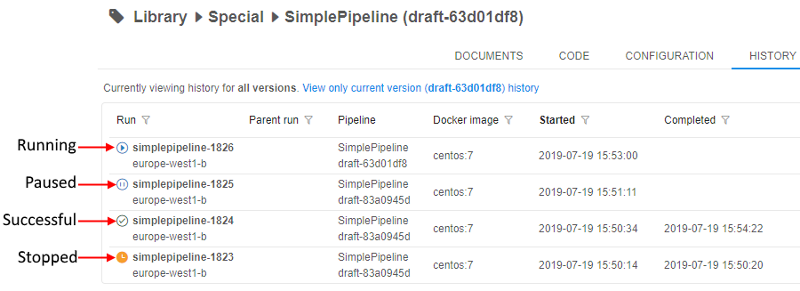
Also, help tooltips are provided when hovering a run state icon, e.g.:
STORAGE RULES
This section displays a list of rules used to upload data to the output data storage, once pipeline finished. It helps to store only data you need and minimize the amount of interim data in data storages.

Info is organized into a table with the following columns:
- Mask column contains a relative path from the $ANALYSIS_DIR folder (see Default environment variables section below for more information). Mask uses bash syntax to specify the data that you want to upload from the $ANALYSIS_DIR. Data from the specified path will be uploaded to the bucket from the pipeline node.
Note: by default whole $ANALYSIS_DIR folder is uploaded to the cloud bucket (default Mask is - "*"). For example, "*.txt*" mask specifies that all files with .txt extension need to be uploaded from the $ANALYSIS_DIR to the data storage.
Note: Be accurate when specifying masks - if wildcard mask ("*") is specified, all files will be uploaded, no matter what additional masks are specified. - The Created column shows date and time of rules creation.
- Move to Short-Term Storage column indicates whether pipeline output data will be moved to a short-term storage.
Storage rules tab control
| Control | Description |
|---|---|
| Add new rule (a) | This control allows adding a new data managing rule. |
| Delete (b) | To delete a data managing rule press this control. |
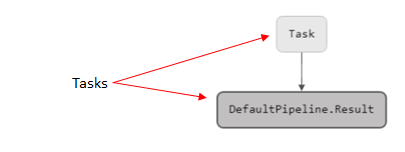
GRAPH
This section represents the sequence of pipeline tasks as a directed graph.
Tasks are graph vertices, edges represent execution order. A task can be executed only when all input edges - associated tasks - are completed (see more information about creating a pipeline with GRAPH section here).
Note: only for Luigi and WDL pipelines.
Note: If main_file has mistakes, pipeline workflow won't be visualized.
Graph tab controls
When a PipelineBuilder graph is loaded, the following layout controls become available to the user.

| Control | Description |
|---|---|
| Save | saves changes. |
| Revert | reverts all changes to the last saving. |
| Layout | performs graph linearization, make it more readable. |
| Fit | zooms graph to fit the screen. |
| Show links | enables/disables workflow level links to the tasks. It is disabled by default, as for large workflows it overwhelms the visualization. |
| Zoom out | zooms graph out. |
| Zoom in | zooms graph in. |
| Search element | allows to find specific object at the graph. |
| Fullscreen | expands graph to the full screen. |
Default environment variables
Pipeline scripts (e.g. main_file) use default environmental variables for pipeline execution. These variables are set in internal CP scripts:
- RUN_ID - pipeline run ID.
- PIPELINE_NAME - pipeline name.
- COMMON_DIR - directory where pipeline common data (parameter with
"type": "common") will be stored. - ANALYSIS_DIR - directory where output data of the pipeline (parameter with
"type": "output") will be stored. - INPUT_DIR - directory where input data of the pipeline (parameter with
"type": "input") will be stored. - SCRIPTS_DIR - directory where all pipeline scripts and config.json file will be stored.