Working with autoscaled cluster runs
Overview
Cloud Pipeline has support for launching runs using a single machine or a cluster of machines.
Moreover Cloud Pipeline allows to launch so-called autoscaled clusters which are basically clusters of machines with dynamic size.
It means that during the run execution additional worker machines can be attached to the cluster as well as removed from it.
By the way an autoscaled cluster can have so-called persistent workers which cannot be affected by the autoscaler.
Limitations
Currently only the SGE-based runs can be used efficiently with an autoscaled cluster capability.
And only the CPU requirements of the SGE jobs are considered while calculating cluster unsatisfied resources.
How it works
The cluster autoscaling tries to be intuitive and is pretty straightforward in most cases.
Nevertheless it can get cumbersome with all the allowed customization parameters.
The overall autoscaling approach is briefly described below.
Please notice that all the described steps are executed repeatedly for all the cluster lifetime depending on the current situation.
Finding expired jobs
Autoscaler is a background process which constantly watches the SGE queues in order to find expired jobs.
Basically expired jobs are the jobs that wait in any queue for more than some predefined time.
Launching workers
Once expired jobs are found the autoscaler tries to launch an additional worker.
The only case additional worker won't be launched is if all allowed additional workers are already set up.
Determing worker instance types
Additional worker instance types can vary from only a master instance type up to some instance types family.
Therefore there are homogeneous clusters that launches only the master instance type machines and hybrid clusters which
launches instance types from some instance type family.
By default all autoscaled clusters are homogeneous.
If an autoscaled cluster is hybrid and it is launching an additional worker then its instance type will be resolved based on the amount of unsatisfied CPU requirements of all pending jobs. The autoscaler will try to launch the smallest allowed instance from a specific instance type family that can process all the pending jobs simultaneously. For instance if there are two pending jobs with the CPU requirements of 4 and 8 then the autoscaler will try to launch the instance which has at least 12 CPUs.
Killing excessive workers
Once required additional workers are set up the cluster gets bigger and more jobs can be executed simultaneously.
At some point while jobs finish their execution some additional workers may become excessive.
In this case the autoscaler will check if all the queues were empty for at least some predefined time and try to remove excessive additional workers from the cluster.
Preventing deadlocks
In some specific cases autoscaled clusters may enter the deadlock situation.
In terms of autoscaled clusters a deadlock is a situation when submitted jobs cannot be executed in the best allowed cluster configuration.
For example if a hybrid autoscaled cluster which can have at most a machine with 64 CPUs is used to submit a job with a requirement of 100 CPUs then the job won't be ever executed and will stuck in queue forever. Fortunately the autoscaler can detect such deadlocks and prevent them simply killing jobs that cannot be executed anyway.
It most likely will fail the run execution but it is reasonable since the cluster usage is not properly configured in the run.
Besides an actual deadlock situation where are some similar cases when the cluster has reached its full capacity but some of the jobs are still pending.
It is not the deadlock situation since the jobs can be still executed but in the different cluster configuration.
The autoscaler will detect such situations and replace weak addition workers with a better ones.
Configurations
| System parameter | Description |
|---|---|
CP_CAP_AUTOSCALE_HYBRID |
Enables hybrid cluster mode. It means that additional worker type can vary within either master instance type family or CP_CAP_AUTOSCALE_HYBRID_FAMILY if specified. |
CP_CAP_AUTOSCALE_HYBRID_FAMILY |
Hybrid cluster additional worker instance type family. For example c5 or r5 instance families can be used for AWS. |
CP_CAP_AUTOSCALE_HYBRID_MAX_CORE_PER_NODE |
The maximum number of cores that hybrid cluster additional worker instances can have. |
CP_CAP_AUTOSCALE_VERBOSE |
Enables verbose logging. |
CP_CAP_AUTOSCALE_PRICE_TYPE |
Cluster additional worker instance price type. Defaults to master instance price type. |
CP_CAP_SGE_MASTER_CORES |
The number of cores that master run can use for job submissions. If set to 0 then no jobs will be executed on the master. Defaults to all the master instance cores. |
CP_CAP_SGE_WORKER_FREE_CORES |
The number of cores that all worker and master runs have to reserve from job submissions. Defaults to 0 which means that all instance cores will be used for job submissions. |
Examples
Homogeneous cluster
In this example we will see how an autoscaled cluster behaves on different conditions.
- Let's say we have launch an autoscaled cluster of
m5.largeinstances (2 CPUs per instance) with no persistent workers which can scale up to 2 workers.
You can find information on how to do that in the corresponding page. - On the Runs page we can see that the launched run doesn't have any workers.
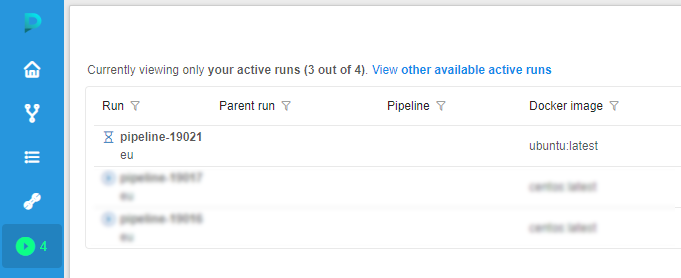
- On the Run logs page click the SSH button when it will become available.
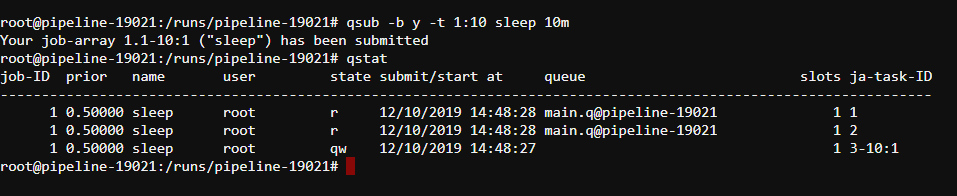
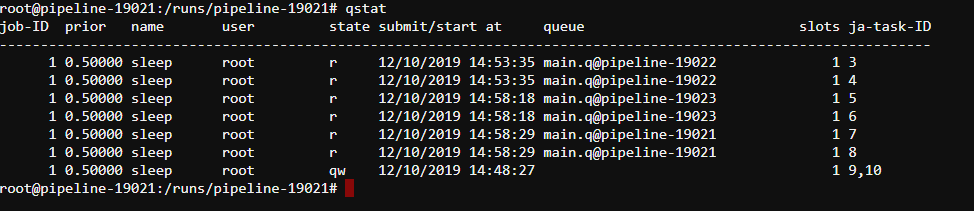
- In the opened terminal submit 10 single-core jobs to SGE queue using the following command
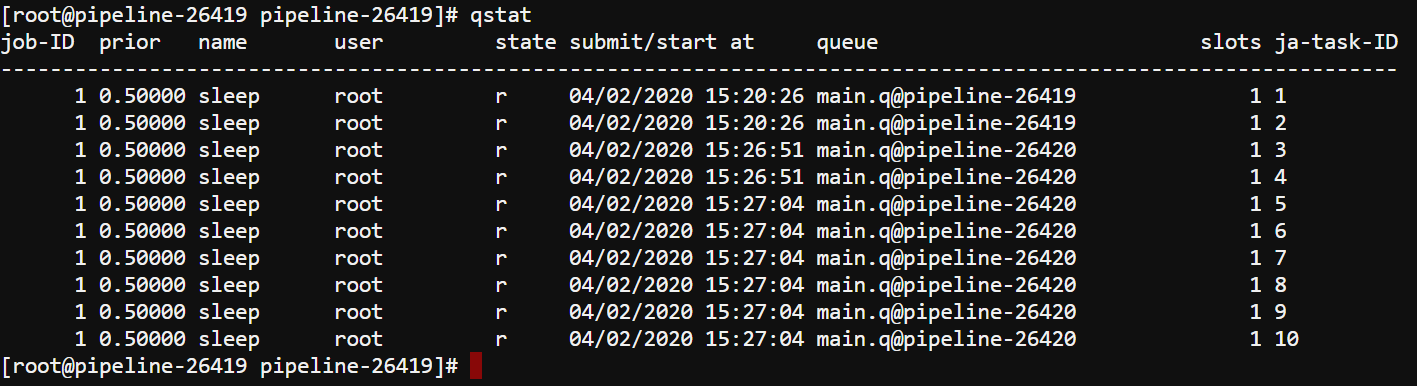
qsub -b y -t 1:10 sleep 10m. - Check that the jobs have been successfully submitted using
qstatcommand:
- Within several minutes an additional worker will be automatically added to out cluster:
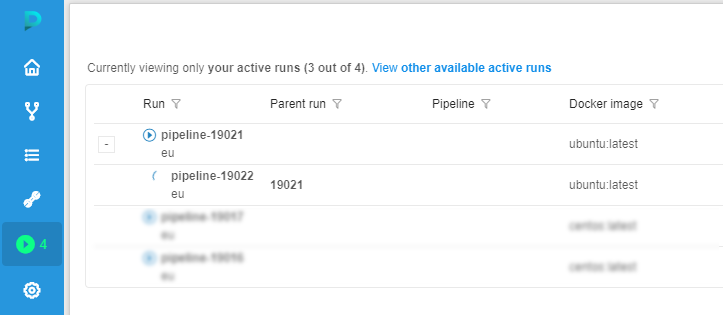
- Once the additional worker is fully initialized we can see that it takes several jobs from the queue:

- A few moments later if there are still pending jobs in the queue a second additional worker will be created:
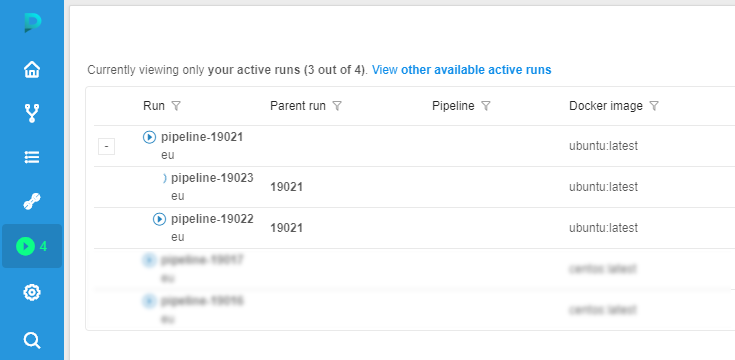
- And once it is initialized the worker will grab remaining jobs from the queue as well:
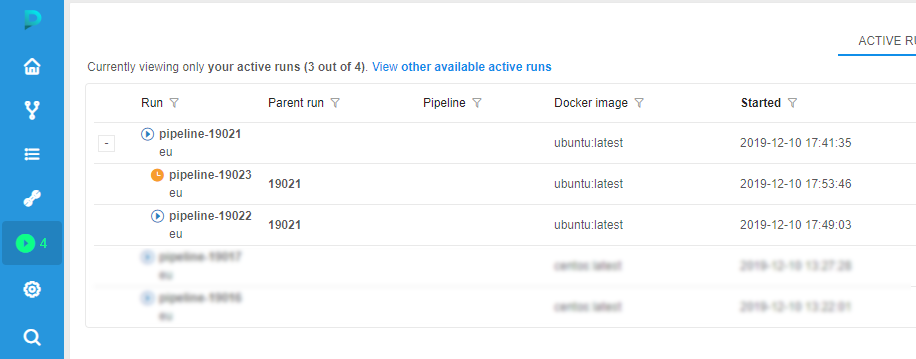
- As long as the most of the jobs are finishing and the workers become excessive they will be removed from the cluster:

- At first one of the workers becomes stopped:
- And then the last one becomes stopped too:
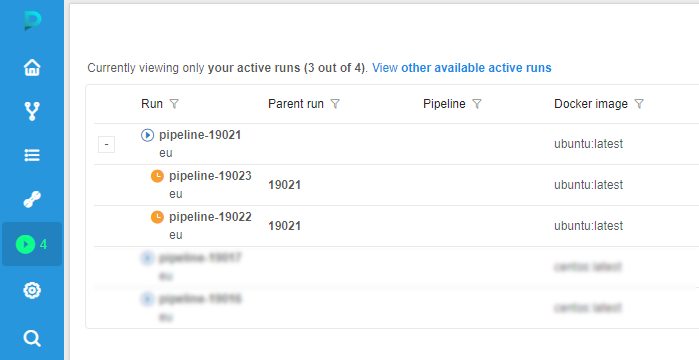
- From this point the cluster can scale up and down again and again depending on the workload.
Hybrid cluster
In this example we will see how a hybrid cluster behaves on different workloads.
- To start a hybrid cluster you have to configure a regular autoscaling cluster as described here.
Only the additional system parameter
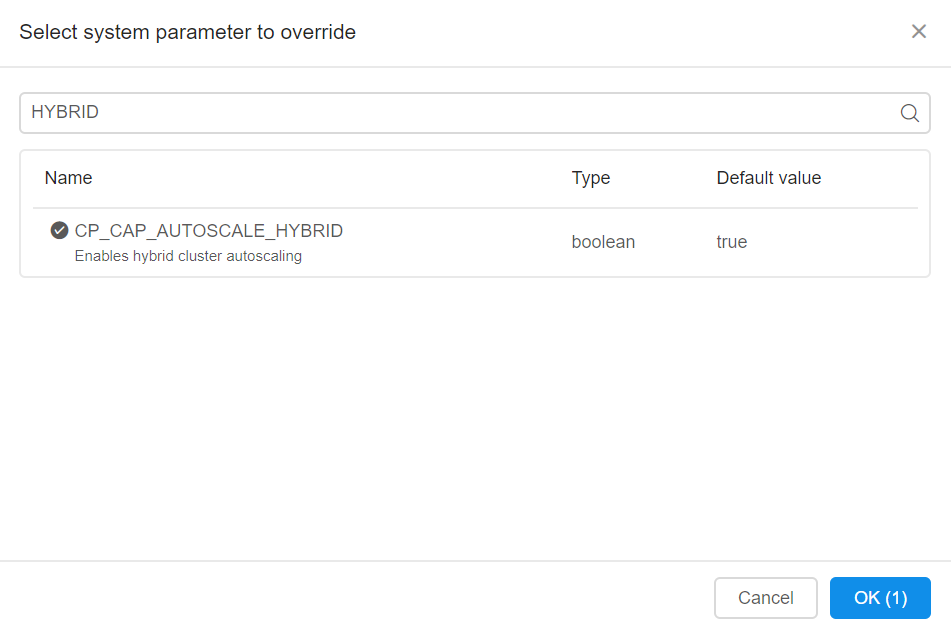
CP_CAP_AUTOSCALE_HYBRIDhave to be specified. Open the Advanced tab on the launch page and click Add system parameter button.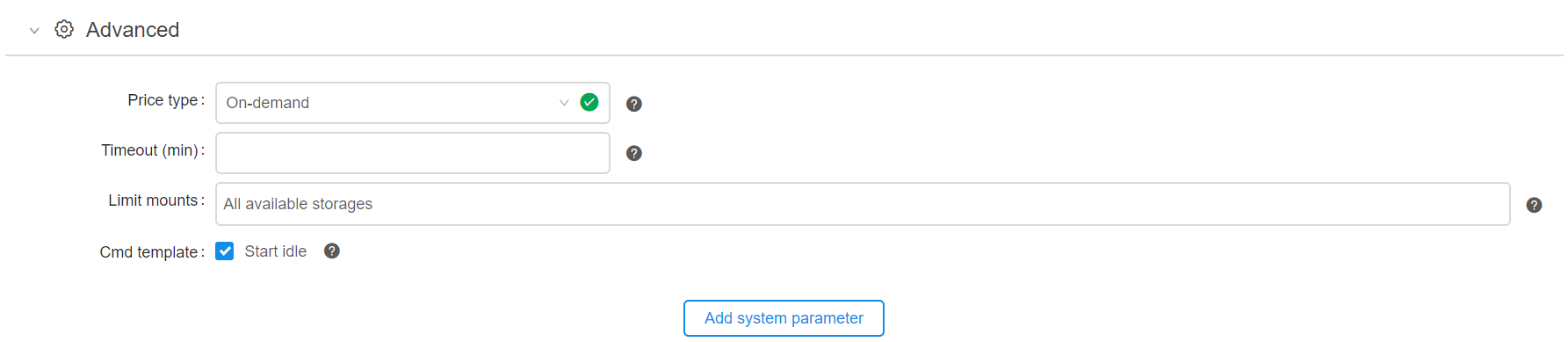
- Then type down HYBRID into the search field of the opened popup and select CP_CAP_AUTOSCALE_HYBRID system parameter.
Once the parameter is selected click OK (1) button.
- Configure an autoscaled cluster with the same configuration as in the example above and launch the run.
- On the Runs page click on the launched run.
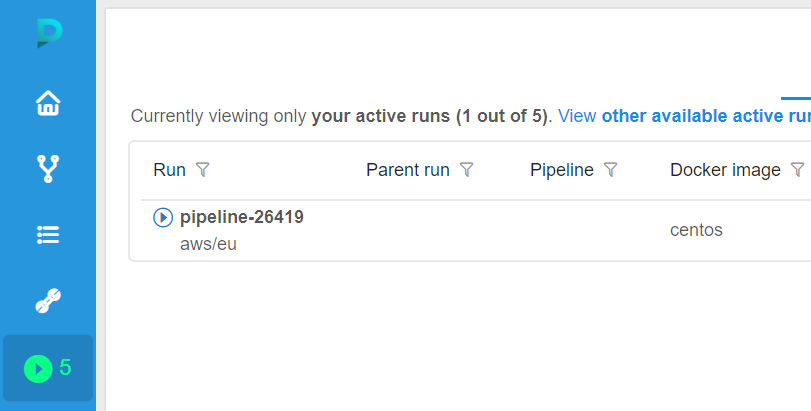
- Wait for the SSH button to appear and click on it.
- In the opened terminal submit 10 single-core jobs to SGE queue using the following command
qsub -b y -t 1:10 sleep 10m. - Check that the jobs have been successfully submitted using
qstatcommand:
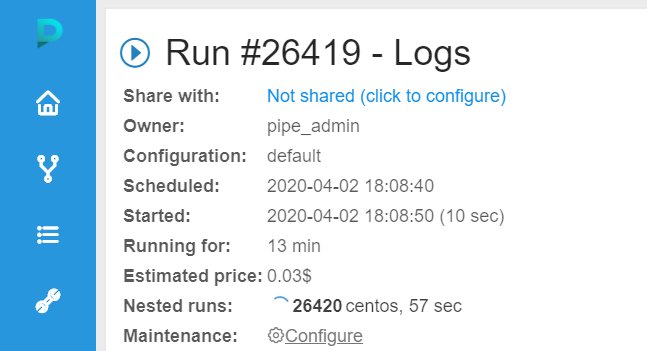
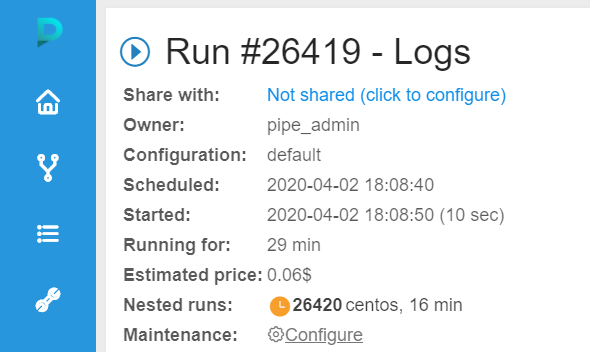
- If you go back to the run page and wait for a few minutes then you will see that an additional worker is launched.
Click on the additional worker run link to find out what instance type it uses.
- The additional worker instance type in this case is m5.2xlarge which has 8 CPUs and 32GB of RAM.
Please notice that the instance type selecting mechanism is highly situational and the resulting instance type can be different between launches.
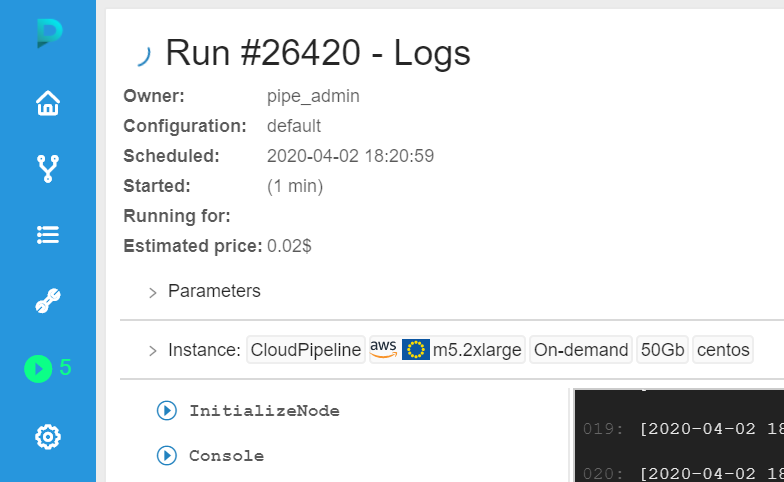
- Once the additional worker is initialized it will grab all the remaining jobs from the queue.
- And after about 10 minutes an additional worker will be scaled down since there are no pending jobs anymore.
- From this point the cluster can scale up and down again and again depending on the workload.