15.2. Using Terminal access
- Using Terminal access
- Example: using of Environment Modules for the Cloud Pipeline runs
- Example: using of Slurm for the Cloud Pipeline's clusters
Terminal access is available to the OWNER of the running job and users with ADMIN role. With sufficient permissions, Terminal access can be achieved to any running job.
For more information see 13. Permissions.Also you can get a terminal access to the running job using the
pipeCLI. For more details see here.
All software in the Cloud Pipeline is located in Docker containers, and we can use Terminal access to the Docker container via the Interactive services.
This can be useful when:
- usage of a new bioinformatics tool shall be tested;
- batch job scripts shall be tested within a real execution environment;
- docker image shall be extended and saved (install more packages/bioinformatics tools) - see 10.4. Edit a Tool.
Using Terminal access
Both Pipelines and Tools can be run as interactive services. The example below shows launching tool scenario:
- Navigate to the list of registered Tools and search for the Tool required (e.g. "base-generic-centos7").
- Go to the Tool page and click the arrow near the Run button → Select "Custom Settings".
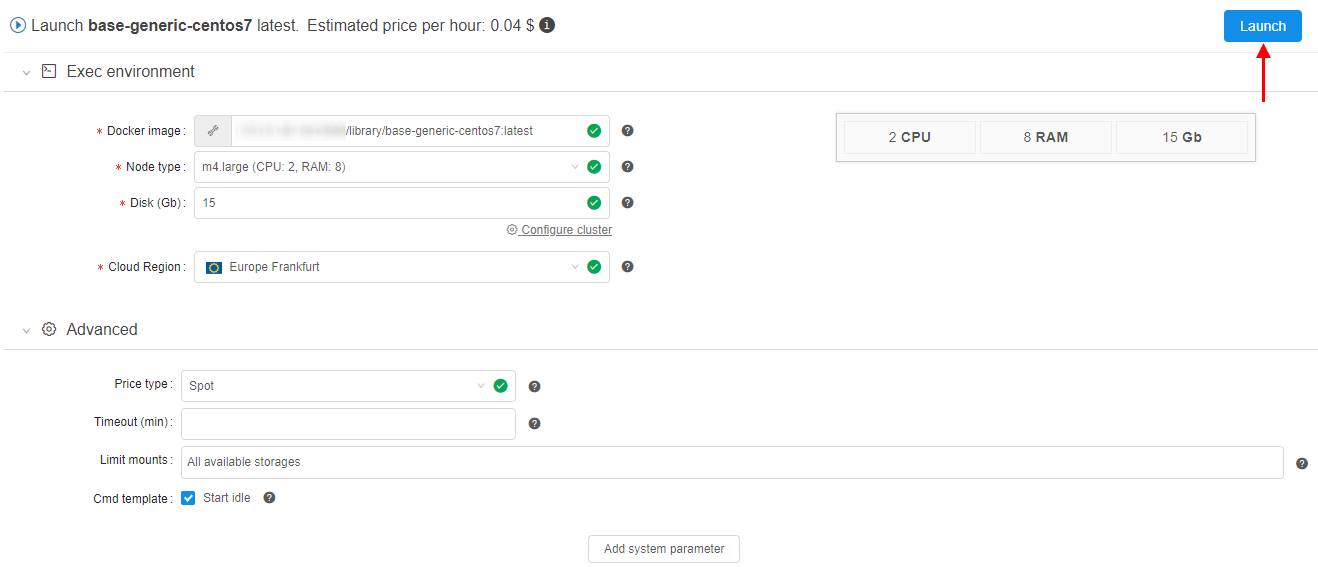
- Launch Tool page form will load (it's the same form that is used to configure a batch run). The following fields shall be filled:
- Node type
- Disk size
- Cloud Region
- "Start idle" box should be chosen. Click the Launch button when all above parameters are set.
- Once a run is scheduled and configured SSH hyperlink will appear in the "Run Log" form in the right upper corner of the form.
Note: This link is only visible to the owner of the run and users with ROLE_ADMIN role assigned.
Note: Also you can find this link at the Active Runs panel of the main Dashboard:
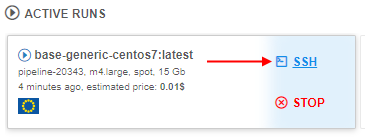
- Clicking the SSH link will load a new browser tab with an authenticated Terminal.
Note: If an unauthorized user will load a direct link, "Permission denied" error will be returned.
Terminal view
The view of the SSH terminal session can be configured.
At the moment, two color schemas can be used:
- Dark (default)

- Light

There are two ways to configure a required color schema:
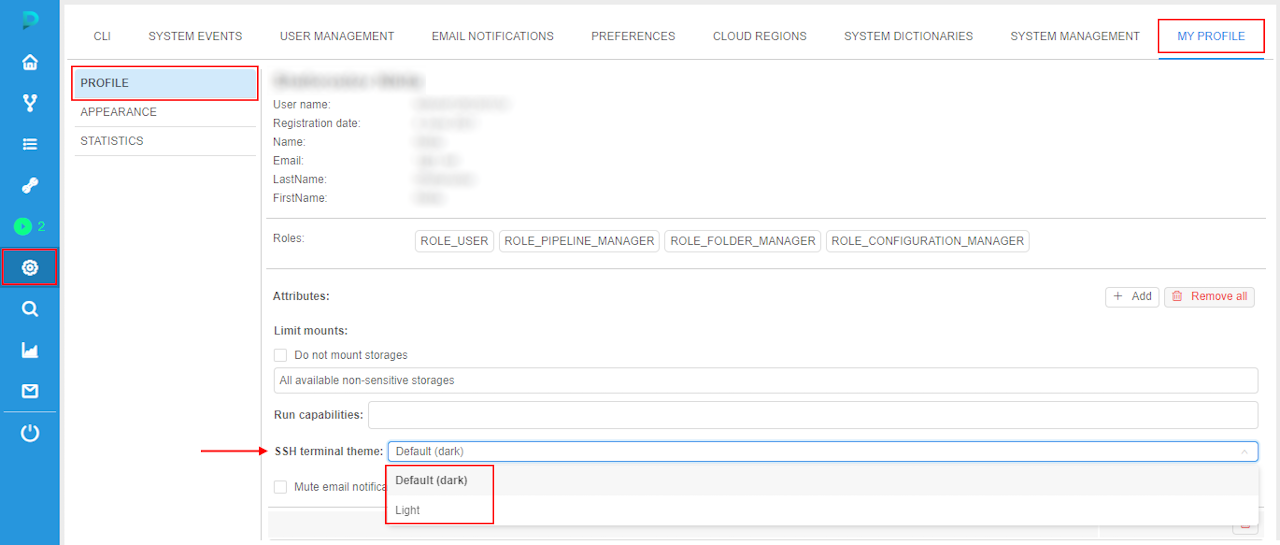
- Persistent - schema will be stored in the user profile and used any time SSH session is opened:
- Navigate to the Settings -> My Profile -> Profile
- Choose the schema from the SSH terminal theme menu:
Any SSH windows already opened - will still use the older parameter until reloaded (i.e. F5).
- Temporary - will be used during a current SSH session only. Any other sessions will use the settings from the My Profile (see Persistent option above):
- Open SSH session
- Click the
 icon to toggle the color schema Dark <-> Light:
icon to toggle the color schema Dark <-> Light:


Example: using of Environment Modules for the Cloud Pipeline runs
Configure of Environment Modules using is available only for users with ADMIN role.
The Environment Modules package provides for the dynamic modification of a user's environment via modulefiles.
In the example below, we will use Modules to switch between two versions of Java Development Kit.
- At the beginning we will create a storage for all
JDKversions files andmodulefiles. For that: open the Library, click Create + → Storages → Create new object storage - While creating - specify a storage name and mount point, e.g.
/opt/software:
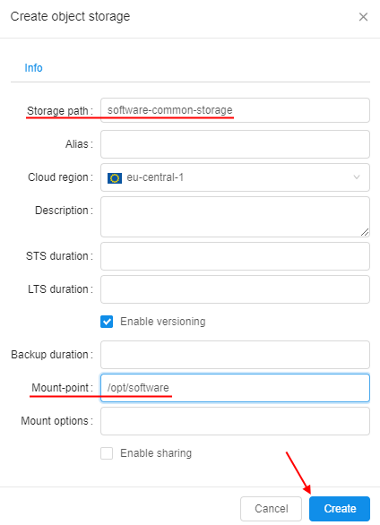
Click the Create button. - Open the created storage and create two folders in it:
- app - here we will upload
JDKfiles - modulefiles - here we will create
modulefilesfor eachJDKversion

- app - here we will upload
- Open the modulefiles folder, create the jdk folder in it.
- Open the jdk folder, create
modulefilefor theJDK ver. 9.0.4- name it 9.0.4:

- Click the file name, click the Fullscreen button at the file content panel:
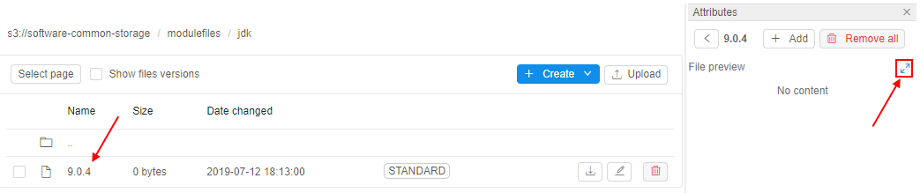
- At the popup click the EDIT button and input the
modulefilecontent, e.g. for theJDK ver. 9.0.4:
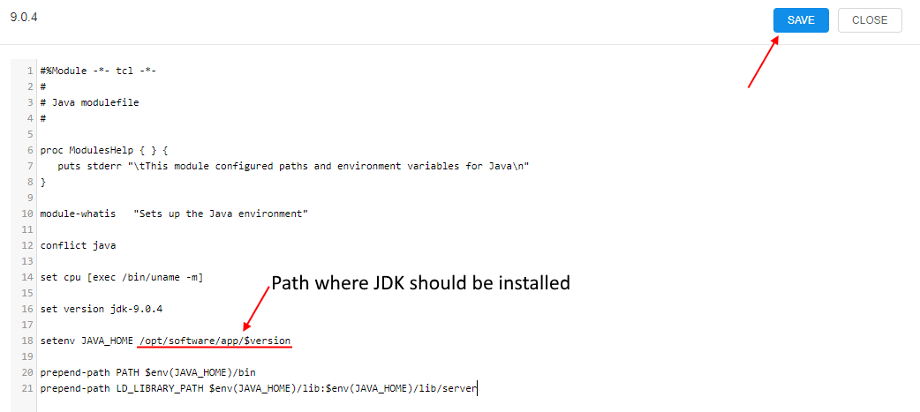
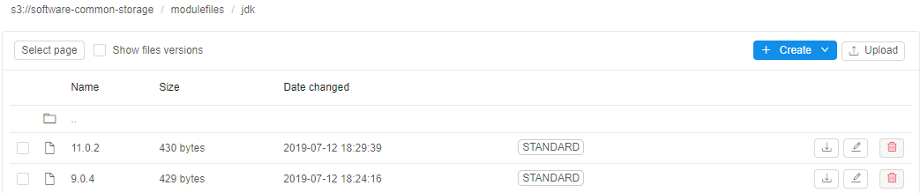
Save it. - Repeat steps 5-7 for the
JDK ver. 11.0.2. At the end you will have twomodulefilesin the jdk folder:
- Open System Settings popup, click the Preferences tab, select Launch section.
Into thelaunch.env.propertiesfield add a new variable -CP_CAP_MODULES_FILES_DIR. That variable specify path to the sourcemodulefiles.
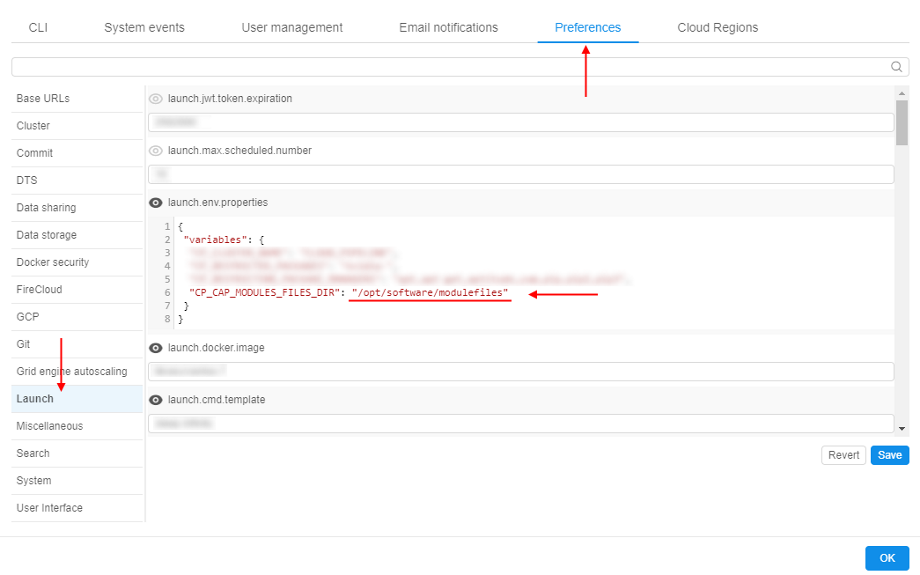
As you can see - during the run, when the storage created at step 2 will be mounted to the node in the specified mount-point (/opt/software), created aboveJDKmodulefileswill be available in the modulefiles folder created at step 3 - by the path/opt/software/modulefiles.
Save and close the Settings popup. - Go to the Tool page, open the tool page you want to use the
Environment Moduleswith and click the arrow near the Run button → Select "Custom Settings".
- At the Launch page expand Advanced section.
- In the Limit mounts field select the storage created at step 2 (see more details here).
- Click the Add system parameter button
- In the popup select the
CP_CAP_MODULESitem and click the OK button:
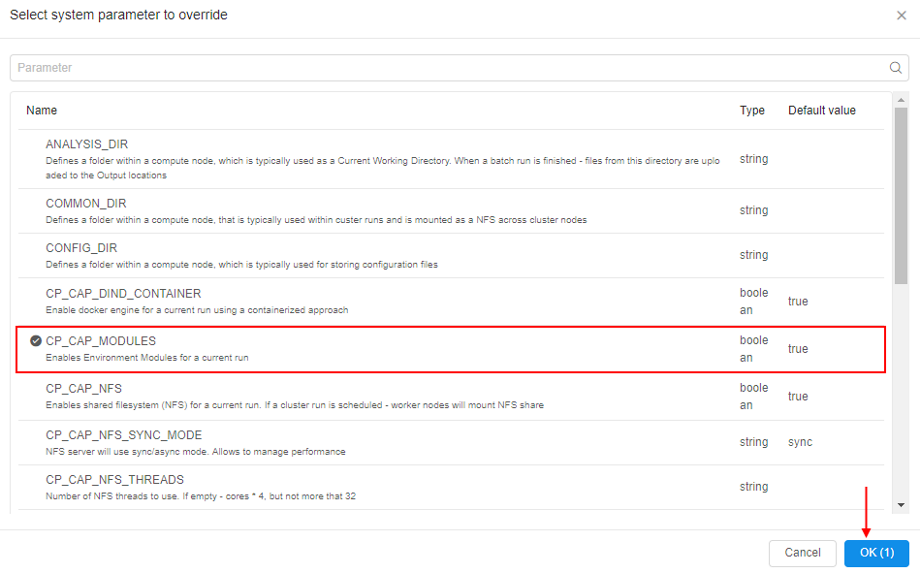
CP_CAP_MODULESparameter enables installation and using theModulesfor the current run. While installing,Moduleswill be configured to the sourcemodulefilespath from theCP_CAP_MODULES_FILES_DIRlaunch environment variable (that was set at step 9). IfCP_CAP_MODULES_FILES_DIRis not set - defaultmodulefileslocation will be used.
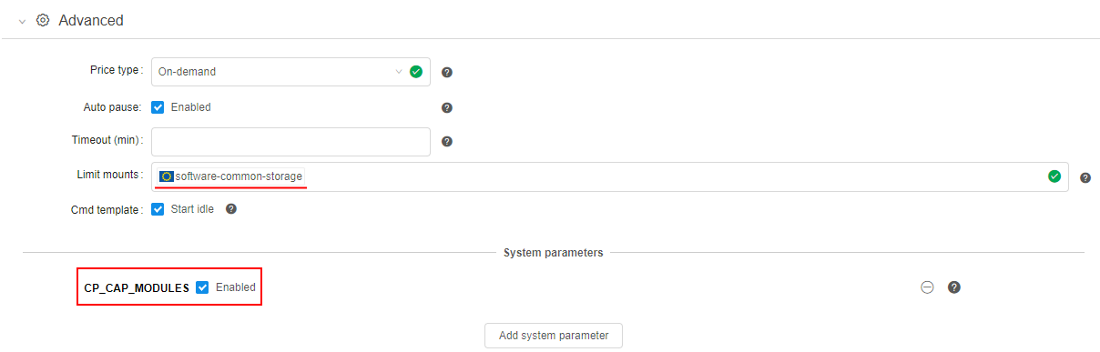
- Launch the tool.
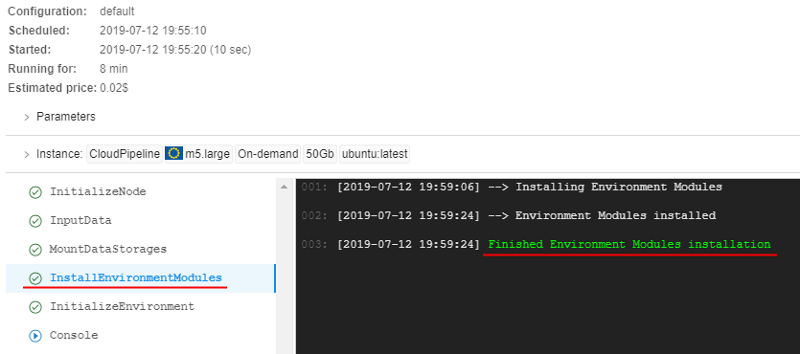
- Open Run logs page, wait until InstallEnvironmentModules task will appear and check that the
Moduleswas installed successfully:
- Wait until SSH hyperlink will appear in the right upper corner. Click it.
- In the terminal run the command
module useto check the ource path to themodulefiles:

- Now, we will install
JDK. For thever. 9.0.4run the following commands:
# Download "jdk 9.0.4" archive
wget https://download.java.net/java/GA/jdk9/9.0.4/binaries/openjdk-9.0.4_linux-x64_bin.tar.gz
# Extract archive content
tar -zxf openjdk-9.0.4_linux-x64_bin.tar.gz
# Copy "jdk 9.0.4" files into the mounted data storage
cp -r jdk-9.0.4 /opt/software/app/jdk-9.0.4
For the ver. 11.0.2 run the following commands:
# Download "jdk 11.0.2" archive
wget https://download.java.net/java/GA/jdk11/9/GPL/openjdk-11.0.2_linux-x64_bin.tar.gz
# Extract archive content
tar -zxf openjdk-11.0.2_linux-x64_bin.tar.gz
# Copy "jdk 11.0.2" files into the mounted data storage
cp -r jdk-11.0.2 /opt/software/app/jdk-11.0.2
Now, you can check the facilities of the Environment Modules package.
Load the available modulefiles list:

Load the JDK ver. 11.0.2:
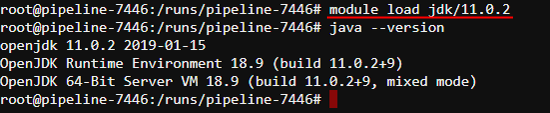
Switch to the JDK ver. 9.0.4:
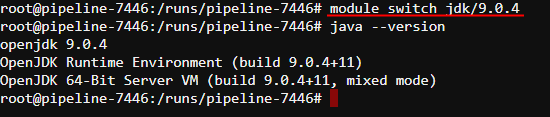
Unload all JDK versions:

Example: using of Slurm for the Cloud Pipeline's clusters
Slurm is an open source, highly scalable cluster management and job scheduling system for large and small Linux clusters.
In the example below, we will use Slurm for performing the simplest batch job.
- Open the Tools page, select a tool and its version (Note: in our example we will use
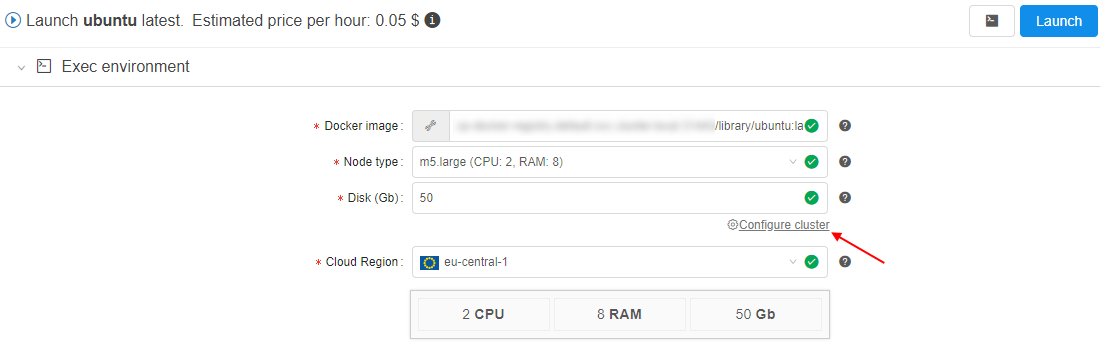
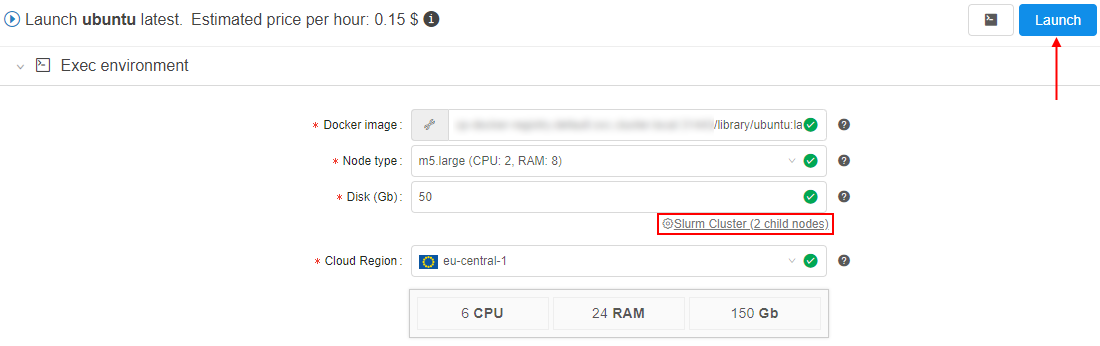
Ubuntu 18.04). Hover over the v button near the Run button and click the "Custom settings" item in the dropdown list. - At the Launch page expand "Exec environment" section and click the "Configure cluster" button:
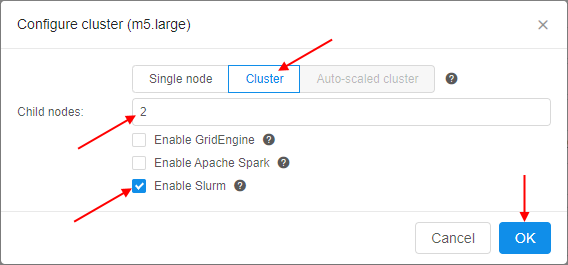
- In the appeared popup click the Cluster tab. Set the count of "child" nodes, tick the "Enable Slurm" checkbox and click the OK button to confirm:
- Launch the tool:
- Open the main Dashboard and wait until the SSH hyperlink will appear at the Active Runs panel for the just-launched tool, then click it:
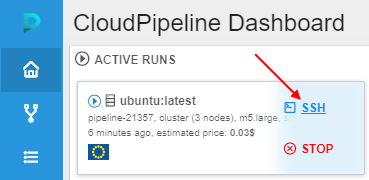
- The terminal web GUI will appear.
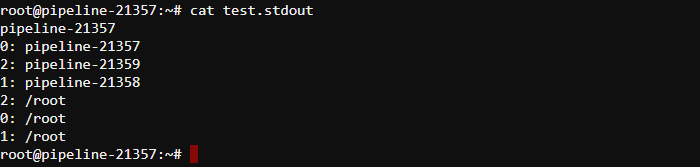
- At the beginning, let's check general system state, view existing partitions in the system and the list of available nodes. For that, perform the
sinfocommand:

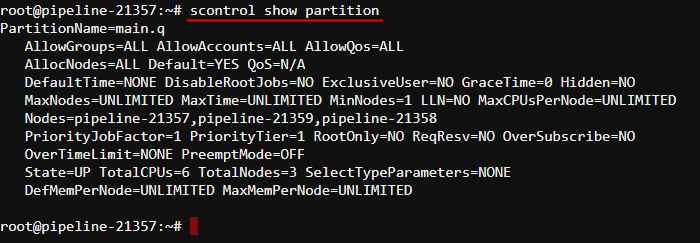
Onlymain.qpartition is created. All cluster nodes are attached to this partition. - To report more detailed information about partition - the
scontrolcommand can be used:
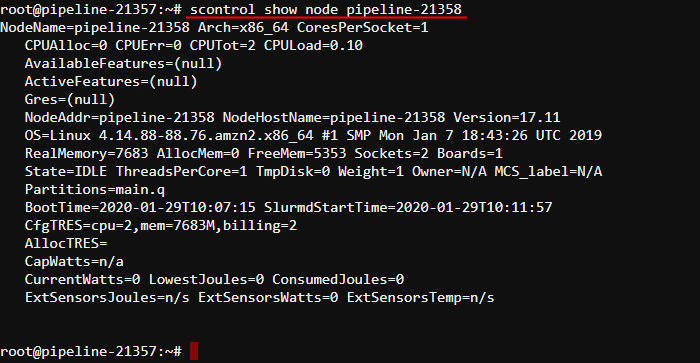
And to display detailed information about one of the nodes, e.g.:
- Now, we'll parallely execute
/bin/hostnameon all three nodes (-N3option) and include task numbers in the output (-loption) via thesruncommand.
The default partition will be used. One task per node will be used by default:

- For the batch job, create the following script:

This script contains a timelimit for the job embedded within itself (via the--timeoption after the#SBATCHprefix).
Script contains the command/bin/hostnamethat will be executed on the first node in the allocation (where the script runs) plus two job steps initiated using thesruncommand and executed sequentially.
To submit a job script for execution over all three nodes use thesbatchcommand, result will be written to the file (-ooption):

- During the script execution you can check the queue of running jobs in priority order via the
squeuecommand:

- The result of the
sbatchcommand performing: