Cloud Pipeline v.0.15 - Release notes
- Microsoft Azure Support
- SAML claims based access
- Notifications on the RAM/Disk pressure
- Limit mounted storages
- Personal SSH keys configuration
- Allow to set the Grid Engine capability for the "fixed" cluster
- Enable Apache Spark for the Cloud Pipeline's clusters
- Consider Cloud Providers' resource limitations when scheduling a job
- Allow to terminate paused runs
- Pre/Post-commit hooks implementation
- Restricting manual installation of the nvidia tools
- Setup swap files for the Cloud VMs
- Run's system paths shall be available for the general user account
- Renewed WDL visualization
- "QUEUED" state of the run
- Help tooltips for the run state icons
- VM monitor service
- Web GUI caching
- Installation via pipectl
- Add more logging to troubleshoot unexpected pods failures
- Displaying information on the nested runs
- Environment Modules support
- Sharing SSH access to running instances with other user(s)/group(s)
- Allow to limit the number of concurrent SSH sessions
- Verification of docker/storage permissions when launching a run
- Ability to override the queue/PE configuration in the GE configuration
- Estimation run's disk size according to the input/common parameters
- Disabling of the Global Search form if a corresponding service is not installed
- Disabling of the FS mounts creation if no FS mount points are registered
- Displaying resource limit errors during run resuming
- Object storage creation in despite of that the CORS/Policies could not be applied
- Track the confirmation of the "Blocking" notifications
pipeCLI warnings on the JWT expirationpipeconfiguration for using NTLM Authentication Proxy- Files uploading via
pipein case of restrictions - Run a single command or an interactive session over the SSH protocol via
pipe - Perform objects restore in a batch mode via
pipe - Mounting data storages to Linux and Mac workstations
- Allow to run
pipecommands on behalf of the other user - Ability to restrict the visibility of the jobs
- Ability to perform scheduled runs from detached configurations
- Using custom domain names as a "friendly URL" for the interactive services
- Displaying of the additional support icon/info
- Pass proxy settings to the
DINDcontainers - Interactive endpoints can be (optionally) available to the anonymous users
- Notable Bug fixes
- Incorrect behavior of the global search filter
- "COMMITING..." status hangs
- Instances of Metadata entity aren't correctly sorted
- Tool group cannot be deleted until all child tools are removed
- Missing region while estimating a run price
- Cannot specify region when an existing object storage is added
- ACL control for PIPELINE_USER and ROLE entities for metadata API
- Getting logs from Kubernetes may cause
OutOfMemoryerror - AWS: Incorrect
nodeuphandling of spot request status - Not handling clusters in
autopausedaemon - Incorrect
pipeCLI version displaying - JWT token shall be updated for the jobs being resumed
- Trying to rename file in the data storage, while the "Attributes" panel is opened, throws an error
pipe: incorrect behavior of the-ncoption for theruncommand- Cluster run cannot be launched with a Pretty URL
- Cloning of large repositories might fail
- System events HTML overflow
- AWS: Pipeline run
InitializeNodetask fails git-syncshall not fail the whole object synchronization if a single entry errorsendDateisn't set when node of a paused run was terminated- AWS: Nodeup retry process may stuck when first attempt to create a spot instance failed
- Resume job timeout throws strange error message
- GE autoscaler doesn't remove dead additional workers from cluster
- Broken layouts
Microsoft Azure Support
One of the major v0.15 features is a support for the Microsoft Azure Cloud.
All the features, that were previously used for AWS, are now available in all the same manner, from all the same GUI/CLI, for Azure.
Another cool thing, is that now it is possible to have a single installation of the Cloud Pipeline, which will manage both Cloud Providers (AWS and Azure). This provides a flexibility to launch jobs in the locations, closer to the data, with cheaper prices or better compute hardware for a specific task.
SAML claims based access
Previously, there were two options for users to be generally authenticated in Cloud Pipeline Platform, i.e. to pass SAML validation:
Auto-register- any valid SAML authentication automatically registers user (if he isn't registered yet) and grantROLE_USERaccessExplicit-register- after a valid SAML authentication, it is checked whether this user is already registered in the Cloud Pipeline catalog, and if no - request denies, authentication fails
To automate things a bit more, in v0.15 additional way to grant first-time access to the users was implemented: Explicit-group register.
If such registration type is set - once a valid SAML authentication is received, it is checked, whether SAML response contains any of the domain groups, that are already granted any access to the Cloud Pipeline objects (registered in Cloud Pipeline catalog). If so - proceeds as with Auto-register - user with all his domain groups and granted ROLE_USER access is being registered. If user's SAML domain groups aren't intersected with pre-registered groups the authentication fails.
This Platform's behavior is set via application property saml.user.auto.create that could accept one of the corresponding values: AUTO, EXPLICIT, EXPLICIT_GROUP.
Notifications on the RAM/Disk pressure
When a compute-intensive job is run - compute node may start starving for the resources.
CPU high load is typically a normal situation - it could result just to the SSH/metrics slowdown. But running low on memory and disk could crash the node, in such cases autoscaler will eventually terminate the cloud instance.
In v0.15 version, the Cloud Pipeline platform could notify user on the fact of Memory/Disk high load.
When memory or disk consuming will be higher than a threshold value for a specified period of time (in average) - a notification will be sent (and resent after a delay, if the problem is still in place).
Such notifications could be configured at HIGH_CONSUMED_RESOURCES section of the Email notifications:
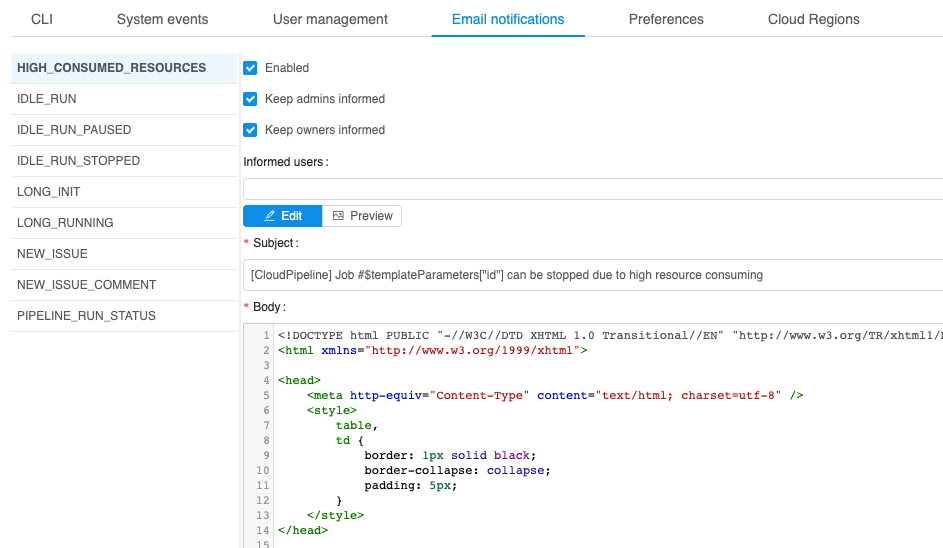
The following items at System section of the Preferences define behavior of such notifications:
system.memory.consume.threshold- memory threshold (in %) above which the notification would be sentsystem.disk.consume.threshold- disk threshold (in %) above which the notification would be sentsystem.monitoring.time.range- time delay (in sec) after which the notification would be sent again, if the problem is still in place.
See more information about Email notifications and System Preferences.
Limit mounted storages
Previously, all available storages were mounted to the container during the run initialization. User could have access to them via /cloud-data or ~/cloud-data folder using the interactive sessions (SSH/Web endpoints/Desktop) or pipeline runs.
For certain reasons (e.g. takes too much time to mount all or a run is going to be shared with others), user may want to limit the number of data storages being mounted to a specific job run.
Now, user can configure the list of the storages that will be mounted. This can be accomplished using the Limit mount field of the Launch form:
- By default,
All available storagesare mounted (i.e. the ones, that user hasroorrwpermissions) - To change the default behavior - click the drop-down list next to "Limit mounts" label:
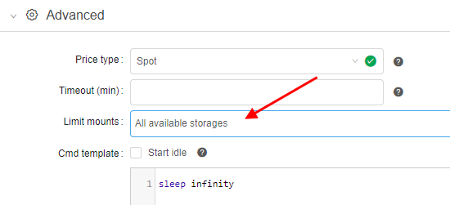
- Select storages that shall be mounted:
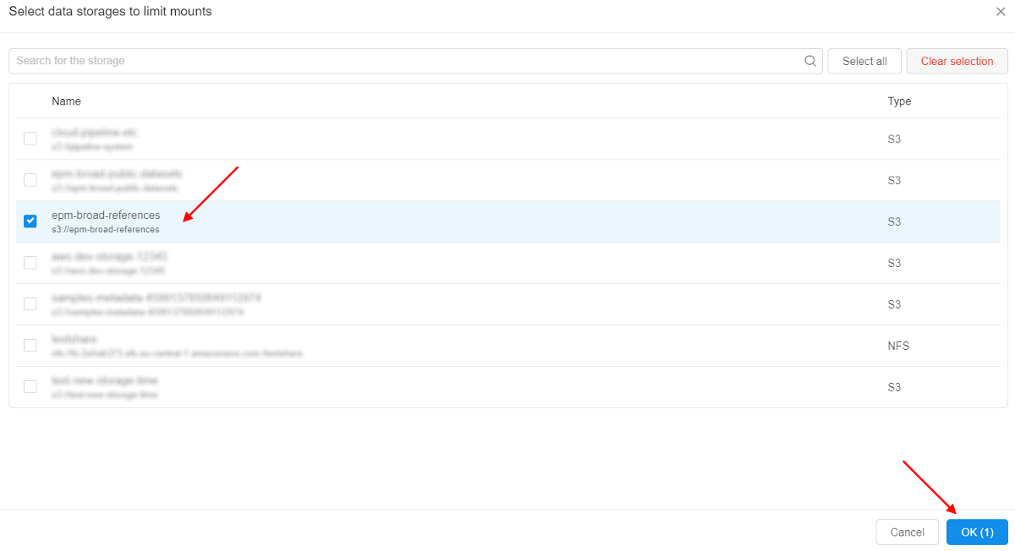
- Review that only a limited number of data storages is mounted:

- Mounted storage is available for the interactive/batch jobs using the path
/cloud-data/{storage_name}:

See an example here.
Personal SSH keys configuration
Previously, there were two options to communicate with the embedded gitlab repositories, that host pipelines code:
- From the local (non-cloud) machine: use the
httpsprotocol and the repository URI, provided by the GUI (i.e.GIT REPOSITORYbutton in the pipeline view) - From the cloud compute node:
gitcommand line interface, that is preconfigured to authenticate using https protocol and the auto-generated credentials
Both options consider that https is used. It worked fine for 99% of the use cases. But for some of the applications - ssh protocol is required as this is the only way to achieve a passwordless authentication against the gitlab instance
To address this issue, SSH keys management was introduced:
- Users' ssh keys are generated by the
Git Syncservice - SSH key-pair is created and assigned to the
Cloud Pipelineuser and a public key is registered in the GitLab - Those SSH keys are now also configured for all the runs, launched by the user. So it is possible to perform a passwordless authentication, when working with the gitlab or other services, that will be implemented in the near future
- HTTPS/SSH selector is added to the
GIT REPOSITORYpopup of theCloud PipelineWeb GUI:
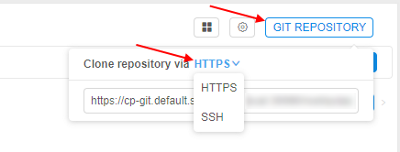
- Default selection is HTTP, which displays the same URI as previously (repository), but user is able to switch it to the SSH and get the reformatted address:
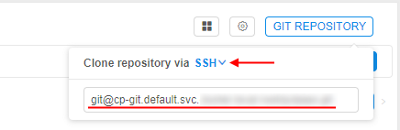
For more details see here.
Allow to set the Grid Engine capability for the "fixed" cluster
Version 0.14 introduced an ability to launch autoscaled clusters. Besides the autoscaling itself - such cluster were configured to use GridEngine server by default, which is pretty handy.
On the other hand - fixed cluster (i.e. those which contain a predefined number of compute nodes), required user to set the CP_CAP_SGE explicitly. Which is no a big deal, but may be tedious.
In v0.15 Grid Engine can be configured within the Cluster (fixed size cluster) tab.
This is accomplished by using the Enable GridEngine checkbox. By default, this checkbox is unticked. If the user sets this ON - CP_CAP_SGE parameter is added automatically.
Also a number of help icons is added to the Cluster configuration dialog to clarify the controls purpose:
- Popup header (E.g. next to the tabs line) - displays information on different cluster modes
- (Cluster)
Enable GridEnginecheckbox - displays information on the GridEngine usage - (Cluster)
Enable Apache Sparkcheckbox - displays information on the Apache Spark usage (see below) - (Auto-scaled cluster)
Auto-scaled up- displays information on the autoscaling logic - (Auto-scaled cluster)
Default child nodes- displays information on the initial node pool size
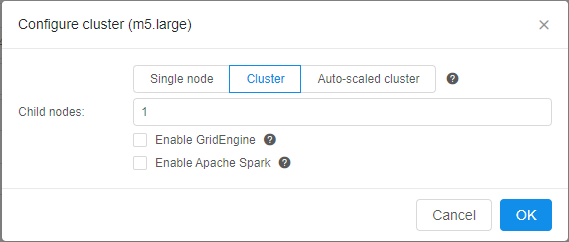
See more information about cluster launch here.
Enable Apache Spark for the Cloud Pipeline's clusters
Another one feature for the Cloud Pipeline's clusters was implemented in v0.15.
Now, Apache Spark with the access to File/Object Storages from the Spark Applications can be configured within the Cluster tab. It is available only for the fixed size clusters.
To enable this feature - tick the Enable Apache Spark checkbox and set the child nodes count at cluster settings. By default, this checkbox is unticked. Also users can manually enable Spark functionality by the CP_CAP_SPARK system parameter:
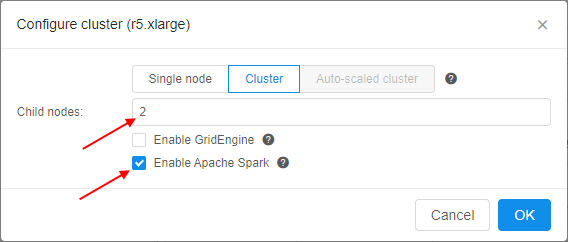
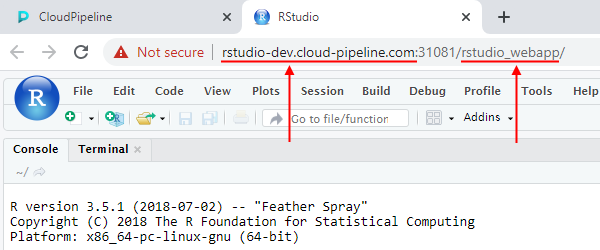
This feature, for example, allows you to run Apache Spark cluster with RStudio where you may code in R using sparklyr to run the workload over the cluster:
- Open the RStudio tool
- Select the node type, set the
Apache Sparkcluster as shown above, and launch the tool:
- Open main Dashboard and wait until the OPEN hyperlink for the launched tool will appear. Hover over it:
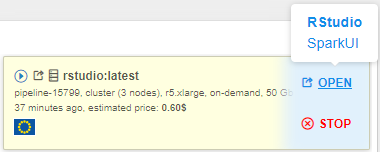
Two endpoints will appear:- RStudio (as the main endpoint it is in bold) - it exposes RStudio's Web IDE
- SparkUI - it exposes Web GUI of the Spark. It allows to monitor Spark master/workers/application via the web-browser. Details are available in the Spark UI manual
- Click the RStudio endpoint:
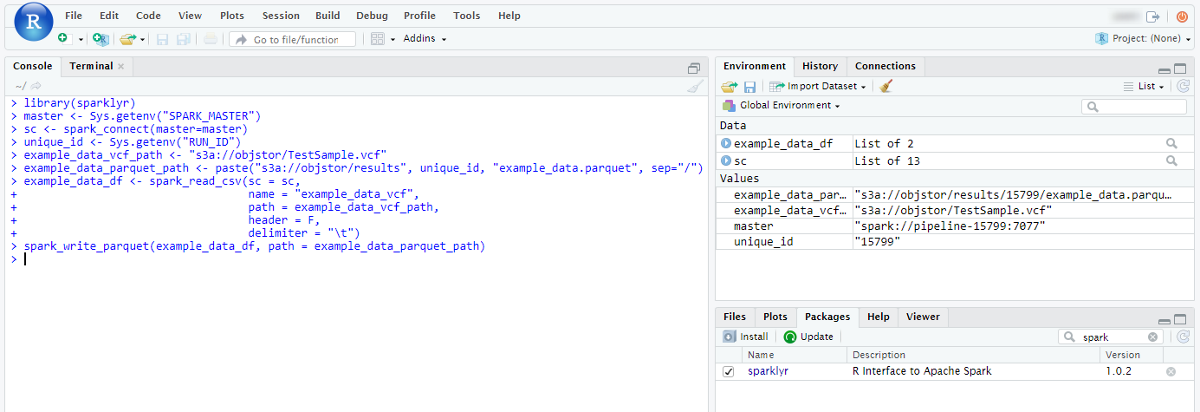
Here you can start create scripts inRusing the pre-installedsparklyrpackage to distribute the workload over the cluster. - Click the SparkUI endpoint:
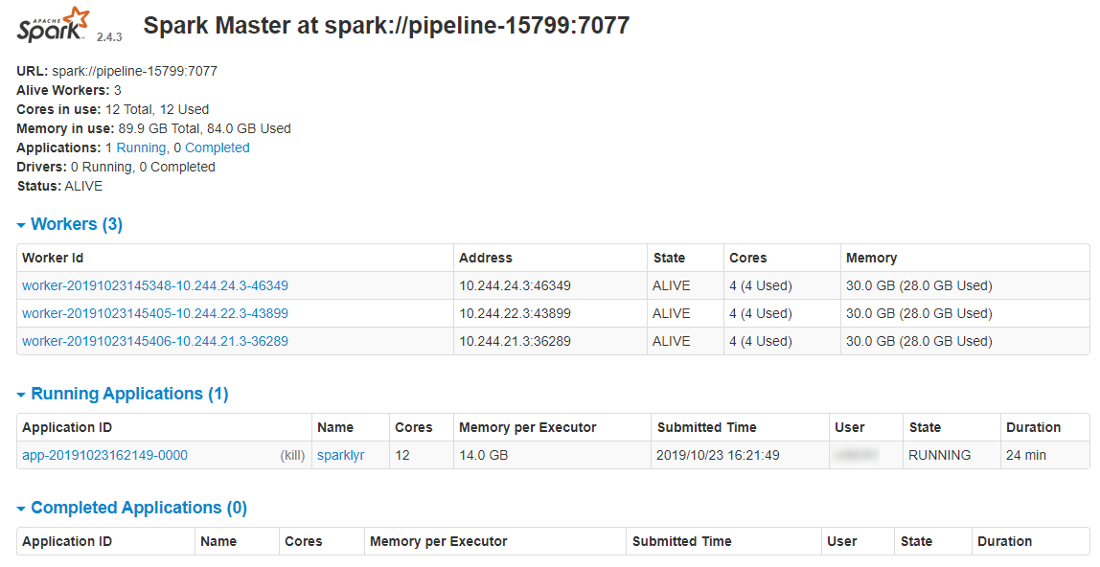
Here you can view the details of the jobs being executed in Spark, how the memory is used and get other useful information.
For more information about using Apache Spark via the Cloud Pipeline see here.
Consider Cloud Providers' resource limitations when scheduling a job
Cloud Pipeline supports queueing of the jobs, that cannot be scheduled to the existing or new compute nodes immediately.
Queueing occurs if:
cluster.max.sizelimit is reached (configurable viaPreferences)- Cloud Provider limitations are reached (e.g. AWS EC2 Limits)
If (1) happens - job will sit in the QUEUED state, until a spare will be available or stopped manually. This is the correct behavior.
But if (2) occurs - an error will be raised by the Cloud Provider, Cloud Pipeline treats this as an issue with the node creation. Autoscaler will then resubmit the node creation task for cluster.nodeup.retry.count times (default: 5) and then fail the job run.
This behavior confuses users, as (2) shall behave almost in the same manner as (1) - job shall be kept in the queue until there will be free space for a new node.
In v0.15 (2) scenario works as described:
- If a certain limit is reached (e.g. number of
m4.largeinstances exceeds the configured limit) - run will not fail, but will await for a spare node or limit increase - A warning will be highlighted in the job initialization log:

Allow to terminate paused runs
Some of the jobs, that were paused (either manually, or by the automated service), may be not needed anymore.
But when a run is paused - the user cannot terminate/stop it before resuming. I.e. one have to run RESUME operation, wait for it's completion and then STOP the run.
While this is the expected behavior (at least designed in this manner) - it requires some extra steps to be performed, which may look like meaningless (why one shall resume a run, that is going to be stopped?).
Another issue with such a behavior is that in certain "bad" conditions - paused runs are not able to resume and just fail, e.g.:
- An underlying instance is terminated outside of the Cloud Pipeline
- Docker image was removed from the registry
- And other cases that are not yet uncovered
This introduces a number of stale runs, that just sit there in the PAUSED state and nobody can remove them.
To address those concerns - current version of Cloud Pipeline allows to terminate PAUSED run, without a prior RESUME. This operation can be performed by the OWNER of the run and the ADMIN users.
Termination of the PAUSED run drops the underlying cloud instance and marks the run as STOPPED.
From the GUI perspective - TERMINATE button is shown (instead of STOP), when a run is in the PAUSED state:
- on the "Active runs" page

- on the "Run logs" page
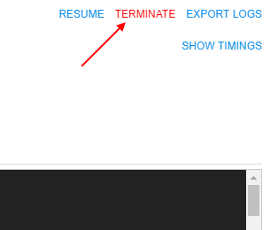
- on the "Dashboard" page

Clicking it - performs the run termination, as described above.
See more information here.
Pre/Post-commit hooks implementation
In certain use-cases, extra steps shall be executed before/after running the commit command in the container.
E.g. imagine the following scenario:
- User launches
RStudio - User installs packages and commits it as a new image
- User launches the new image
- The following error will be displayed in the R Console:
16 Jan 2019 21:17:15 [rsession-GRODE01] ERROR session hadabend; LOGGED FROM: rstudio::core::Error {anonymous}::rInit(const rstudio::r::session::RInitInfo&) /home/ubuntu/rstudio/src/cpp/session/SessionMain.cpp:563
There is nothing bad about this message and states that previous RSession was terminated in a non-graceful manner. RStudio will work correctly, but it may confuse the users.
While this is only one example - there are other applications, that require extra cleanup to be performed before the termination.
To workaround such issues (RStudio and others) an approach of pre/post-commit hooks is implemented. That allows to perform some graceful cleanup/restore before/after performing the commit itself.
Those hooks are valid only for the specific images and therefore shall be contained within those images. Cloud Pipeline itself performs the calls to the hooks if they exist.
Two preferences are introduced:
commit.pre.command.path: specified a path to a script within a docker image, that will be executed in a currently running container, BEFOREdocker commitoccurs (default:/root/pre_commit.sh).- This option is useful if any operations shall be performed with the running processes (e.g. send a signal), because in the subsequent
postoperation - only filesystem operations will be available. - Note that any changes done at this stage will affect the running container.
- This option is useful if any operations shall be performed with the running processes (e.g. send a signal), because in the subsequent
commit.post.command.path: specified a path to a script within a docker image, that will be executed in a committed image, AFTERdocker commitoccurs (default:/root/post_commit.sh).- This hook can be used to perform any filesystem cleanup or other operations, that shall not affect the currently running processes.
- If a corresponding pre/post script is not found in the docker image - it will not be executed.
For more details see here.
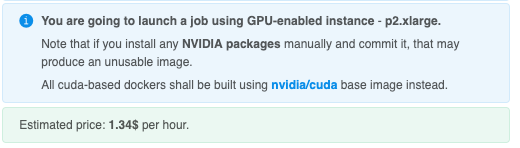
Restricting manual installation of the nvidia tools
It was uncovered that some of the GPU-enabled runs are not able to initialize due to an issue describe at NVIDIA/nvidia-docker#825.
To limit a possibility of producing such docker images (which will not be able to start using GPU instance types) - a set of restrictions/notifications was implemented:
- A notification is now displayed (in the Web GUI), that warns a user about the risks of installing any of the
nvidiapackages manually. And that allcuda-baseddockers shall be built usingnvidia/cudabase images instead:
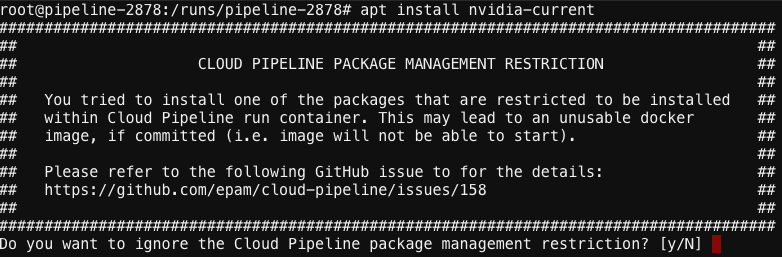
- Restrict users (to the reasonable extent) from installing those packages while running SSH/terminal session in the container. If user will try to install a
restrictedpackage - a warning will be shown (with an option to bypass it - for the advanced users):
Setup swap files for the Cloud VMs
This feature is addresses the same issues as the previous Notifications about high resources pressure by making the compute-intensive jobs runs more reliable.
In certain cases jobs may fail with unexpected errors if the compute node runs Out Of Memory.
v0.15 provides an ability for admin users to configure a default swap volume to the compute node being created.
This allows to avoid runs failures due to memory limits.
The size of the swap volume can be configured via cluster.networks.config item of the Preferences. It is accomplished by adding the similar json object to the platform's global or a region/cloud specific configuration:

Options that can be used to configure swap:
swap_ratio- defines a swap file size. It is equal the node RAM multiplied by that ratio. If ratio is 0, a swap file will not be created (default: 0)swap_location- defines a location of the swap file. If that option is not set - default location will be used (default: AWS will useSSD/gp2EBS, Azure will be Temporary Storage)
See an example here.
Run's system paths shall be available for the general user account
Previously, all the system-level directories (e.g. pipeline code location - $SCRIPTS_DIR, input/common data folders - $INPUT_DATA, etc.) were owned by the root user with read-only access to the general users.
This was working fine for the pipeline runs, as they are executed on behalf of root. But for the interactive sessions (SSH/Web endpoints/Desktop) - such location were not writable.
From now on - all the system-level location will be granted rwx access for the OWNER of the job (the user, who launched that run).
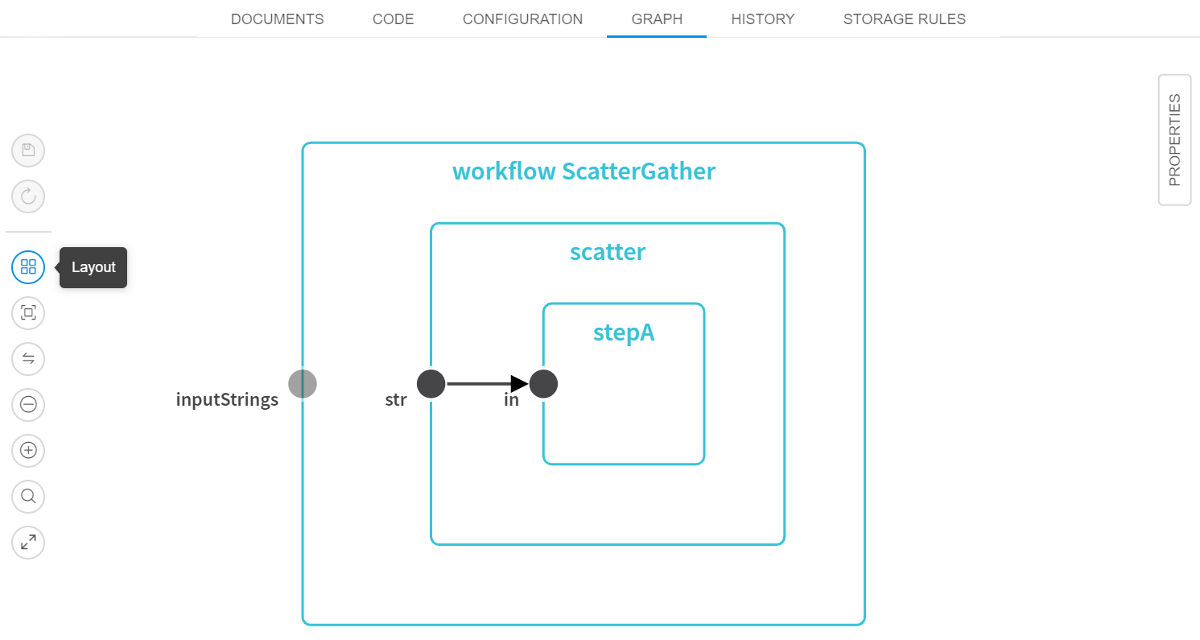
Renewed WDL visualization
v0.15 offers an updated Web GUI viewer/editor for the WDL scripts. These improvements allow to focus on the WDL diagram and make it more readable and clear. Which very useful for large WDL scripts.
- Auxiliary controls ("Save", "Revert changes", "Layout", "Fit to screen", "Show links", "Zoom out", "Zoom in", "Fullscreen") are moved to the left side of the
WDL GRAPHinto single menu:
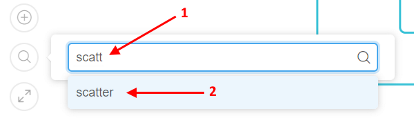
- WDL search capabilities are added. This feature allows to search for any task/variable/input/output within the script and focus/zoom to the found element. Search box is on the auxiliary controls menu and supports entry navigation (for cases when more than one item was found in the WDL):
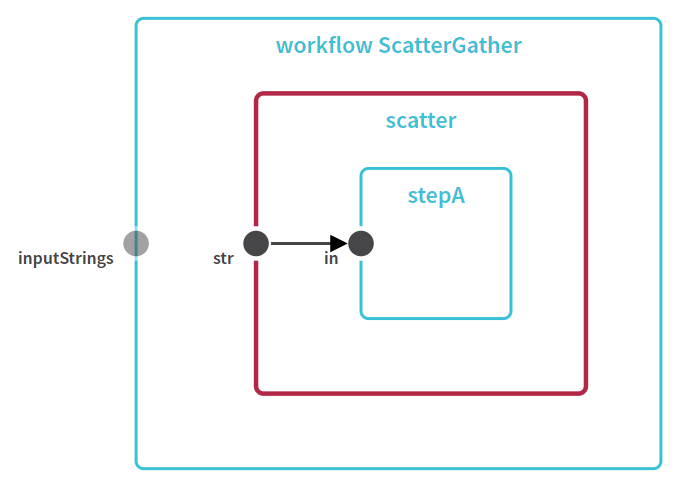
- Workflow/Task editor is moved from the modal popup to the right floating menu
PROPERTIES:
See more details here.
"QUEUED" state of the run
Previously, user was not able to distinguish runs that are waiting in the queue and the runs that are being initialized (both were reporting the same state using the same icons). Now, a more clear run's state is provided - "QUEUED" state is introduced:
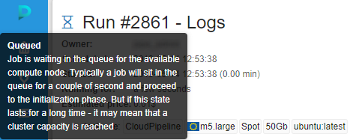
During this phase of the lifecycle - a job is waiting in the queue for the available compute node. Typically this shall last for a couple of second and proceed to the initialization phase. But if this state lasts for a long time - it may mean that a cluster capacity is reached (limited by the administrator).
This feature allows users to make a decision - whether to wait for run in a queue or stop it and resubmit.
See more details here.
Help tooltips for the run state icons
With the runs' QUEUED state introduction - we now have a good number of possible job phases.
To make the phases meaning more clear - tooltips are provided when hovering a run state icon within all relevant forms, i.e.: Dashboard, Runs (Active Runs/History/etc.), Run Log.
Tooltips contain a state name in bold (e.g. Queued) and a short description of the state and info on the next stage:
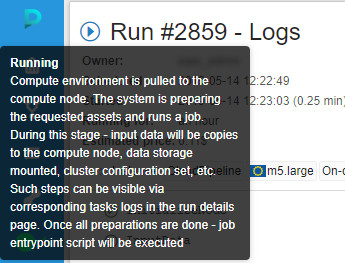
See more details - Active runs states, Completed runs states and Home page.
VM monitor service
For various reasons cloud VM instances may "hang" and become invisible to Cloud Pipeline services. E.g. VM was created but some error occurred during joining k8s cluster or a communication to the Cloud Providers API is interrupted.
In this case Autoscaler service will not be able to find such instance and it won't be shut down. This problem may lead to unmonitored useless resource consumption and billing.
To address this issue - a separate VM-Monitor service was implemented:
- Tracks all VM instances in the registered Cloud Regions
- Determines whether instances is in "hang" state
- Notifies a configurable set of users about a possible problem
Notification recipients (administrators) may check the actual state of VM in Cloud Provider console and shut down VM manually.
Additionally, VM-Monitor:
- Checks states of Cloud Pipeline's services (Kubernetes deployments). If any service changes it's state (i.e. goes down or up) - administrators will get the corresponding notification. List of such Kubernetes deployments to check includes all Cloud Pipeline's services by default, but also could be configed manually
- Checks all the PKI assets, available for the Platform, for the expiration - traverses over the list of directories that should contains certificate files, searches that certificates and verifies their expiration date. If some certificate expires less than in a certain amount of days - administrators also will get the corresponding notification. List of certificate directories to scan, certificate's mask and amount of days before expiration after which the notification will be sent are configurable
Web GUI caching
Previously, Cloud Pipeline Web GUI was not using HTTP caching to optimize the page load time. Each time application was loaded - ~2Mb of the app bundle was downloaded.
This caused "non-optimal" experience for the end-users.
Now the application bundle is split into chunks, which are identified by the content-hash in names:
- If nothing is changed - no data will be downloaded
- If some part of the app is changed - only certain chunks will be downloaded, not the whole bundle
Administrator may control cache period using the static.resources.cache.sec.period parameter in the application.properties of the Core API service.
Installation via pipectl
Previous versions of the Cloud Pipeline did not offer any automated approach for deploying its components/services.
All the deployment tasks were handed manually or by custom scripts.
To simplify the deployment procedure and improve stability of the deployment - pipectl utility was introduced.
pipectl offers an automated approach to deploy and configure the Cloud Pipeline platform, as well as publish some demo pipelines and docker images for NGS/MD/MnS tasks.
Brief description and example installation commands are available in the pipectl's home directory.
More sophisticated documentation on the installation procedure and resulting deployment architecture will be created further.
Add more logging to troubleshoot unexpected pods failures
When a Cloud Pipeline is being for a long time (e.g. years), it is common to observe rare "strange" problems with the jobs execution.
I.e. the following behavior was observed couple of times over the last year:
Scenario 1
- Run is launched and initialized fine
- During processing execution - run fails
- Console logs print nothing, compute node is fine and is attached to the cluster
Scenario 2
- Run is launched, compute node is up
- Run fails during initialization
- Console logs print the similar error message:
failed to open log file "/var/log/pods/**.log": open /var/log/pods/**.log: no such file or directory
Both scenarios are flaky and almost impossible to reproduce. To provide more insights into the situation - an extended node-level logging was implemented:
kubeletlogs (from all compute nodes) are now written to the files (viaDaemonSet)- Log files are streamed to the storage, identified by
storage.system.storage.namepreference - Administrators can find the corresponding node logs (e.g. by the
hostnameoripthat are attached to the run information) in that storage underlogs/node/{hostname}
See an example here.
Displaying information on the nested runs within a parent log form
Previously, if user launched a run, that has a number of children (e.g. a cluster run or any other case with the parent-id specified), he could view the children list only from "Runs" page.
In v.0.15 a convenient opportunity to view the list of children directly in the parent's run logs form is implemented:
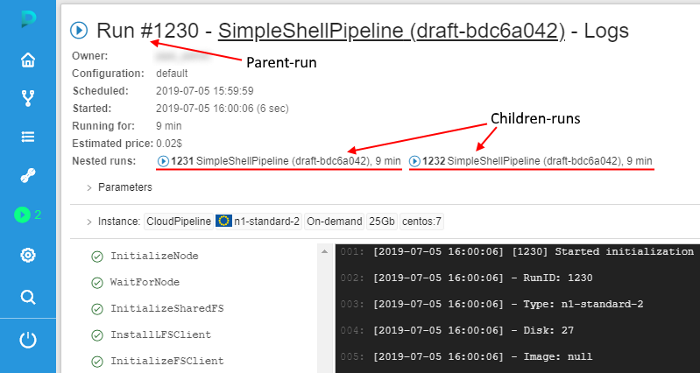
For each child-run in the list the following information is displayed:
- State icons with help tooltips when hovering over them
- Pipeline name and version/docker image and version
- Run time duration
Similar as a parent-run state, states for nested runs are automatically updated without page refreshing. So, you can watch for them in real time.
If you click any of the children-runs, you will navigate to its log page.
That feature is implemented for the comleted runs too:
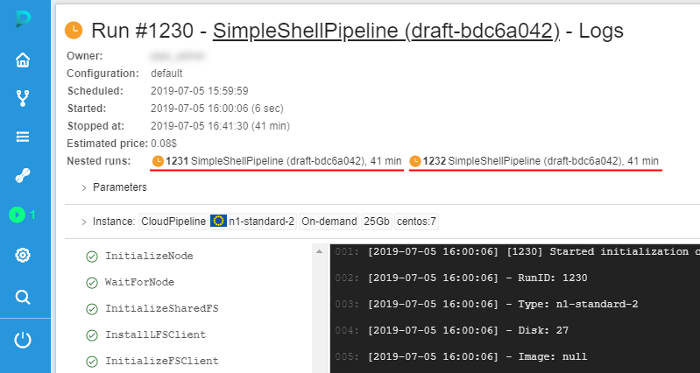
More information about nested runs displaying see here and here.
Environment Modules support for the Cloud Pipeline runs
The Environment Modules package provides for the dynamic modification of a user's environment via modulefiles.
In current version, an ability to configure the Modules support for the compute jobs is introduced, if this is required by any use case.
For using facilities of the Environment Modules package, a new system parameter was added to the Cloud Pipeline:
CP_CAP_MODULES(boolean) - enables installation and using theModulesfor the current run (for all supported Linux distributions)
If CP_CAP_MODULES system parameter is set - the Modules will be installed and made available. While installing, Modules will be configured to the source modulefiles path from the CP_CAP_MODULES_FILES_DIR launch environment variable (value of this variable could be set only by admins via system-level settings). If that variable is not set - default modulefiles location will be used.
See an example here.
Sharing SSH access to running instances with other user(s)/group(s)
As was introduced in Release Notes v.0.13, for certain use cases it is beneficial to be able to share applications with other users/groups.
v0.15 introduces a feature that allows to share the SSH-session of any active run (regardless of whether the job type is interactive or not):
- The user can share an interactive run with others:
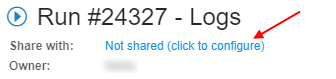
- "Share with: ..." parameter, within a run log form, can be used for this
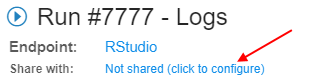
- Specific users or whole groups can be set for sharing
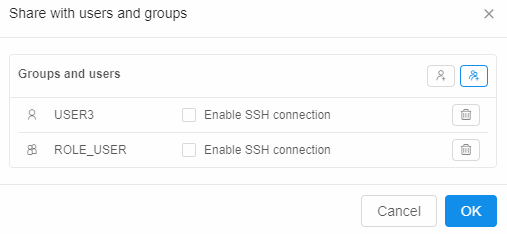
- Once this is set - other users will be able to access run's endpoints
- Also you can share SSH access to the running instance via setting "Enable SSH connection" checkbox
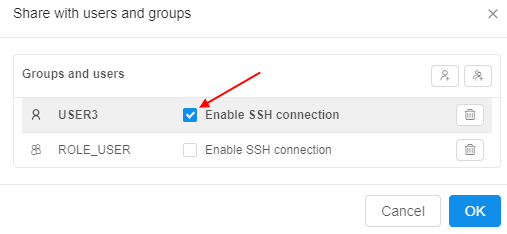
- "Share with: ..." parameter, within a run log form, can be used for this
- Also, the user can share a non-interactive run:
- "Share with: ..." parameter, within a run log form, can be used for this
- Specific users or whole groups can be set for sharing
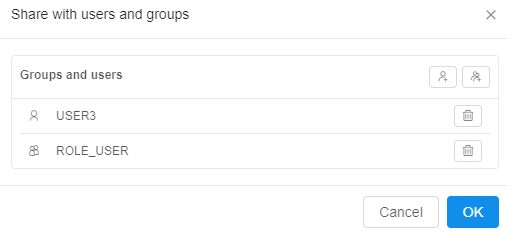
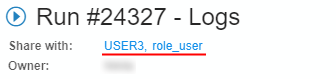
- Once this is set - specified users/groups will be able to access the running instance via the SSH
- "Share with: ..." parameter, within a run log form, can be used for this
- SERVICES widget within a Home dashboard page lists such "shared" services. It displays a "catalog" of services, that can be accessed by a current user, without running own jobs.
To open shared instance application user should click the service name.
To get SSH-access to the shared instance (regardless of whether the job type is interactive or not), the user should hover over the service "card" and click the SSH hyperlink
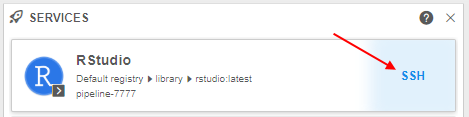
For more information about runs sharing see 11.3. Sharing with other users or groups of users.
Allow to limit the number of concurrent SSH sessions
Previously, some users could try to start a real big number of Web SSH sessions. If 1000+ SSH sessions are established via EDGE service, the performance will degrade. It is not common, but it could be critical as it affects all the users of the platform deploment.
To avoid such cases, in v0.15 the pipectl parameter CP_EDGE_MAX_SSH_CONNECTIONS (with default value 25) for the EDGE server is introduced, that allows to control a number of simultaneous SSH connections to a single job.
Now, if this max number will be reached, the next attemp to open another one Web SSH session to the same job will return a notification to the user and a new session will not be opened until the any one previous is closed:

Verification of docker/storage permissions when launching a run
Users are allowed to launch pipeline, detached configuration or tool if they have a corresponding permission for that executable.
But in some cases this verification is not enough, e.g. when user has no read permission for input parameter - in this case, run execution could cause an error.
In v0.15 additional verification implemented that checks if:
executionis allowed for specified docker image;readoperations are allowed for input and common path parameters;writeoperations are allowed for output path parameters.
If there are such permission issues, run won't be launched and special warning notifications will be shown to a user, e.g.:
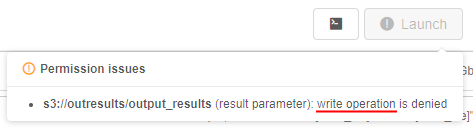
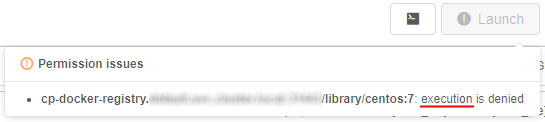
For more details see sections 6.2. Launch a pipeline, 7.2. Launch Detached Configuration and 10.5. Launch a Tool.
Ability to override the queue/PE configuration in the GE configuration
Previously, if the Grid Engine was enabled, the following was configured:
- a single
queuewith all the hosts was creating, named "main.q" - a single
PE(Parallel Environment) was creating, named "local"
In v0.15, the overriding of the names of the queue/PE is implemented to be compatible with any existing scripts, that rely on a specific GE configuration (e.g. hardcoded).
You can do it using two new System Parameters at the Launch or the Configuration forms:

CP_CAP_SGE_QUEUE_NAME(string) - allows to override the GE'squeuename (default: "main.q")CP_CAP_SGE_PE_NAME(string) - allows to override the GE'sPEname (default: "local")
More information how to use System Parameters when a job is launched see here.
Estimation run's disk size according to the input/common parameters
Previously, if a job was run with the disk size, which was not enough to handle the job's inputs - it failed (e.g. 10Gb disk was set for a run, which processed data using STAR aligner, where the genome index file is 20Gb).
In v0.15, an attempt to handle some of such cases is implemented. Now, the Cloud Pipeline try to estimate the required disk size using the input/common parameters and warn the user if the requested disk is not enough.
When a job is launching, the system try to get the size of all input/common parameters. The time of the size getting for all files is limited, as this may take too much for lots of small files. Limit for this time is set by the storage.listing.time.limit system preference (in milliseconds). Default: 3 sec (3000 milliseconds). If computation doesn't end in this timeout, accumulated size will return as is.
If the resulting size of all input/common parameters is greater than requested disk size (considering cluster configuration) - the user will be warned:
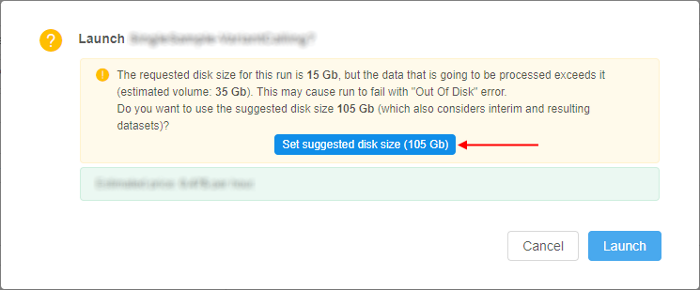
User can set suggested disk size or launch a job at user's own risk with the requested size.
If calculated suggested disk size exceeds 16Tb (hard limit) a different warning message will be shown:
The requested disk size for this run is <N> Gb, but the data that is going to be processed exceeds 16 Tb (which is a hard limit).
Please use the cluster run configuration to scale the disks horizontally or reduce the input data volume.
Do you want to use the maximum disk size 16 Tb anyway?
Disabling of the Global Search form if a corresponding service is not installed
Version 0.14 introduced the Global Search feature over all Cloud Pipeline objects.
In current version, a small enhancement for the Global Search is implemented. Now, if the search.elastic.host system preference is not set by admin - other users will not be able to try search performing:
- the "Search" button will be hidden from the left menu
- keyboard search shortcut will be disabled
Disabling of the FS mounts creation if no FS mount points are registered
In the Cloud Pipeline, along with the regular data storages user can also create FS mounts - data storages based on the network file system:
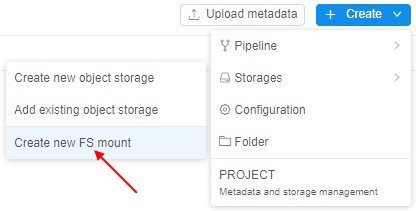
For the correct FS mount creation, at least one mount point shall be registered in the Cloud Pipeline Preferences.
Now, if no FS mount points are registered for any Cloud Region in the System Preferences - user can not create a new FS mount, the corresponding button becomes invisible:
Displaying resource limit errors during run resuming
User may hit a situation of resource limits while trying to resume previously paused run. E.g. instance type was available when run was initially launched, but at the moment of resume operation provider has no sufficient capacity for this type. Previously, in this case run could be failed with an error of insufficient resources.
In v0.15 the following approach is implemented for such cases:
- resuming run doesn't fail if resource limits are hit. That run returns to the
Pausedstate - log message that contains a reason for resume failure and returning back to the
Pausedstate is being added to theResumeRuntask - user is notified about such event. The corresponding warning messages are displayed:
- at the Run logs page

- at the ACTIVE RUNS page (hint message while hovering the RESUME button)

- at the ACTIVE RUNS panel of the Dashboard (hint message while hovering the RESUME button)
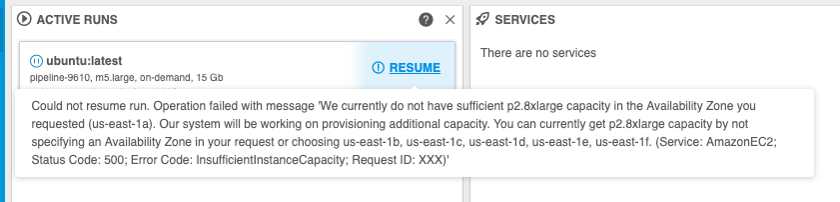
- at the Run logs page
Object storage creation in despite of that the CORS/Policies could not be applied
Previously, if the Cloud service account/role had permissions to create object storages, but lacked permissions to apply CORS or other policies - object storage was created, but the Cloud Pipeline API threw an exception and storage was not being registered.
This led to the creation of a "zombie" storage, which was not available via GUI, but existed in the Cloud.
Currently, the Cloud Pipeline API doesn't fail such requests and storage is being registered normally.
But the corresponding warning will be displayed to the user like this:
The storage {storage_name} was created, but certain policies were not applied.
This can be caused by insufficient permissions.
Track the confirmation of the "Blocking" notifications
System events allow to create popup notifications for users.
One of the notification types - the "Blocking" notification. Such event emerges in the middle of the window and requires confirmation from the user to disappear for proceeding with the GUI operations.
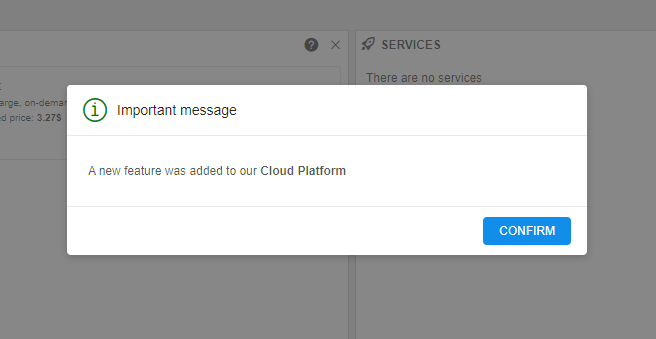
In certain cases (e.g. for some important messages), it is handy to be able to check which users confirmed the notification.
For that, in the current version the ability to view, which "blocking" notifications confirmed by specific user, was implemented for admins.
Information about confirmed notifications can be viewed at the "Attributes" section of the specific user's profile page:
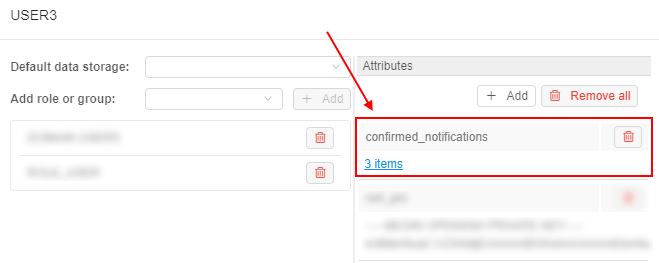
Confirmed notifications are displayed as user attribute with the KEY confirmed_notifications (that name could be changed via the system-level preference system.events.confirmation.metadata.key) and the VALUE link that shows summary count of confirmed notifications for the user.
Click the VALUE link with the notification count to open the detailed table with confirmed notifications:
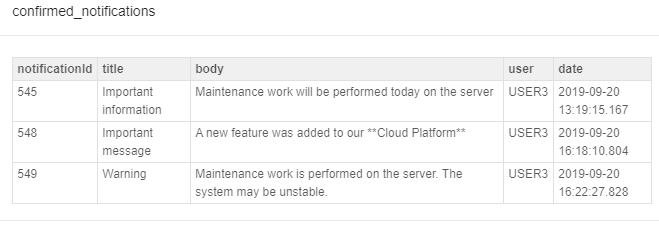
For more details see "blocking" notifications track.
pipe CLI warnings on the JWT expiration
By default, when pipe CLI is being configured JWT token is given for one month, if user didn't select another expiration date.
In v.0.15 extra pipe CLI warnings are introduced to provide users an information on the JWT token expiration:
- When
pipe configurecommand is executed - the warning about the expiration date of the provided token is printed, if it is less than 7 days left:

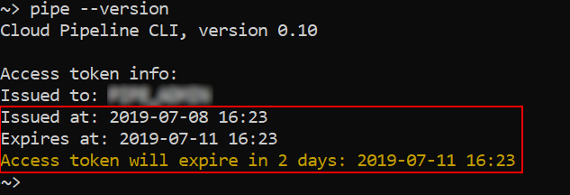
- When
--versionoption is specified -pipeprints dates of issue and expiration for the currently used token:
- When any other command is running - the warning about the expiration date of the provided JWT token is printed, if it is less than 7 days left:

See more information about pipe CLI installation here.
pipe configuration for using NTLM Authentication Proxy
For some special customer needs, pipe configuration for using NTLM Authentication Proxy, when running in Linux, could be required.
For that, several new options were added to pipe configure command:
-ntor--proxy-ntlm- flag that enable NTLM proxy support-nuor--proxy-ntlm-user- username for NTLM proxy authorization-npor--proxy-ntlm-pass- password for NTLM proxy authorization-ndor--proxy-ntlm-domain- domain for NTLM proxy authorization
If --proxy-ntlm is set, pipe will try to get the proxy value from the environment variables or --proxy option (--proxy option has a higher priority).
If --proxy-ntlm-user and --proxy-ntlm-pass options are not set - user will be prompted for username/password in an interactive manner.
Valid configuration examples:
- User will be prompted for NTLM Proxy Username, Password and Domain:
pipe configure --proxy-ntlm
...
Username for the proxy NTLM authentication: user1
Domain of the user1 user: ''
Password of the user1 user:
- Use
http://myproxy:3128as the "original" proxy address. User will not be prompted for NTLM credentials:
pipe configure --proxy-ntlm --proxy-ntlm-user $MY_NAME --proxy-ntlm-pass $MY_PASS --proxy "http://myproxy:3128"
See more information about pipe CLI installation and configure here.
Execution of files uploading via pipe without failures in case of lacks read permissions
Previously, pipe storage cp/mv commands could fail if a "local" source file/dir lacked read permissions. For example, when user tried to upload to the "remote" storage several files and when the pipe process had reached one of files that was not readable for the pipe process, then the whole command was being failed, remaining files did not upload.
In current version, the pipe process checks read permission for the "local" source (directories and files) and skip those that are not readable:

Run a single command or an interactive session over the SSH protocol via pipe
For the certain purposes, it could be conveniently to start an interactive session over the SSH protocol for the job run via the pipe CLI.
For such cases, in v0.15 the pipe ssh command was implemented. It allows you, if you are the ADMIN or the run OWNER, to perform a single command or launch an interactive session for the specified job run.
Launching of an interactive session:

This session is similar to the terminal access that user can get via the GUI.
Performing the same single command without launching an interactive session:

Perform objects restore in a batch mode via pipe
Users can restore files that were removed from the data storages with enabled versioning.
For these purposes, the Cloud Pipeline's CLI has the restore command which is capable of restoring a single object at a time.
In v0.15 the ability to recursively restore the whole folder, deleted from the storage, was implemented.
Now, if the source path is a directory, the pipe storage restore command gets the top-level deleted files from the source directory and restore them to the latest version.
Also, to the restore command some options were added:
-ror--recursive- flag allows to restore the whole directory hierarchy-ior--include [TEXT]- flag allows to restore only files which names match the [TEXT] pattern and skip all others-eor--exclude [TEXT]- flag allows to skip restoring of files which names match the [TEXT] pattern and restore all others
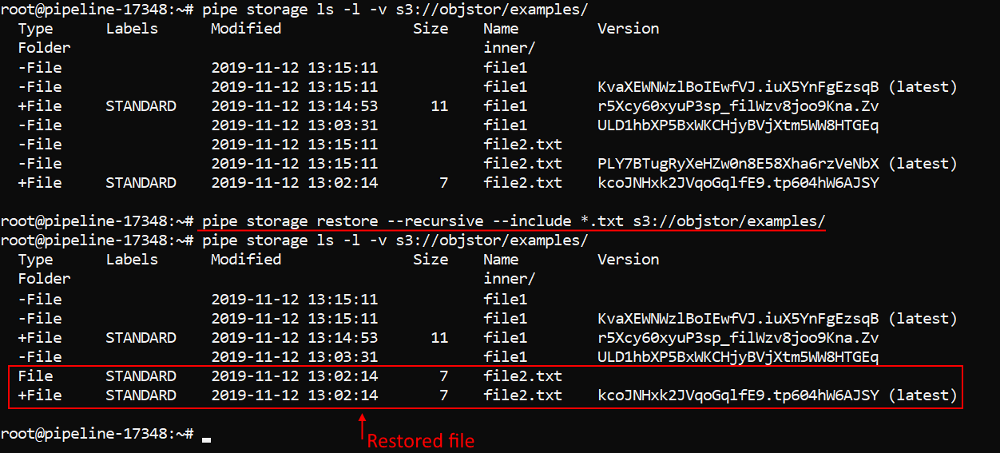
Note: this feature is yet supported for AWS only.
For more details about file restoring via the pipe see here.
Mounting data storages to Linux and Mac workstations
Previously, when users had to copy/move datasets to/from Cloud data storages via CLI, they could use only special pipe storage commands.
That was not always comfortable or could lead to some functionality restrictions.
In v0.15 the ability to mount Cloud data storages (both - File Storages and Object Storages) to Linux and Mac workstations (requires FUSE installed) was added.
For the mounted storages, regular listing/read/write commands are supported, users can manage files/folders as with any general hard drive.
Note: this feature is yet supported for
AWSonly.
To mount a data storage into the local mountpoint the pipe storage mount command was implemented. It has two main options that are mutually exclusive:
-for--filespecifies that all available file systems should be mounted into a mountpoint-bor--bucket [STORAGE_NAME]specifies a storage name to mount into a mountpoint
Users can:
- leverage mount options, supported by underlying
FUSEimplementation, via-ooption - enable multithreading for simultaneously interaction of several processes with the mount point, via
-toption - trace all information about mount operations into a log-file, via
-loption
To unmount a mountpoint the pipe storage umount command was implemented.
For more details about mounting data storages via the pipe see here.
Allow to run pipe commands on behalf of the other user
In the current version, the ability to run pipe commands on behalf of the other user was implemented.
It could be convenient when administrators need to perform some operations on behalf of the other user (e.g. check permissions/act as a service account/etc.).
This feature is implemented via the common option that was added to all pipe commands: --user|-u <USER_ID> (where <USER_ID> is the name of the user account).
Note: the option isn't available for the following pipe commands: configure, --version, --help.
If this option is specified - operation (command execution) will be performed using the corresponding user account, e.g.:
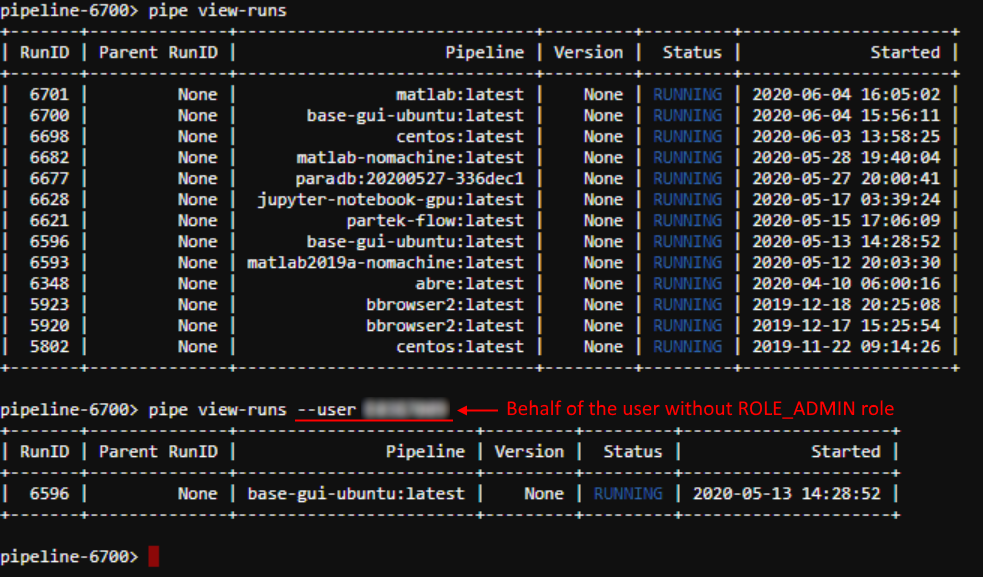
In the example above, active runs were outputted from the admin account (firstly) and then on behalf of the user without ROLE_ADMIN role.
Additionally, a new command pipe token <USER_ID> was implemented. It prints the JWT token for a specified user.
This command also can be used with non-required option -d (--duration), that specified the number of days the token will be valid. If it's not set - the default value will be used, same as in the GUI.
Example of using:

Then, the generated JWT token could be used manually with the pipe configure command - to configure pipe CLI on behalf of the desired user.
Note: both - the command (pipe token) and the option (--user) - are available only for admins.
For more details see here.
Ability to restrict the visibility of the jobs
Previously, Cloud Pipeline inherited the pipeline jobs' permissions from the parent pipeline object. So, if two users had permissions on the same pipeline, then when the first user had launched that pipeline - the second user also could view (not manage) launched run in the Active Runs tab.
Now admin can restrict the visibility of the jobs for non-owner users. The setting of such visibility can get one of the following values:
Inherit- the behavior is the same as described above (for the previous approach), when the runs visibility is controlled by the pipeline permissions. It is set as a default for theCloud PipelineenvironmentOnly owner- when only the person who launch a run can see it
Jobs visibility could be set by different ways on several forms:
- within User management tab in the system-level settings admin can specify runs visibility for a user/group/role:
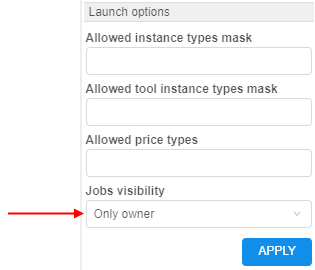
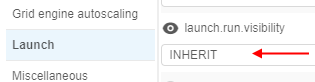
- within Launch section of Preferences tab in the system-level settings admin can specify runs visibility for a whole platform as global defaults - by the setting
launch.run.visibility:
Next hierarchy is set for applying of specified jobs visibility:
- User level - highest priority (specified for a user)
- Group level (specified for a group/role)
- Platform level
launch.run.visibility(specified as global defaults via system-level settings)
Note: admins can see all runs despite of settings
Ability to perform scheduled runs from detached configurations
Previously, Cloud Pipeline allowed starting compute jobs only manually (API/GUI/CLI).
But in certain use cases, it is beneficial to launch runs on a scheduled basis.
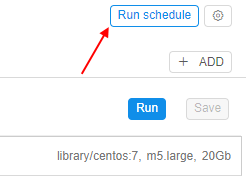
In v0.15 the ability to configure a schedule for detached configuration was implemented:
- User is able to set a schedule for launch a run from the detached configuration:
- Schedule is defined as a list of rules - user is able to specify any number of them:
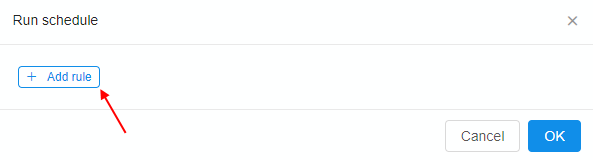
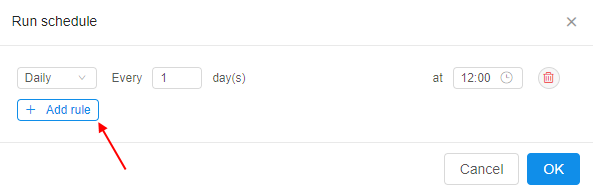
- For each rule in the list user is able to set the recurrence:
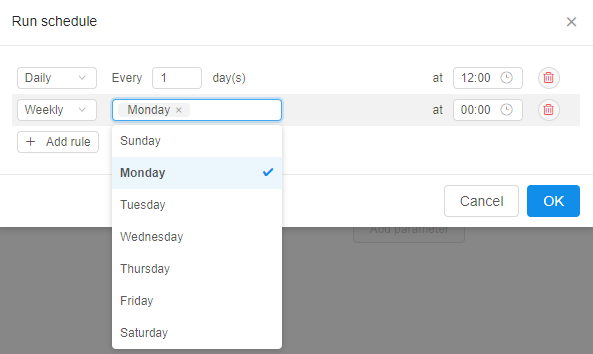
If any schedule rule is configured for the detached configuration - a corresponding job (plain container or a pipeline) will be started accordingly in the scheduled day and time.
See more details here.
The ability to use custom domain names as a "friendly URL" for the interactive services
In v0.13 the ability to set a "friendly URL" for the interactive services endpoint was implemented. It allows to configure the view of the interactive service endpoint:
- Default view:
https://<host>/pipeline-<run-id>-<port> - "Friendly" view:
https://<host>/<friendly-url>
In the current version this feature is expanded: users allow to specify a custom host.
So the endpoint url now can look like: https://<custom-host> or https://<custom-host>/<friendly-url>.
Note: custom host should exist, be valid and configured.
The custom host is being specified into the same field as a "friendly URL" previously, e.g.:
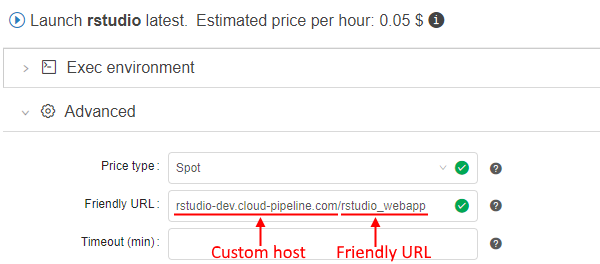
Final URL for the service endpoint will be generated using the specified host and friendly URL:
For more details see here.
Displaying of the additional support icon/info
In certain cases, users shall have a quick access to the help/support information (e.g. links to docs/faq/support request/etc.)
In the current version, the ability to display additional "support" icon with the corresponding info in the bottom of the main menu was implemented:
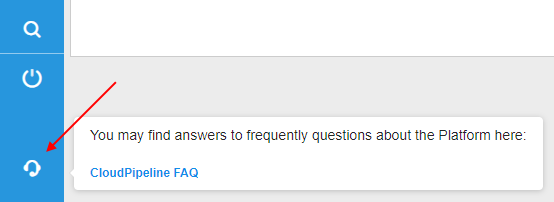
The displaying of this icon and the info content can be configured by admins via the system-level preference ui.support.template:
- this preference is empty by default - in this case the support icon is invisible
- if this preference contains any text (
Markdown-formatted):- the support icon is visible
- specified text is displayed in the support icon tooltip (support info)
For more details see UI system settings.
Pass proxy settings to the DIND containers
Previously, DIND containers configuration included only registry credentials and a couple of driver settings.
In certain environments, it is not possible to access external networks (e.g. for the packages installation) without the proxy settings.
So the users had to pass this manually every time when using the docker run command.
In the current version, a new system preference launch.dind.container.vars is introduced. It allows to specify all the additions variables, which will be passed to the DIND containers (if they are set for the host environment).
By default, the following variables are set for the launch.dind.container.vars preference (and so will be passed to DIND container): http_proxy,https_proxy, no_proxy, API, API_TOKEN. Variables are being specified as a comma-separated list.
Example of using:

At the same time, a new system parameter (per run) was added - CP_CAP_DIND_CONTAINER_NO_VARS, which disables described behavior. You can set it before any run if you don't want to pass any additional variations to the DIND container.
Interactive endpoints can be (optionally) available to the anonymous users
Cloud Pipeline allows sharing the interactive and SSH endpoints with the other users/groups.
Previously, this necessary required the end-user to be registered in the Cloud Pipeline users database.
For certain use-cases, it is required to allow such type of access for any user, who has successfully passed the IdP authentication but is not registered in the Cloud Pipeline and also such users shall not be automatically registered at all and remain Anonymous.
In the current version, such ability is implemented. It's enabled by the following application properties:
saml.user.auto.create=EXPLICIT_GROUPsaml.user.allow.anonymous=true
After that, to share any interactive run with the Anonymous - it's simple enough to share endpoints with the following user group - ROLE_ANONYMOUS_USER:
- At the Run logs page:

- The user should select the
ROLE_ANONYMOUS_USERrole to share:
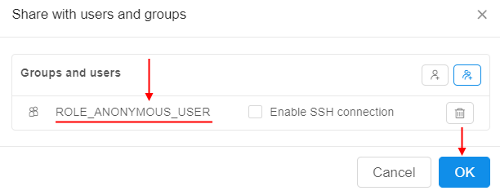
- Sharing with the
Anonymouswill be displayed at the Run logs page:

- That's all. Now, the endpoint-link of the run could be sent to the
Anonymoususer.
If that Anonymous user passes SAML authentication, he will get access to the endpoint. Attempts to open any other Platform pages will fail.
For more details see here.
Notable Bug fixes
Incorrect behavior of the global search filter
When user was searching for an entry, that may belong to different classes (e.g. issues and folders) - user was not able to filter the results by the class.
"COMMITTING..." status hangs
In certain cases, while committing pipeline with the stop flag enabled - the run's status hangs in Committing... state. Run state does not change even after the commit operation succeeds and a job is stopped.
Instances of Metadata entity aren't correctly sorted
Metadata entities (i.e. project-related metadata) sorting was faulty:
- Sort direction indicator (Web GUI) was displaying an inverted direction
- Entities were not sorted correctly
Tool group cannot be deleted until all child tools are removed
If there is a tool group in the registry, which is not empty (i.e. contains 1+ tools) - an attempt to delete it throws SQL error.
It works fine if the child tools are dropped beforehand.
Now, it is possible to delete such a group if a force flag is set in the confirmation dialog.
Missing region while estimating a run price
On the launch page, while calculating a price of the run, Cloud Provider's region was ignored. This way a calculation used a price of the specified instance type in any of the available regions. In practice, requested price may vary from region to region.
Cannot specify region when an existing object storage is added
Web GUI interface was not providing an option to select a region when adding an existing object storage. And it was impossible to add a bucket from the non-default region.
ACL control for PIPELINE_USER and ROLE entities for metadata API
All authorized users were permitted to browse the metadata of users and roles entities. But those entries may contain a sensitive data, that shall not be shared across users.
Now, a general user may list only personal user-level metadata. Administrators may list both users and roles metadata across all entries.
Getting logs from Kubernetes may cause OutOfMemory error
For some workloads, container logs may become very large: up to several gigabytes. When we tried to fetch such logs it is likely to cause OutOfMemory error, since Kubernetes library tries to load it into a single String object.
In current version, a new system preference was introduced: system.logs.line.limit. That preference sets allowable log size in lines. If actual pod logs exceeds the specified limit only log tail lines will be loaded, the rest will be truncated.
AWS: Incorrect nodeup handling of spot request status
Previously, in a situation when an AWS spot instance created after some timeout - spot status wasn't updated correctly in the handling of spot request status. It might cause errors while getting spot instance info.
Not handling clusters in autopause daemon
Previously, if cluster run was launched with enabled "Auto pause" option, parent-run or its child-runs could be paused (when autopause conditions were satisfied, of course). It was incorrect behavior because in that case, user couldn't resume such paused runs and go on his work (only "Terminate" buttons were available).
In current version, autopause daemon doesn't handle any clusters ("Static" or "Autoscaled").
Also now, if the cluster is configured - Auto pause checkbox doesn't display in the Launch Form for the On-Demand node types.
Incorrect pipe CLI version displaying
Previously, pipe CLI version displayed incorrectly for the pipe CLI installations performed via hints from the Cloud Pipeline System Settings menu.
JWT token shall be updated for the jobs being resumed
In cases when users launched on-demand jobs, paused them and then, after a long time period (2+ months), tried to resume such jobs - expired JWT tokens were set for them that led to different problems when any of the initialization routines tried to communicate with the API.
Now, the JWT token and other variables as well are being updated when a job is being resumed.
Trying to rename file in the data storage, while the "Attributes" panel is opened, throws an error
Renaming file in the datastorage with opened "Attributes" panel caused an unexpected error.
pipe: incorrect behavior of the -nc option for the run command
#609
Previously, trying to launch a pipeline via the pipe run command with the single -nc option threw an error.
Cluster run cannot be launched with a Pretty URL
Previously, if user tried to launch any interactive tool with Pretty URL and configured cluster - an error appeared URL {Pretty URL} is already used for run {Run ID}.
Now, pretty URL could be set only for the parent runs, for the child runs regular URLs are set.
Cloning of large repositories might fail
When large repository (> 1Gb) was cloned (e.g. when a pipeline was being run) - git clone could fail with the OOM error happened at the GitLab server if it is not powerful enough.
OOM was produced by the git pack-objects process, which tries to pack all the data in-memory.
Now, git pack-objects memory usage is limited to avoid errors in cases described above.
System events HTML overflow
If admin set a quite long text (without separators) into the message body of the system event notifications - the resulting notification text "overflowed" the browser window.
Now, text wrapping is considered for such cases.
Also, support of Markdown was added for the system notification messages:
AWS: Pipeline run InitializeNode task fails
Previously, if AWS spot instance could not be created after the specific number of attempts during the run initialization - such run was failed with the error, e.g.: Exceeded retry count (100) for spot instance. Spot instance request status code: capacity-not-available.
Now, in these cases, if spot instance isn't created after specific attempts number - the price type is switched to on-demand and run initialization continues.
git-sync shall not fail the whole object synchronization if a single entry errors
When the git-sync script processed a repository and failed to sync permissions of a specific user (e.g. git exception was thrown) - the subsequent users were not being processed for that repository.
Now, the repository sync routine does not fail if a single user cannot be synced. Also, the issues with the synchronization of users with duplicate email addresses and users with empty email were resolved.
endDate isn't set when node of a paused run was terminated
Previously, when user terminated the node of a paused run - endDate for that run wasn't being set. This was leading to wrong record of running time for such run.
AWS: Nodeup retry process may stuck when first attempt to create a spot instance failed
Previously, if first nodeup attempt failed due to unavailablity to connect on 8888 port (in expected amounts of attempts) after getting instance running state, the second nodeup attempt might stuck because it waited for the same instance (associated with existed SpotRequest for the first attempt) to be up. But it couldn't happen - this instance was already in terminating state after the first attempt.
Now, checks that instance associated with SpotRequest (created for the first attempt) is in appropriate status, if not - a new SpotRequest is being created and the nodeup process is being started from scratch.
Resume job timeout throws strange error message
Previously, the non-informative error message was shown if the paused run could't be resumed in a reasonable amount of time - the count of attempts to resume was displaying incorrectly.
GE autoscaler doesn't remove dead additional workers from cluster
Previously, the Grid Engine Autoscaler didn't properly handle dead workers downscaling. For example, if some spot worker instance was preempted during the run then the autoscaler could not remove such worker from GE. Moreover, such cluster was blocked from accepting new jobs.
Broken layouts
Previously, pipeline versions page had broken layout if there were pipeline versions with long description.
Global search page was not rendered correctly when the search results table had too many records.
When a list of items in the docker groups selection dialog was long - it was almost impossible to use a search feature, as the list hid immediately.
Some of the other page layouts also were broken.