11. Manage Runs
- Overview
- ACTIVE RUNS
- COMPLETED RUNS
- Run information page
- Automatically rerun if a spot instance is terminated
Overview
"Runs" provides a list of active and completed pipeline runs. You can get parameters and logs of specific run and stop run here.
"Runs" space has two tabs:
- Active runs view
- Completed runs view.
Runs are organized in a table which is the same for both tabs:
- "State" icon - state of the run.
- Run - include:
- run name (upper row) - pipeline name and run id
- Cloud Region (bottom row)
Note: if a specific platform deployment has a number of Cloud Providers registered (e.g.
AWS+Azure,GCP+Azure) - corresponding text information also has a Provider name, e.g.:

- Parent run - parent run ID, if a run was launched by another run.
- Pipeline - include:
- pipeline name (upper row) - a name of a pipeline
- version name (bottom row) - a name of a pipeline version
- Docker image - a name of docker image.
- Started - time when a run was started.
- Completed - time when a run was finished.
- Elapsed - include:
- elapsed time (upper row) - a duration of a run
- estimated price (bottom row) - estimated price of run, which is calculated based on the run duration and selected instance type. This field is updated interactively (i.e. each 5 - 10 seconds).
- Owner - a user, which launched a run.
Note: also you can view information about runs via CLI. See here.
ACTIVE RUNS
This tab displays a list of all pipelines that are currently running.

Active run states
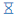 - Queued state ("sandglass" icon) - a run is waiting in the queue for the available compute node.
- Queued state ("sandglass" icon) - a run is waiting in the queue for the available compute node. - Initializing state ("rotating" icon) - a run is being initialized, at this stage a new compute node will be created or an existing node will be reused.
- Initializing state ("rotating" icon) - a run is being initialized, at this stage a new compute node will be created or an existing node will be reused. - Pulling state ("download" icon) - now pipeline Docker image is downloaded to the node.
- Pulling state ("download" icon) - now pipeline Docker image is downloaded to the node. - Running state (stable "play" icon) - a pipeline is running. The node is appearing and pipeline input data is being downloaded to the node before the "InitializeEnvironment" service task appears.
- Running state (stable "play" icon) - a pipeline is running. The node is appearing and pipeline input data is being downloaded to the node before the "InitializeEnvironment" service task appears.- Pausing state (blinking "pause" icon) - a run is being paused. At this moment compute node will be stopped (but persisted) and the docker image state will be kept as well.
 - Paused state (stable "pause" icon) - a run is paused. At this moment compute node is already stopped but keeps it's state. Such run may be resumed.
- Paused state (stable "pause" icon) - a run is paused. At this moment compute node is already stopped but keeps it's state. Such run may be resumed.- Resuming state (blinking "play" icon) - a paused run is being resumed. At this moment compute node is starting back from the stopped state.

Also, help tooltips are provided when hovering a run state icon, e.g.:
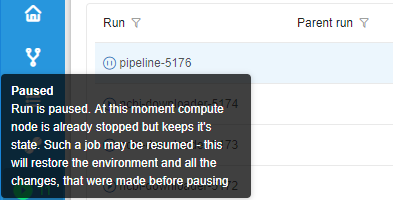
Tooltips contain a state name in bold (e.g. Queued) and a short description of the state and info on the next stage.
Active run controls
| Control | Description |
|---|---|
| PAUSE/RESUME | Pauses/resumes a run. Available for On-demand non-cluster instances only. Learn more about feature here. |
| TERMINATE | Terminates compute node of a paused run without its resuming. Available for On-demand non-cluster instances only. Learn more about feature here. |
| STOP | This control stops a run execution. |
| LOG | To open a Run information page, press LOG button. |
Active cluster runs
Cluster is a collection of instances which are connected so that they can be used together on a task.
If launched run uses a cluster or an auto-scaled cluster (see sections here), it has a certain designation:

By default, only master-run is displaying at the table. To view nested runs (child-runs) click the Expand control in front of the muster-run ID:

So, you can view an information about each child-run and its state, also you can stop specific nested run without stopping a parent run. You can open Run logs page (see below) for any of the cluster runs by click it or LOG button next to run ID.
Note: you can't pause cluster runs even with On-demand price type.
Note: stopping a parent run will stop execution of all nested runs too.
For runs with the auto-scaled cluster not all of the child-runs appear in the list immediately after parent run was launched, "scale-up" runs will appear only of necessity.
Displaying additional node metrics
According to the run states and system-level settings, additional metrics (labels) could be displayed for active runs:
 - Idle label - displays only for runs in Running state, for which node's CPU consumption level is below than a certain threshold for a certain period of time or longer.
- Idle label - displays only for runs in Running state, for which node's CPU consumption level is below than a certain threshold for a certain period of time or longer. - Pressure label - displays only for runs in Running state, for which node's Memory/Disk consumption level is higher than a certain threshold.
- Pressure label - displays only for runs in Running state, for which node's Memory/Disk consumption level is higher than a certain threshold.
Values of these thresholds and time period are specified by admins via system-level settings (see here for more details and an example of using - here).
COMPLETED RUNS
This tab displays a list of all pipelines runs that are already finished.

Completed run states
 - Success state ("OK" icon) - successful pipeline execution.
- Success state ("OK" icon) - successful pipeline execution. - Failed state ("caution" icon) - unsuccessful pipeline execution.
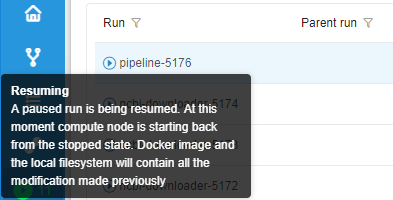
- Failed state ("caution" icon) - unsuccessful pipeline execution. - Stopped state ("clock" icon) - a pipeline manually stopped.
- Stopped state ("clock" icon) - a pipeline manually stopped.
Help tooltips are also provided when hovering a completed run state icon, e.g.:
Completed run controls
| Control | Description |
|---|---|
| LINKS | This control show input/output links of the pipeline |
| RERUN | This control allow rerunning of a completed run. The Launch a pipeline page will be open. |
| LOG | To open a Run information page, press LOG button. |
Completed cluster runs
If completed run used a cluster or an auto-scaled cluster (see sections here), it has a certain designation. Displaying of such runs on the COMPLETED RUNS tab is similar to the active cluster runs. You can view an information about each child-run and its state, also you can rerun specific nested run without a parent run. You can open Run logs page (see below) for any of the cluster runs by click it or LOG button next to run ID:

Run information page
Click a row within a run list, "Run information" page will appear.
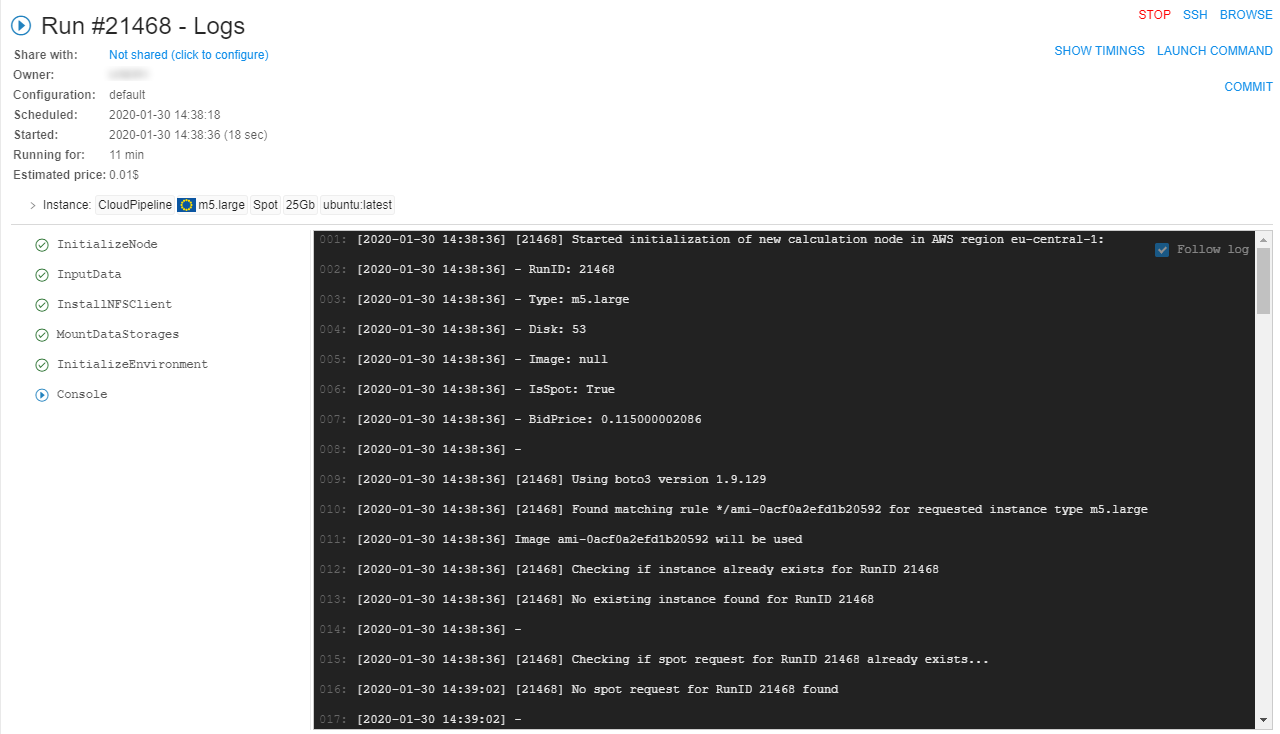
It consists of several sections:
General information
This section displays general information about a run:
| Field | Description |
|---|---|
| State icon | state of the run. Help tooltips are provided when hovering a run state icon, e.g.: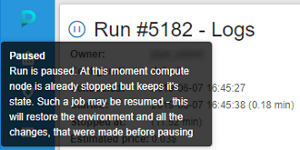 |
| Run ID | unique ID of the run. |
| Endpoint | (available only for tools runs) endpoint hyperlink for the service launched in an interactive tool. For more details see 15. Interactive services. |
| Share with | (available only for tools runs) list of users/groups with whom an interactive tool application is shared. For more details see 11.3 Sharing with other users or groups of users. |
| Owner | a name of the user who started pipeline. |
| Scheduled | time when a pipeline was launched. |
| Waiting for/Running for | time a pipeline has been running. |
| Started | time when the node is initialized and a pipeline has started execution. |
| Finished | time when a pipeline finished execution. |
| Estimated price | price of a run according to a run duration and selected instance type. |
| Nested runs | the child-runs list in cases when a run has a number of children (e.g. a cluster run or any other case with the parent-id specified) |
| Maintenance | the list of rules that define automatical pausing/restarting schedule for on-demand non-clusters runs |
Nested runs
Nested runs list is displaying only for master runs.
It is the list with short informations about cluster child-runs:
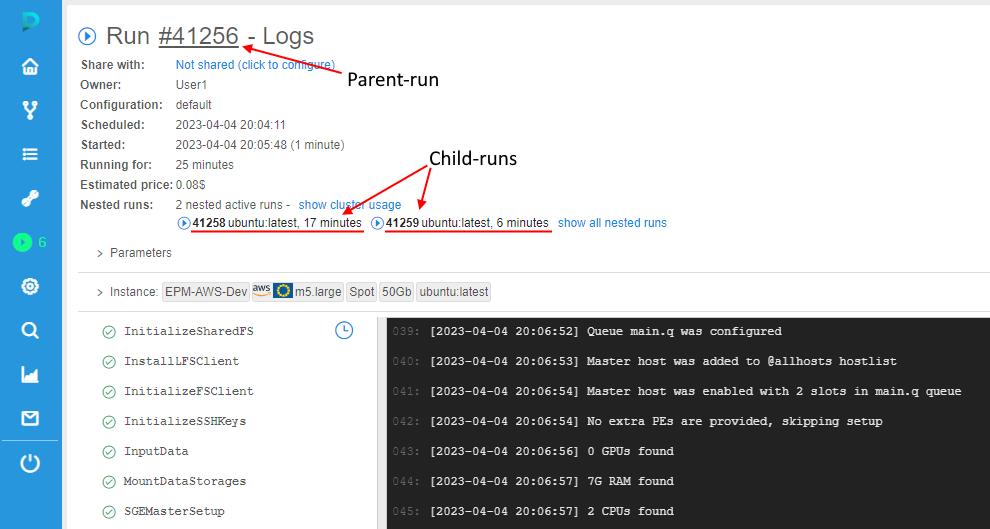
Each child-run record contains:
- State icons with help tooltips when hovering over them
- Pipeline name and version or docker image and version
- Run time duration
Similar as a parent-run state, states for nested runs are automatically updated without page refreshing. To open any child-run logs page - click its name in the list.
If there are several nested runs, only the first couple are displayed at the parent-run logs page.
To view all nested runs - click the corresponding hyperlink:

The full list of nested runs for the selected parent-run will be opened, e.g.:

Cluster run usage
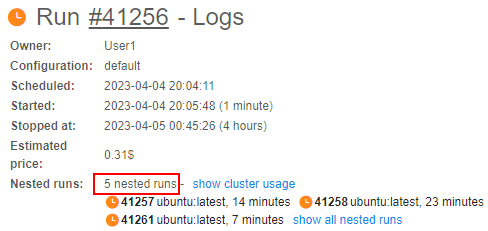
User can view the cluster usage at the parent-run logs page - near the Nested runs label, number of nested runs active at the moment is displayed:
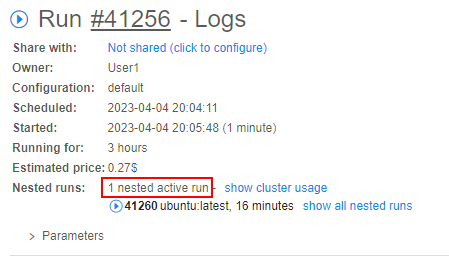
If the cluster run was completed - here, the summary number of nested runs launched during the cluster run is displayed, e.g.:
Also, user can view how the cluster usage has been changing during the run of this cluster.
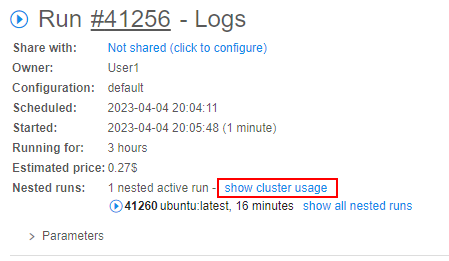
This is especially useful information for auto-scaled clusters, as the number of worker nodes in such clusters can vary greatly over time.
To view the cluster usage - click the corresponding hyperlink near the number of active nested runs:
The chart pop-up will be opened, e.g.:
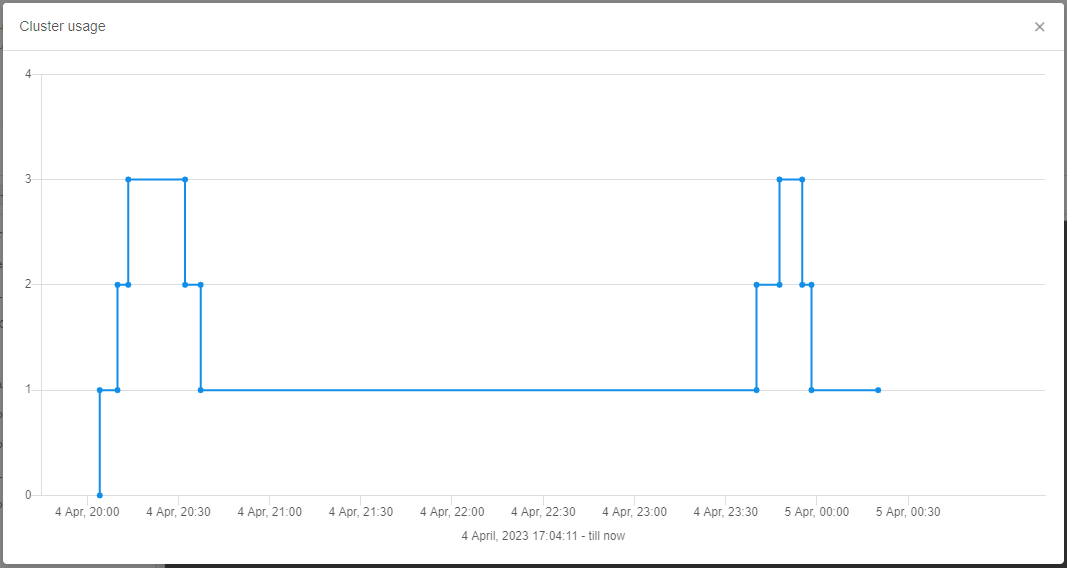
The chart shows a cluster usage - number of all active instances (including the master node) of the current cluster over time.
To view details - hover over the chart point, e.g.:
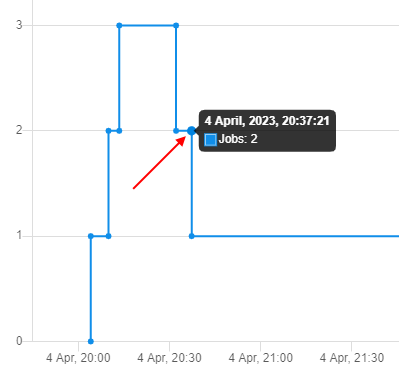
In this case, summary info about the number of active cluster instances in a specific moment will be displayed.
To view which runs exactly were active in the cluster (including the master node) in a specific moment - click the chart point, e.g.:
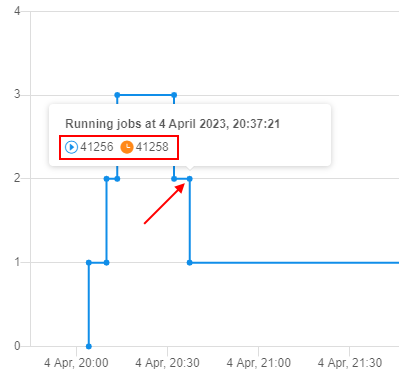
You can click any run ID in such a tooltip - the corresponding run's logs page will be opened.
Please note, the cluster usage chart is available for completed cluster runs as well.
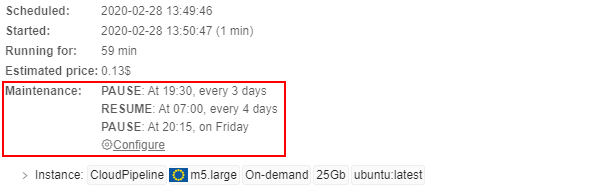
Maintenance
Here user can create/view/edit/remove schedule rules for the specific active launched run. That set rules allow to pause/resume the run automatically in the scheduled day and time.
The Maintenance control is available only for active "On-demand" non-cluster runs.
E.g.:
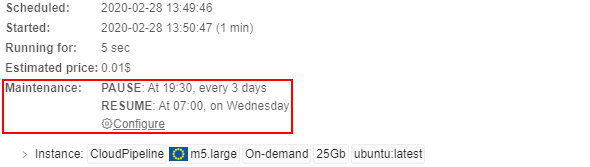
To edit an existing schedule for the active launched run click the Configure button.
The popup with created rules will appear:
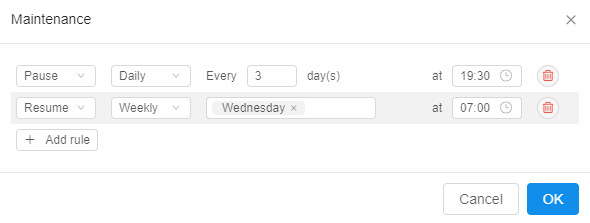
You can, for example, remove an existing rule and add new ones:
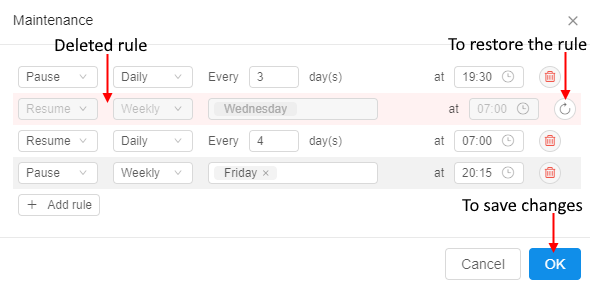
Changes will be displayed at the Run logs page and will be applied to the active run:
In general, this behavior is configured identically to the Maintenance control at the Launch page - for more details see 6.2. Launch a pipeline (item 5).
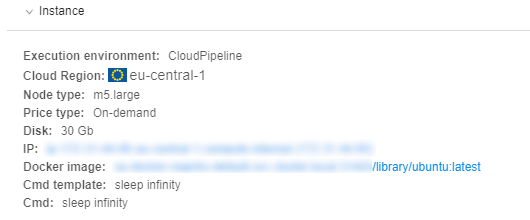
Instance
The "Instance" section lists calculation node and execution environment details that were assigned to the run when it was launched.
Note: node IP is presented as a hyperlink. Clicking it will navigate to the node details, where technical information and resources utilization is available - for more details see here.
Note: Docker image name link leads to a specific Tool's detail page (see an example).
Note: if a specific platform deployment has a number of Cloud Providers registered (e.g.
AWS+Azure,GCP+Azure) - corresponding auxiliary Cloud Provider icon is additionally displayed, e.g.:
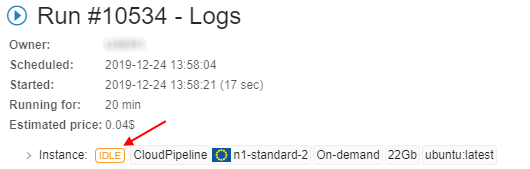
Note: if specific run CPU/Memory/Disk consumption is lower or higher specified in the configurations values, the IDLE or PRESSURE labels will be displayed respectively:
Parameters
The parameters that were assigned to the run when it was launched are contained in this section.
Note: parameters with types input/output/common/path are presented as hyperlinks, and will navigate to appropriate location in a Data Storage hierarchy.
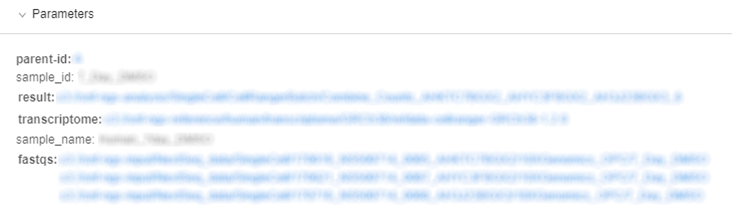
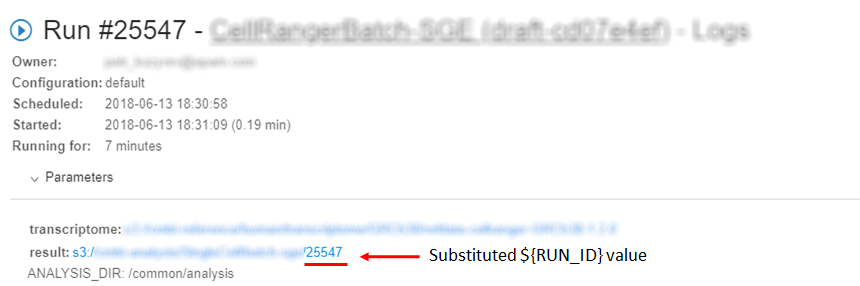
Note: if a user specifies system environment variables in parameter (e.g. RUN_ID), GUI will substitute these variables with their values automatically in the "Run information" page.

Tasks
Here you can find a list of tasks of pipeline that are being executed or already finished.
Clicking a task and its console output will be loaded in the right panel.
Console output
Here you can view console output from a whole pipeline or a selected task. It also shows a run failure cause if a run failed.
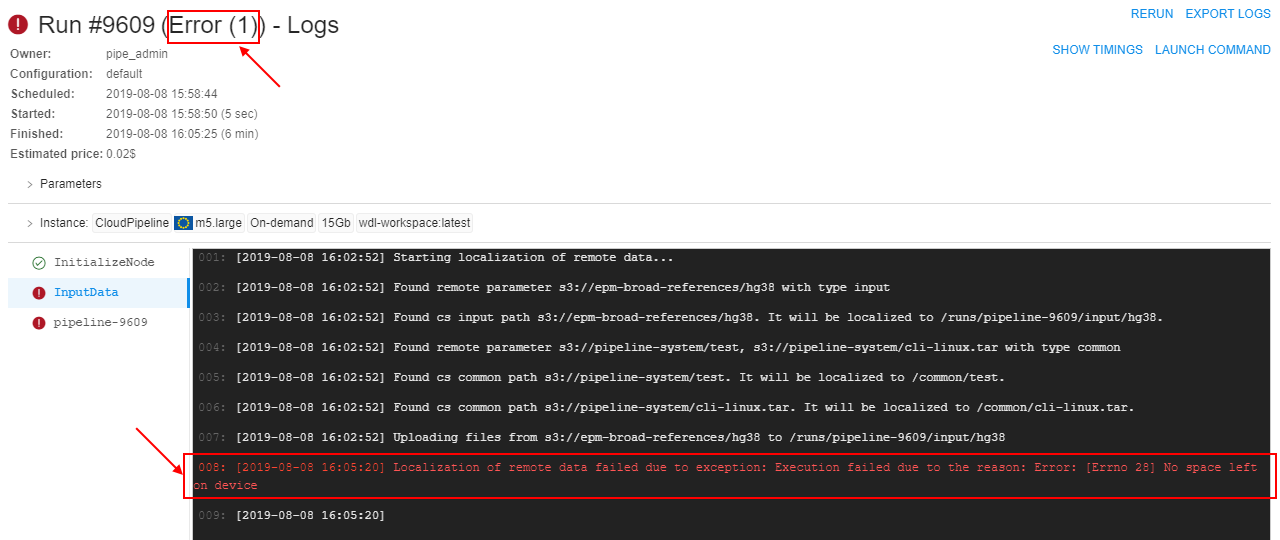
Note: the Follow log control enables auto scrolling of the console output. It is useful for logs monitoring. Follow log is enabled by default, tick the box to turn it off.

Also, during a pipeline run an extended node-level logging is maintained:
kubeletlogs (from all compute nodes) are written to the files- Log files are streamed to the storage, identified by the
storage.system.storage.namepreference
Users with the ROLE_ADMIN role can find the corresponding node logs (e.g. by the hostname or ip that are attached to the run information) in that storage by the path logs/nodes/{hostname}:
- Open the Run logs page of the run you want to see
kubeletlogs - Select the InitializeNode task, find a node hostname in the console output:
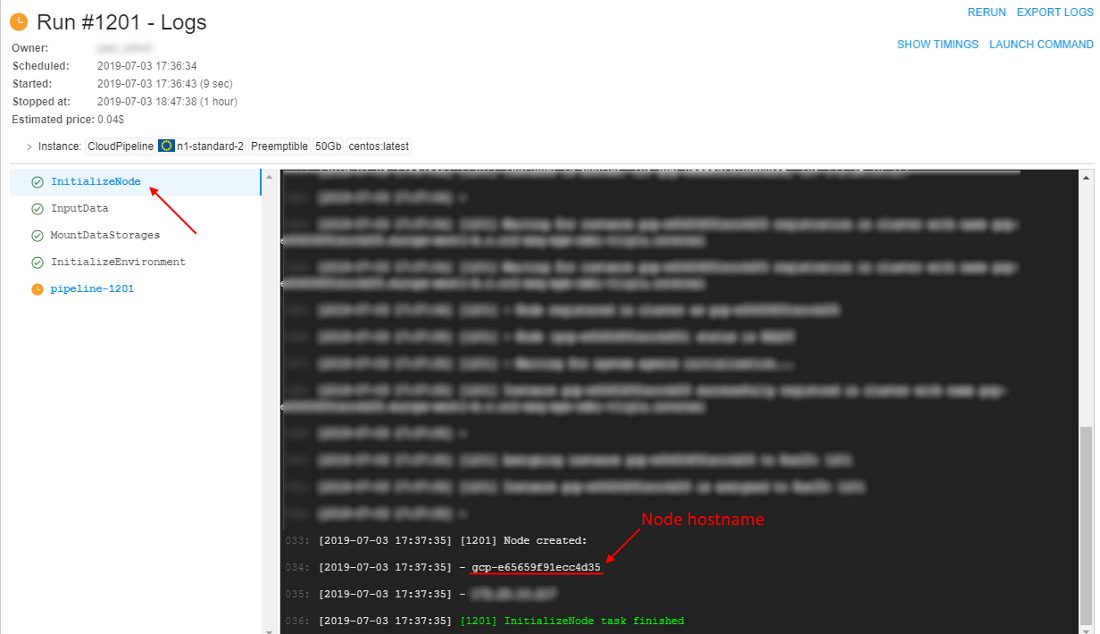
Copy the found hostname's value. - Check the storage path specified at the
storage.system.storage.namepreference:
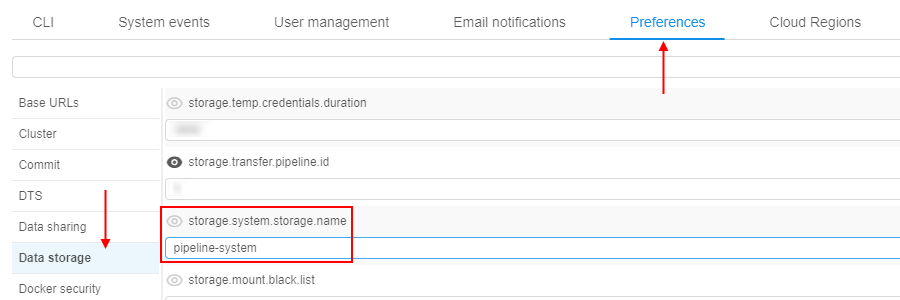
Open in the Library that storage. - Navigate in the opened storage to the path
logs/nodes/:
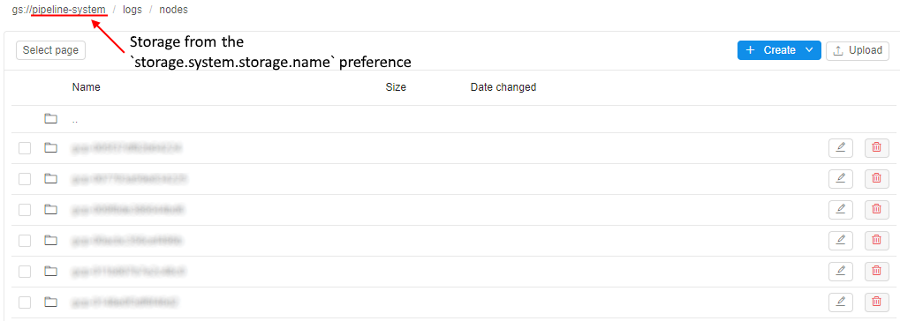
- Click the "breadcrumbs" control at the upper side of the page, enter
/into the end of the path and after it paste the hostname value, copied at step 2:
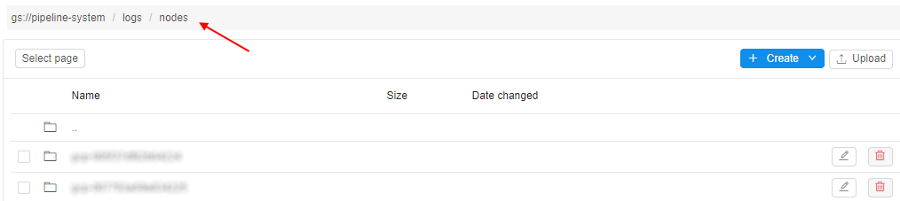
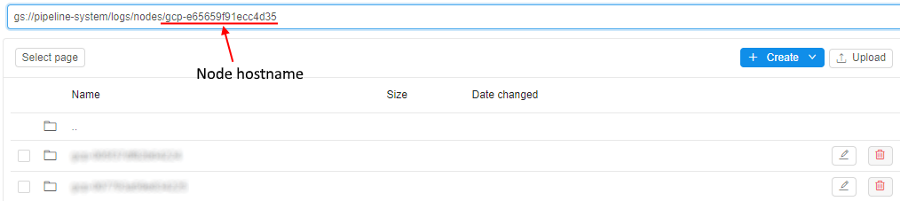
Press the Enter key. - The folder with
kubeletlogs for the specified node will be opened:

You can open it and see the list of logs files, divided by the messages type:
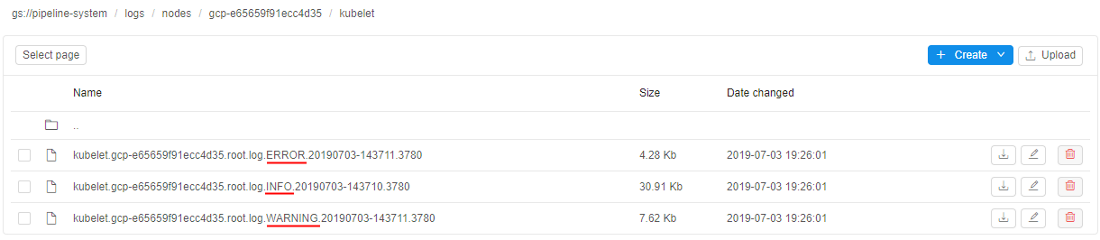
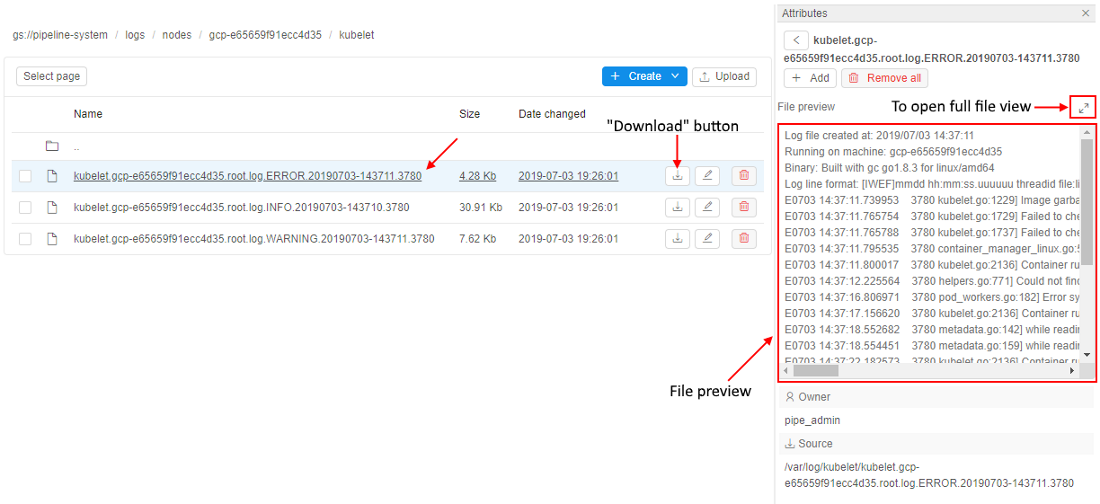
You can view any of these files using Cloud Pipeline facilities or download them to your local machine:
Controls
Note: Completed and active runs have different controls.
Example: controls of running Spot pipeline:
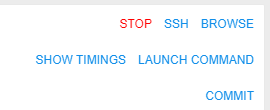
Here's the list of all existing buttons
| Control | Description |
|---|---|
| BROWSE | Allows to open the run instance filesystem in a Storage browser Web GUI - so the user can view, download, upload, delete files and directories for the current active run. |
| COMMIT | Allows modifying an existing tool that has been changed via ssh. See 10.4. Edit a Tool. |
| EXPORT LOGS | Allows to export logs. |
| GRAPH VIEW | For Luigi and WDL pipelines GRAPH VIEW is available along with a usual plain view of tasks. See 6.1.1. Building WDL pipeline with graphical PipelineBuilder. |
| LAUNCH COMMAND | Allows to generate the CLI pipe run command/API POST request for a job launch. |
| PAUSE | Allows to pause a run (only for On-demand non-cluster runs). |
| RERUN | Allows to rerun completed runs. |
| RESUME | Allows to resume a paused run (only for On-demand non-cluster runs). |
| SHOW TIMINGS/HIDE TIMINGS | Allows to show/hide duration of each task. |
| SSH | Allows to shh to the instance running "sleep infinity" mode. See 6.1. Create and configure pipeline. |
| STOP | Allows to stop a run. |
| TERMINATE | Allows to terminate compute node of a paused run without resuming (only for On-demand non-cluster runs). |
Automatically rerun if a spot instance is terminated
In certain cases - Cloud Provider may terminate a node, that is used to run a job or an interactive tool. It may be in cases:
- Spot prices changed
- Cloud Provider experienced a hardware issue
These cases aren't a Cloud Platform bug. In these cases:
- If a job fails due to server-related issue, special message is displayed, describing a reason for the hardware failure:

-
If a batch job fails due to server-related issue and Cloud Provider reports one of the following instance status codes:
- Server.SpotInstanceShutdown - a spot instance was stopped due to price changes,
- Server.SpotInstanceTermination - a spot instance was terminated due to price changes,
- Server.InternalError - Cloud Provider hardware issue,
batch job will be restarted from scratch automatically.
Note: this behavior will occur, only if administrator applied and configured it (for more information see 12.10. Manage system-level settings).